





Python 作为高级语言的一种,
不可避免的会接触到各种各样的编码。
为了编码因为编码产生的问题。
最好对自己的源码处理数据的类型固定下来,
这样才能避免产生一些问题。
下面就介绍一下python 的源码如何进行统一编码。
工具/原料
python
代码内声明编码格式
1
编码格式1:
在源文件第一行或者第二行定义:
# coding=
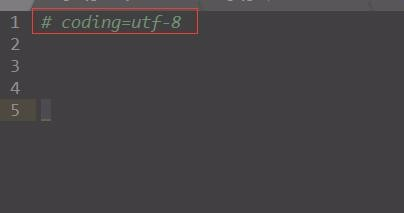
例如:
# coding=utf-8
2
编码格式2:(这种最流行)
格式如下:
#!/usr/bin/python
# -*- coding: -*-
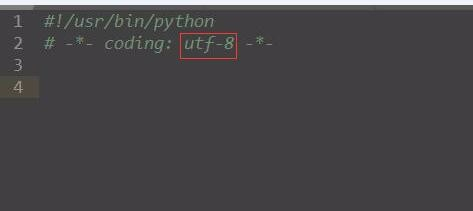
例如:
#!/usr/bin/python
# -*- coding: utf-8 -*-
3
编码格式3:(如果使用了vim)
#!/usr/bin/python
# vim: set fileencoding= :
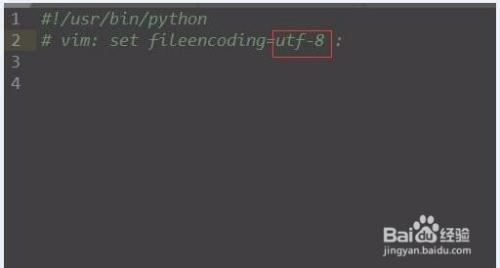
例如
#!/usr/bin/python
# vim: set fileencoding=utf-8 :
4
如果想表达的更精确,
只要定义的表达式在第一行或者第二行,
符合正则表达式:^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
即可。
表达式解析coding的名称后,
如果python 不识别,就会报错。
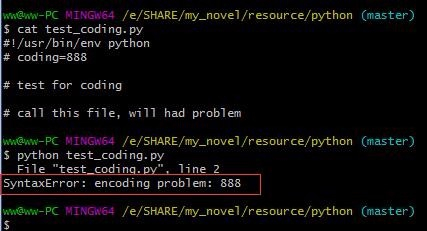
END
一些特殊的点
1
第一行和第二行重复定义时。
第一行生效,
第二行不会生效的。
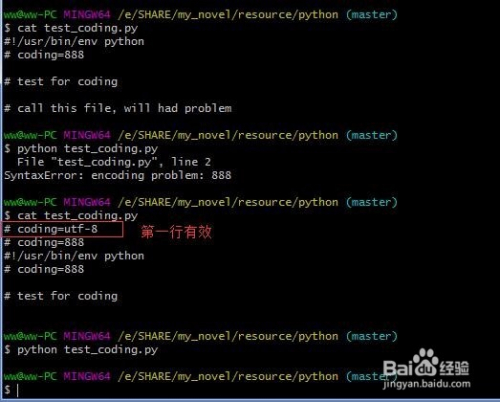
2
utf8和utf-8是一种编码格式,
在python 里都认为是一种编码格式utf-8。
如图。
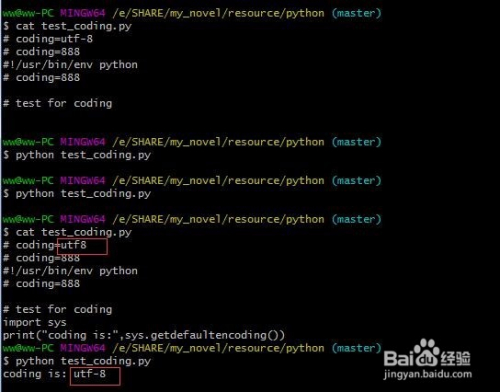
END
格式无法生效
1
没有“coding”前缀。
无法生效。
如图
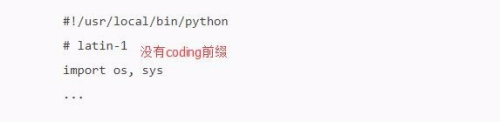
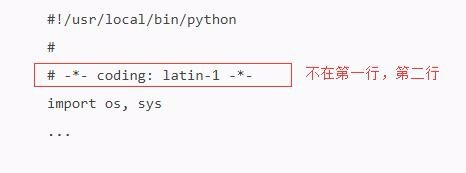
2
不在第一行第二行。
无法生效。
如图
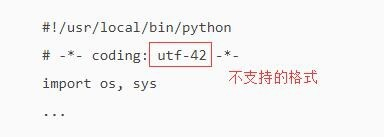
3
不支持的格式类型
无法生效。
例如:
utf-42
END
注意事项
更详细的内容请看PEP 263
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。
举报作者声明:本篇经验系本人依照真实经历原创,未经许可,谢绝转载。
展开阅读全部















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









