






基本上是copy
安夏木:数据分析方法—决策树分类算法及实现(2)zhuanlan.zhihu.com

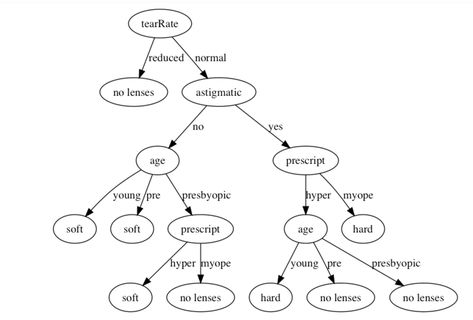
ID3算法思想:
ID3使用信息增益作为特征选择的度量,使用自顶向下的贪心算法遍历决策树空间。具体的:
1. 计算数据集合的信息熵,以及各个特征的条件熵。选择信息增益最大的作为本次划分节点。
2. 删除上一步使用的特征,更新各个分支的数据集和特征集。
3. 重复1,2步,知道子集包含单一特征,则为分支叶结点。
信息熵越大,意味着信息越是无序。
信息增益越大,那么就是指分完之后的信息熵越小,那也就意味着分完之后的数据趋向于有序,
而越有序的数据,意味着我们能更好地预测数据。
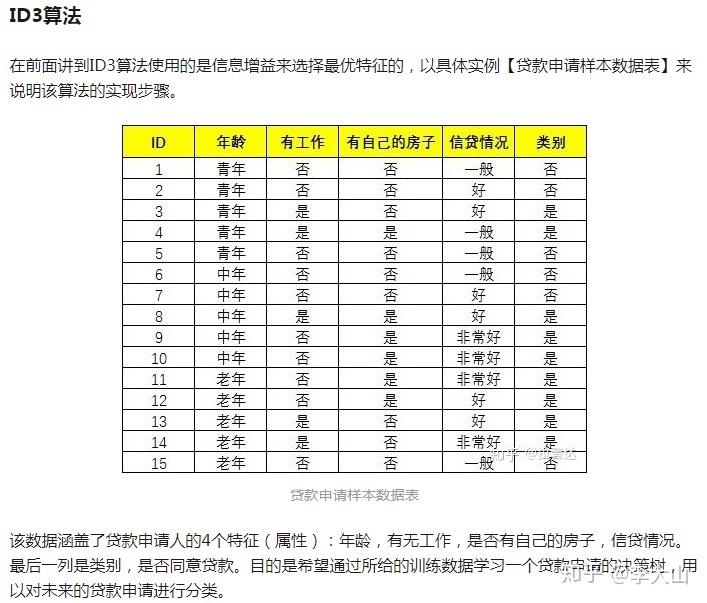




C4.5算法
C4.5主要是克服ID3使用信息增益进行特征划分对取值数据较多特征有偏好的缺点。
使用信息增益率进行特征划分。
C4.5相比ID3进行的改进有如下4点:
1. 引入剪枝策略,使用悲观剪枝策略进行后剪枝
2. 使用信息增益率代替信息增益,作为特征划分标准
3. 连续特征离散化
需要处理的样本或样本子集按照连续变量的大小从小到大进行排序
4. 缺失值处理
对于具有缺失值的特征,用没有缺失的样本子集所占比重来折算信息增益率,选择划分特征
选定该划分特征,对于缺失该特征值的样本,将样本以不同的概率划分到不同子节点
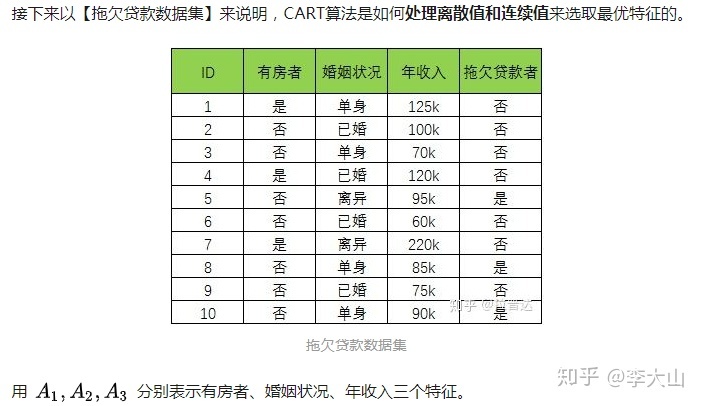
CART算法思想, CART树在C4.5基础上进行了如下改进:
1. CART使用二叉树来代替C4.5的多叉树,提高了生成决策树效率
2. C4.5只能用于分类,CART树可用于分类和回归
3. CART 使用 Gini 系数作为变量的不纯度量,减少了大量的对数运算
4. CART 采用代理测试来估计缺失值,而 C4.5 以不同概率划分到不同节点中
5. CART 采用“基于代价复杂度剪枝”方法进行剪枝,而 C4.5 采用悲观剪枝方法
6. ID3 和 C4.5 层级之间只使用一次特征,CART 可多次重复使用特征


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









