





在网上查了好久,自己写一个吧。

课本上说协方差阵对角线上是各个变量的方差,然而在numpy中通过np.cov(X)得到的协方差矩阵,其对角线线上的值不是np.var()计算出来的值。根本原因在于,np.cov(X)是在数理统计背景下计算的,得到的方差是样本方差,而不是平常意义下的方差。
嗯,不准确的讲,均值、方差、协方差。在数理统计中,除了均值的计算方式不变之外,其余的两个都是除以
两个随机变量
样本均值的定义及python实现
数学定义:
python代码:用np.mean()函数来实现。
笔算结果:
python代码实现结果
#python代码
x1=np.array([1,3])
x2=np.array([2,4])
np.mean(x1)
#Out[62]: 2.0
np.mean(x2)
#Out[63]: 3.0样本方差的定义及python实现
数学定义:
python代码:用np.cov()函数来实现。
笔算结果:
python代码实现结果
np.cov(x1)
#Out[64]: array(2.)
#np.cov(x2)
Out[65]: array(2.)方差的定义及python实现
数学定义:
python代码:用np.var()函数来实现。
笔算结果:
python代码实现结果
np.var(x1)
#Out[67]: 1.0
np.var(x2)
#Out[68]: 1.0
小结:其实给出一组数
在接触到样本与总体的概念之后,才发现平均值有了另外一个定义,叫做样本均值,从其蕴含的统计学意义上来讲是不一样的,但是它们俩形式上一样,计算公式也一样,可以认为
从而在开发代码语言时也就不用开发两个函数了(个人理解,查了好久,都是用的np.mean()计算的均值,当然list也有自己的函数,不过结果都是一样,如果实在理解不了,就把numpy的这个函数阿看作为统计学上的样本均值开发的函数吧,把list的函数看作日常理解的那个平均值)。
之后由于无偏估计和有偏估计的概念,才有了样本方差这个定义的出现,大致原因是:采用日常理解的方差形式
之所以写这么多是为了铺垫协方差矩阵的问题。
这个函数必须输入一个参数,其余的都有默认值。嗯,用python还是得看源码啊。
np.cov(x)#x是一个向量是输出样本方差
a = np.array([[1, 2], [3, 4]])
#转置是因为函数把矩阵的行看作我们所熟悉的随机变量,也就是特征,把列看作观测得到的值
#会输出一个协方差矩阵
np.cov(a.T)源码如下:
def cov(m, y=None, rowvar=True, bias=False, ddof=None, fweights=None,
aweights=None):
"""
Estimate a covariance matrix, given data and weights.
Covariance indicates the level to which two variables vary together.
If we examine N-dimensional samples, :math:`X = [x_1, x_2, ... x_N]^T`,
then the covariance matrix element :math:`C_{ij}` is the covariance of
:math:`x_i` and :math:`x_j`. The element :math:`C_{ii}` is the variance
of :math:`x_i`.
See the notes for an outline of the algorithm.
Parameters
----------
m : array_like
A 1-D or 2-D array containing multiple variables and observations.
Each row of `m` represents a variable, and each column a single
observation of all those variables. Also see `rowvar` below.样本数据的协方差矩阵是下面这个图
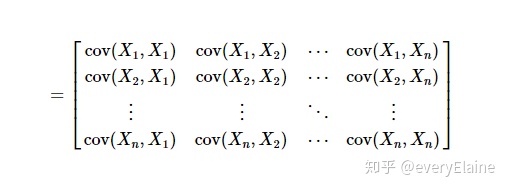
上面的矩阵每一个元素的定义如下
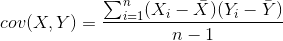














 3250
3250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









