







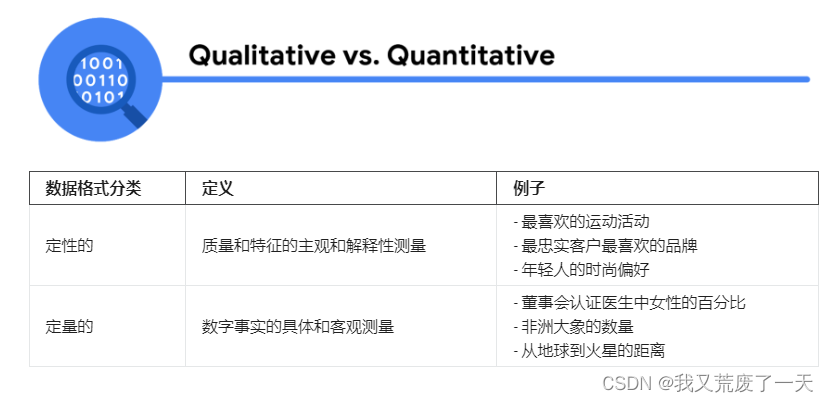
1.实践中的数据格式





2.数据结构
数据无处不在,并且可以以多种方式存储。两大类数据是:
- 结构化数据:以某种格式组织,例如行和列。
- 非结构化数据:没有以任何易于识别的方式组织。
例如,当您在线评价您最喜欢的餐厅时,您正在创建结构化数据。但是,当您使用 Google 地球查看餐厅位置的卫星图像时,您使用的是非结构化数据。
以下是结构化和非结构化数据特征的复习:
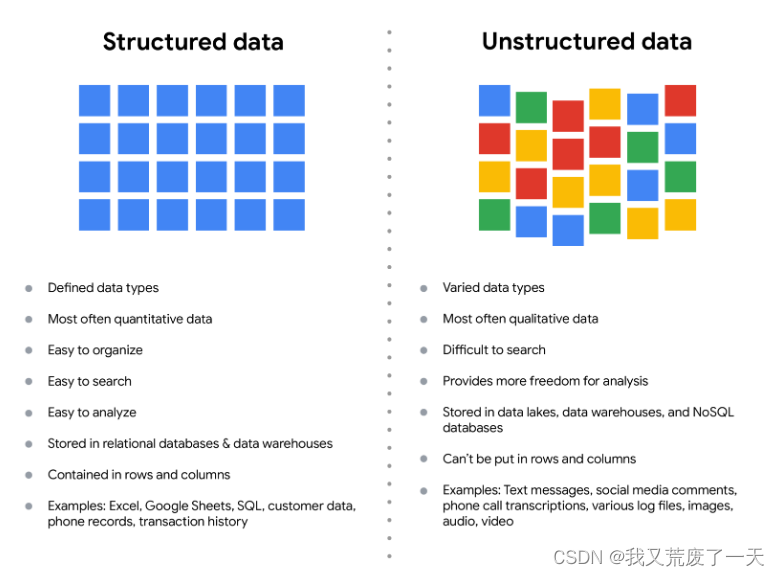
结构化数据
如前所述,结构化数据以某种格式组织。这使得存储和查询业务需求变得更加容易。如果数据被导出,则结构与数据一起出现。
非结构化数据
非结构化数据无法以任何易于识别的方式进行组织。世界上的非结构化数据比结构化数据多得多。视频和音频文件、文本文件、社交媒体内容、卫星图像、演示文稿、PDF 文件、开放式调查回复和网站都属于非结构化数据类型。
公平问题
缺乏结构使得非结构化数据难以搜索、管理和分析。但最近人工智能和机器学习算法的进步开始改变这一点。现在,数据科学家面临的新挑战是确保这些工具具有包容性和公正性。否则,数据集的某些元素将比其他元素更重要和/或表示。在您学习的过程中,不公平的数据集并不能准确地代表总体,从而导致结果偏差、准确度水平低和分析不可靠。
3.数据建模级别和技术
3.1什么是数据建模?
数据建模是创建图表的过程,该图表直观地表示数据的组织和结构。这些可视化表示称为数据模型。您可以将数据建模视为房屋的蓝图。在任何时候,都可能有电工、木匠和管道工使用该蓝图。这些建造者中的每一个都与蓝图有不同的关系,但他们都需要它来了解房子的整体结构。数据模型类似;不同的用户可能有不同的数据需求,但数据模型让他们对整个结构有一个整体的理解。
3.2数据建模的级别
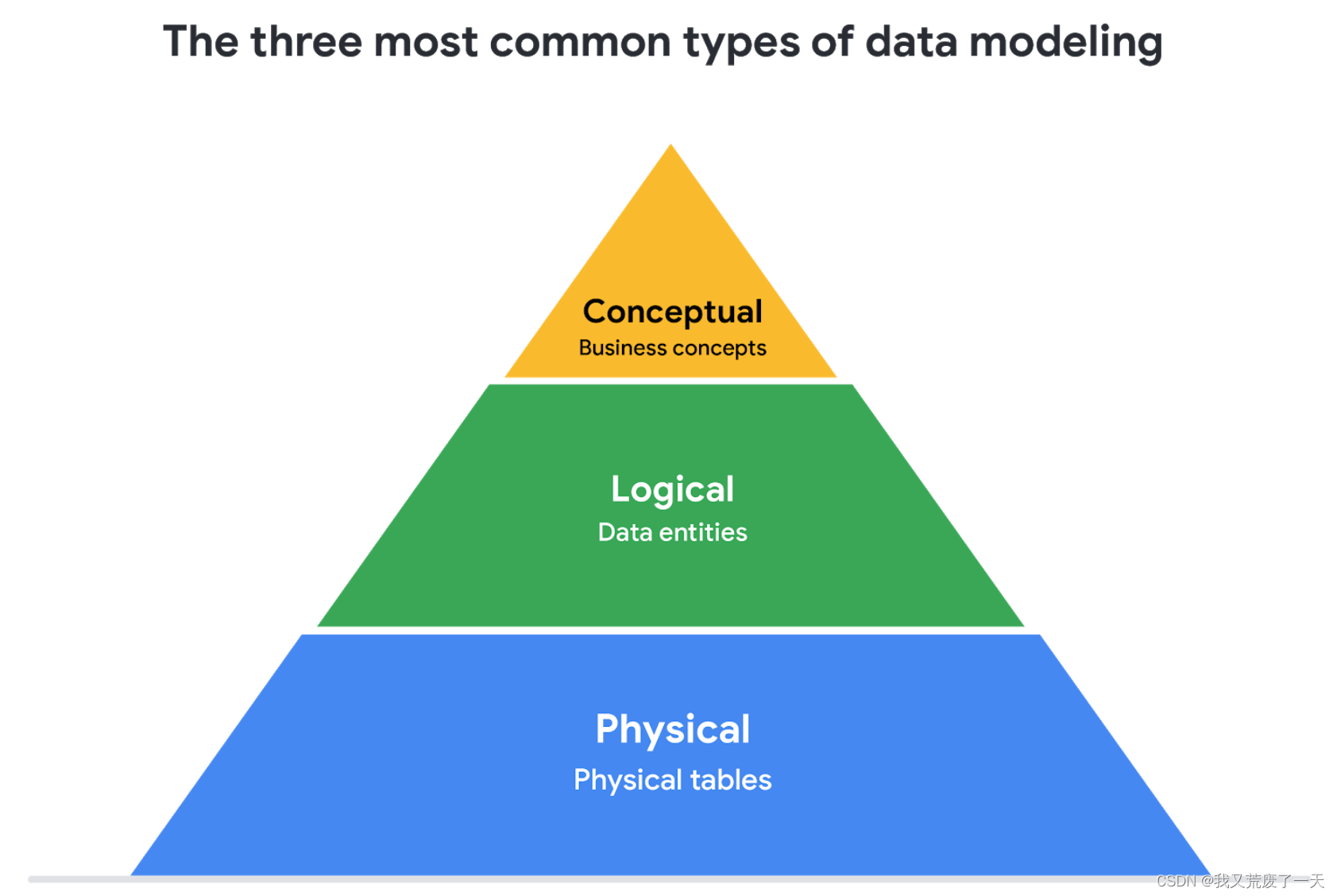
- 概念数据建模提供了数据结构的高级视图,例如数据如何在组织中交互。例如,可以使用概念数据模型来定义新数据库的业务需求。概念数据模型不包含技术细节。
- 逻辑数据建模侧重于数据库的技术细节,例如关系、属性和实体。例如,逻辑数据模型定义了如何在数据库中唯一标识各个记录。但它没有拼出数据库表的实际名称。这就是物理数据模型的工作。
- 物理数据建模描述了数据库的运行方式。物理数据模型定义了所有使用的实体和属性;例如,它包括数据库的表名、列名和数据类型。
3.3数据建模技术
开发数据模型有很多方法,但两种常用方法是实体关系图 (ERD)和统一建模语言 (UML)图。ERD 是一种直观的方式来理解数据模型中实体之间的关系。UML 图是非常详细的图,通过显示系统的实体、属性、操作及其关系来描述系统的结构。作为初级数据分析师,您需要了解有不同的数据建模技术,但在实践中,您可能会使用组织现有的技术。
您可以在这篇数据建模技术文章中阅读有关 ERD、UML 和数据字典的更多信息。
3.4数据分析和数据建模
数据建模可以帮助您探索数据的高级细节以及它在组织信息系统中的关联方式。数据建模有时需要数据分析来了解数据是如何组合在一起的;这样,您就知道如何映射数据。最后,数据模型使组织中的每个人都可以更轻松地理解数据并与您协作处理数据。这对您和您团队中的每个人都很重要!
4.数据类型

Boolean布尔数据类型是一种只有两种可能值的数据类型:真或假。
4.数据中的偏差
四种类型的数据偏差
- 抽样偏见
抽样偏见是指一个样本不能代表整个人口的情况。例如,如果你在做关于上班族的研究,而只调查在人行道上走过的人,你会错过骑自行车、开车或坐地铁的人的意见。你需要所有方面的信息来避免抽样偏见。 - 观察者偏差
它有时被称为实验者偏差或研究偏差。基本上,它是不同的人以不同方式观察事物的倾向。你可能记得早些时候,我们了解到科学家在他们的工作中经常使用观察,比如当他们在显微镜下观察细菌以收集数据。虽然两个科学家在同一个显微镜下观察可能会看到不同的东西,但这就是观察者偏差。另一个可能发生观察者偏差的时候是在手动血压读数时。因为血压计非常敏感,医护人员经常得到相当不同的结果。通常情况下,他们只是四舍五入到最接近的整数,以补偿误差的幅度。但是,如果医生总是把病人的血压读数四舍五入,那么健康状况可能会被遗漏,任何涉及病人的研究都不会有精确和准确的数据。 - 解释偏差
倾向于总是以积极或消极的方式解释模棱两可的情况。这里有一个例子。假设你正在和一个同事吃午饭,这时你收到了你老板的语音邮件,让你给她回电话。你气急败坏地放下电话,确信她在生气,而你正在为某件事情发火。但当你为你的朋友播放这条信息时,他根本没有听到愤怒的声音,他实际上认为她听起来很平静,很直率。解释偏见,可以导致两个人看到或听到完全相同的事情,并以各种不同的方式解释它,因为他们有不同的背景和经验。你和你老板的历史使你以一种方式解释这个电话,而你的朋友却以另一种方式解释,因为他们是陌生人。把这些解释加入到数据分析中,你就会得到有偏见的结果。 - 确认偏差
最后一种偏见,让我想起了一句话:人们看到他们想看到的东西。这几乎概括了确认性偏见的内容。确认性偏见,是指以证实已有信念的方式搜索或解释信息的倾向。有人可能非常渴望确认一种直觉,以至于他们只注意到支持这种直觉的事情,而忽略了所有其他信号。这种情况在日常生活中经常发生。我们可能从某个网站获取新闻,因为作者与我们的信念相同,或者我们与人交往,因为我们知道他们持有类似的观点。
5.数据的好坏

我们发现,如果数据集是可靠的、原始的、全面的、最新的和被引用的,它就能ROCCC(或者更严肃地说:它很好)。
5.1好数据
当你选择一个数据源时,要考虑三件事。
- 谁创建了这个数据集?
- 它是一个可信的组织的一部分吗?
- 数据最后一次被刷新是什么时候?
如果你有来自可靠组织的原始数据,并且它是全面的、最新的和被引用的,那么它就是好的数据。
6.数据隐私和伦理
6.1数据伦理

- 所有权
首先是所有权。这回答了谁拥有数据的问题?不是投入时间和金钱收集、存储、处理和分析的组织。是个人拥有他们提供的原始数据,他们对数据的使用、如何处理以及如何共享有主要的控制权。 - 交易透明度
交易透明度,即所有的数据处理活动和算法都应该是完全可以解释的,并由提供其数据的个人理解。这是为了回应对数据偏见的担忧,我们在前面讨论过,这是一种错误,系统地将结果向某个方向倾斜。有偏见的结果会导致负面的后果。为了避免它们,特别是向分享数据的人提供透明的分析是有帮助的。这让人们判断结果是否公平公正,并允许他们提出潜在的担忧。 - 同意
现在我们来谈谈数据伦理的另一个方面,即同意。这是个人的权利,在同意提供数据之前,他们有权知道关于如何和为什么使用他们的数据的明确细节。他们应该知道一些问题的答案,比如为什么要收集数据?它将如何被使用?它将被储存多长时间?给予同意的最佳方式可能是提供数据的人和要求数据的人之间的对话。但是,由于现在网上发生了这么多活动,同意通常只是看起来像一个条款和条件的复选框,并有更多的细节链接。让我们面对现实吧,不是每个人都会点击阅读这些细节。同意是很重要的,因为它可以防止所有人群被不公平地盯上,这对边缘化群体来说是非常重要的,他们经常被有偏见的数据不相称地扭曲。 - 货币
个人应该了解因使用其个人数据而产生的金融交易以及这些交易的规模。如果你的数据正在帮助资助一家公司的工作,你应该知道这些工作是怎么回事,并有机会选择退出。 - 隐私
在谈论数据时,隐私意味着在数据交易发生的任何时候都要保护数据主体的信息和活动。这有时被称为信息隐私或数据保护。这都是关于数据的访问、使用和收集。它还包括一个人对其数据的合法权利。这意味着像你或我这样的人应该有保护措施,防止未经授权访问我们的私人数据,免于不适当地使用我们的数据,有权检查、更新或纠正我们的数据,能够同意使用我们的数据,以及访问我们的数据的合法权利。对于公司来说,这意味着要将隐私措施落实到位,以保护个人的数据。数据隐私很重要,即使你不是一个每天都在考虑这个问题的人。数据隐私的重要性已经被世界各国政府所认识,他们已经开始创建数据保护立法,以帮助保护人们和他们的数据。能够用你的数据信任公司是很重要的。它使人们愿意使用一个公司的产品,分享他们的信息,以及更多。信任是一个非常大的责任,不能掉以轻心。涉及数据道德的最后一个方面是一个不断被讨论的问题。数据的开放性、自由访问、使用和共享的想法。 - 开放性
当提到数据时,开放性是指对数据的自由访问、使用和共享。有时我们把这称为开放数据,但这并不意味着我们忽略了我们所涉及的数据伦理的其他方面。我们仍然应该保持透明,尊重隐私,并确保我们对他人拥有的数据的同意。这只是意味着如果数据符合这些高标准,我们就可以访问、使用和分享这些数据。例如,有围绕可用性和访问的标准。开放数据必须是一个整体,最好是通过互联网下载,以方便和可修改的形式提供。data.gov网站就是一个很好的例子。你可以以简单的文件格式(如电子表格)下载各行各业的科学和研究数据。另一个标准是围绕再利用和再分配。开放数据必须在允许再利用和再分配的条件下提供,包括与其他数据集一起使用的能力。最后一个领域是普遍参与。每个人都必须能够使用、重新使用和重新发布数据。不应该有任何对领域、个人或团体的歧视。没有人可以对数据进行限制,比如说让它只能在特定行业中使用。
什么是开放数据
在数据分析中,开放数据是数据伦理的一部分,这与合乎道德地使用数据有关。开放性是指数据的免费访问、使用和共享。但要使数据被认为是开放的,它必须:
-
作为一个完整的数据集可供公众使用和访问
-
根据允许重复使用和重新分发的条款提供
-
允许普遍参与,以便任何人都可以使用、重用和重新分发数据
只有满足所有这三个标准时,数据才能被认为是开放的。
开放数据的站点和资源
对于数据分析师来说幸运的是,有许多值得信赖的网站和资源可用于开放数据。重要的是要记住,即使是信誉良好的数据也需要不断评估,但这些网站是一个有用的起点:
-
美国政府数据网站:Data.gov 是美国最全面的数据源之一。该资源为用户提供进行研究所需的数据和工具,甚至帮助他们开发 Web 和移动应用程序以及设计数据可视化。
-
美国人口普查局:这个开放数据源提供来自美国联邦、州和地方政府以及商业实体的人口统计信息。
-
开放数据网络:这个数据源有一个非常强大的搜索引擎和高级过滤器。在这里,您可以找到有关金融、公共安全、基础设施以及住房和发展等主题的数据。
-
Google Cloud Public Datasets:您可以通过 Google Cloud Public Dataset Program 找到已加载到 BigQuery 中的一系列公共数据集。
-
数据集搜索:数据集搜索是专门为数据集设计的搜索引擎;您可以使用它来搜索特定的数据集。
6.2数据匿名化
什么是数据匿名化?
常见操作:Masking和Blanking
您一直在了解隐私在数据分析中的重要性。现在,是时候讨论数据匿名化以及应该对哪些类型的数据进行匿名化了。 个人身份信息( PII ) 是可以单独使用或与其他数据一起用于追踪个人身份的信息。
数据匿名化是通过消除此类信息来保护人们的私人或敏感数据的过程。通常,数据匿名化涉及消隐、散列或屏蔽个人信息,通常使用固定长度的代码来表示数据列,或隐藏具有更改值的数据。
您在数据匿名化中的角色
组织有责任保护他们的数据和数据可能包含的个人信息。作为数据分析师,您可能需要了解哪些数据需要匿名化,但您通常不对数据匿名化本身负责。如果您出于测试或开发目的使用数据副本,则可能是一个罕见的例外。在这种情况下,您可能需要在使用数据之前对其进行匿名化处理。
哪些类型的数据应该匿名?
医疗保健和财务数据是两种最敏感的数据类型。这些行业非常依赖数据匿名化技术。毕竟,赌注非常高。这就是为什么这两个行业的数据通常会经过去识别化,这是一个用于清除所有个人识别信息的数据的过程。
几乎每个行业都使用数据匿名化。这就是为什么数据分析师了解基础知识如此重要的原因。以下是经常匿名的数据列表:
- 电话号码
- 名称
- 牌照和牌照号码
- 社会安全号码
- IP 地址
- 病历
- 电子邮件地址
- 照片
- 帐号
对于某些人来说,这种类型的数据应该匿名是有道理的。对于其他人,我们必须非常具体地说明需要匿名的内容。想象一个我们都可以访问彼此的地址、帐号和其他可识别信息的世界。那会侵犯很多人的隐私,让世界变得不那么安全。数据匿名化是我们保持数据私密和安全的方法之一!
7.数据库

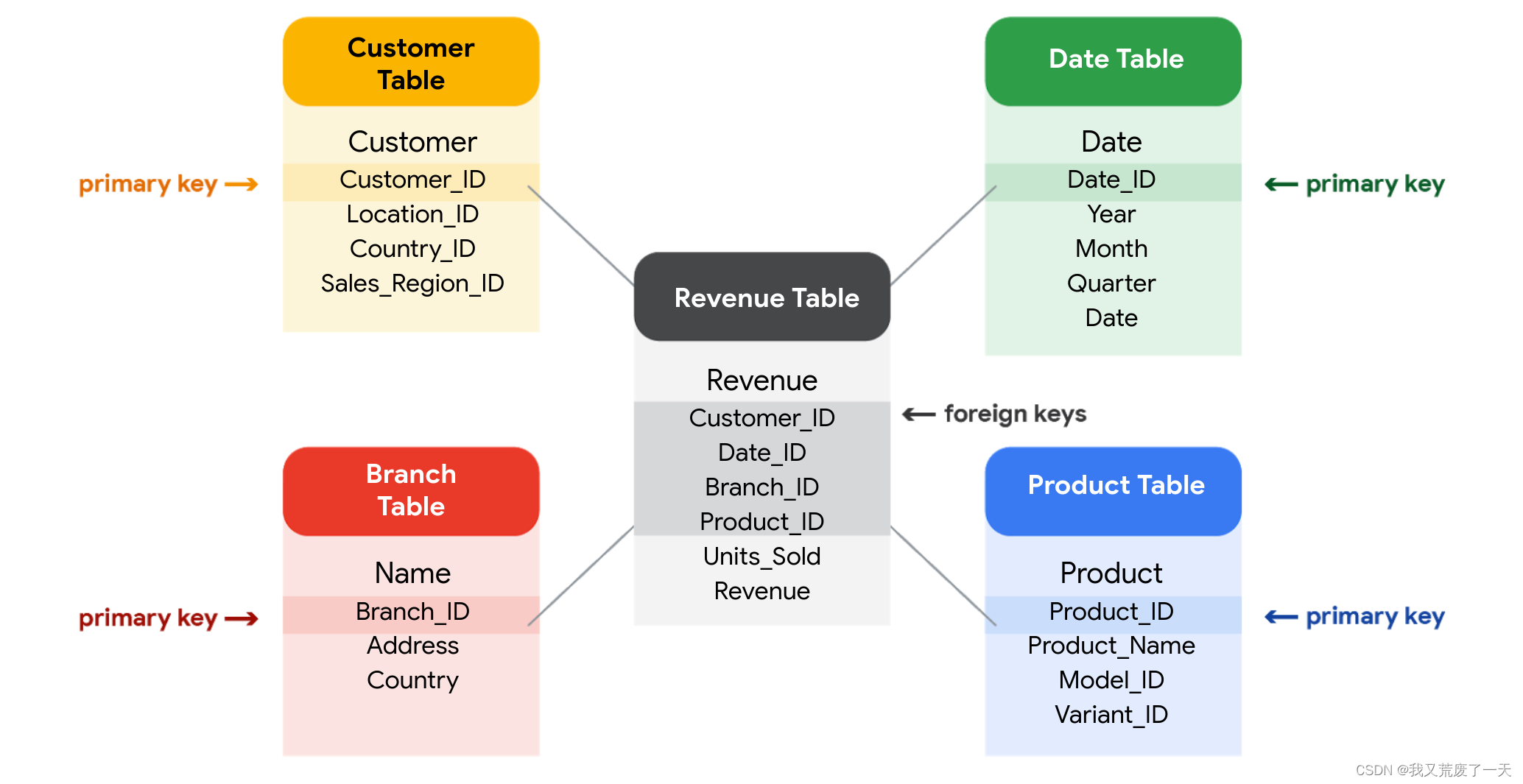
Primary key是一个标识符,它引用一个列,其中每个值都是唯一的。换句话说,它是表的一列,用于唯一标识该表中的每条记录。分配给特定行中主键的值在整个表中必须是唯一的。例如,如果 customer_id 是 customer 表的主键,则不会有两个客户拥有相同的 customer_id。 
Foreign key是一个表中的一个字段,它是另一个表中的主键。一张表只能有一个主键,但可以有多个外键。这些键创建了关系数据库中表之间的关系,这有助于跨数据库中的多个表组织和连接数据。
有些表不需要主键。例如,一个收入表可以有多个外键,但没有主键。也可以使用表的多个列来构造主键。这种类型的主键称为复合键。例如,如果 customer_id 和 location_id 是客户表的复合键的两列,则分配给任何给定行中这些字段的值在整个表中必须是唯一的。
8.元数据Metadata
作为一个数据分析师,你会遇到三种常见的元数据类型:
- 描述性
描述性元数据是描述一块数据的元数据,可以用来在以后的时间点上识别它。例如,图书馆里一本书的描述性元数据包括你在书脊上看到的代码,也就是唯一的国际标准书号,也叫ISBN。它还会包括这本书的作者和书名。 - 结构性
结构性元数据,它是表明一块数据是如何组织的,以及它是否是一个或多个数据集合的一部分的元数据。让我们回到图书馆。结构性数据的一个例子是一本书的页面是如何被放在一起以创建不同的章节的。值得注意的是,结构性元数据还可以跟踪两件事情之间的关系。例如,它可以告诉我们,一本书稿的数字文档实际上是现在印刷书的原始版本。 - 管理性
管理元数据是表明数字资产的技术来源的元数据。当我们看了照片里面的元数据,那就是管理元数据。它向你显示了它的文件类型,拍摄日期和时间,以及更多。
元数据的元素
在查看元数据示例之前,了解元数据通常提供的信息类型非常重要。
-
标题和描述
您正在检查的文件或网站的名称是什么?它包含什么类型的内容? -
标签和类别
您拥有的数据的总体概述是什么?数据是否以特定方式编入索引或描述? -
谁创造了它,什么时候创造的
数据从何而来,何时创建?它是最近的,还是已经存在了很长时间? -
谁最后修改它以及何时
是否对数据进行了任何更改?如果是,这些修改是最近的吗? -
谁可以访问或更新它
这个数据集是公开的吗?自定义或修改数据集是否需要特殊权限?
元数据示例
在当今的数字世界中,元数据无处不在,在您与之交互的大量媒体和信息上提供元数据正成为一种更普遍的做法。以下是一些在哪里可以找到元数据的真实示例:
-
相片
每当使用相机拍摄照片时,都会收集并保存相机文件名、日期、时间和地理位置等元数据。 -
电子邮件
发送或接收电子邮件时,有许多可见的元数据,例如主题行、发件人、收件人以及发送的日期和时间。还有隐藏的元数据,包括服务器名称、IP 地址、HTML 格式和软件详细信息。 -
电子表格和文档
电子表格和文档已经填充了大量数据,因此元数据也会伴随它们也就不足为奇了。标题、作者、创建日期、页数、用户评论以及选项卡、表格和列的名称都是可以在电子表格和文档中找到的元数据。 -
网站
每个网页都有许多标准元数据字段,例如标签和类别、网站创建者的姓名、网页标题和描述、创建时间和任何图标。 -
数字文件
通常,如果您右键单击任何计算机文件,您将看到其元数据。这可能包括文件名、文件大小、创建和修改日期以及文件类型。 -
图书
元数据不仅是数字的。每本书的封面和内部都有许多标准元数据,这些元数据会告诉您它的标题、作者姓名、目录、出版商信息、版权描述、索引和书籍内容的简要描述。
9.组织数据
在组织数据时,有很多最佳做法可以使用,包括
- 命名惯例
我们以前谈过文件的命名,这也被称为命名惯例。这些是一致的准则,在文件的名称中描述文件的内容、日期或版本。基本上,这意味着你要为你的文件使用有逻辑和描述性的名字,使它们更容易找到和使用。 - 折叠
说到容易找到的东西,将你的文件组织成文件夹有助于将项目相关的文件放在一个地方。这就是所谓的折叠。例如,所有与你的度假计划有关的文件都可以放在Vacation2025文件夹中。 - 归档旧文件
然后,你可以通过创建子文件夹(如行程表或照片)来进一步细分该文件夹,这取决于你还想轻松访问什么。将旧的项目移到一个单独的位置,建立一个档案,减少杂乱无章的情况,也是很有用的。当我给我的文件起一个有意义的、可搜索的名字,并把它们整理成文件夹时,寻找和使用这些文件就容易多了。它使我的所有数据更容易获得和使用。
除了这三个最佳做法之外,在组织工作用的数据时,还有两件事你要考虑。
- 首先,你将用于工作的项目数据可能会被多个人访问和使用。将你的命名和存储实践与你的团队保持一致以避免任何混淆是很重要的。你的团队可能也会制定元数据的做法,比如创建一个文件,概述项目命名惯例,以便于参考。我们将在后面更详细地谈及工作文件的命名惯例。
- 其次,你要考虑你有多频繁地复制数据并将其存储在不同的地方。最重要的是,因为如果数据被存储在很多不同的数据库或电子表格中,它可能会自相矛盾,导致以后的错误。另外在多个地方存储数据也会占用很多空间。关系型数据库可以帮助你避免数据的重复,更有效地存储数据。你可以根据你的项目,使用这些做法,以不同的方式组织数据。
9.1组织原则
文件命名约定的最佳实践
查看以下文件命名建议:
- 在项目的早期制定并同意文件命名约定,以避免一次又一次地重命名文件。
- 使您的文件命名与您的团队或公司现有的文件命名约定保持一致。
- 确保您的文件名有意义;考虑包括项目名称等信息以及任何其他有助于您快速识别(和使用)文件以用于正确目的的信息。
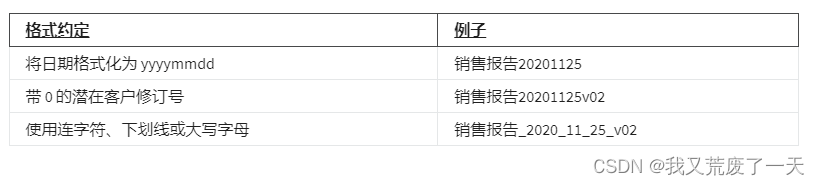
- 在文件名中包含日期和版本号;常见的格式是日期的 YYYYMMDD 和版本(或修订)的 v##。
- 创建一个文本文件作为示例文件,其内容描述(分解)文件命名约定和应用它的文件名。
- 避免在文件名中使用空格和特殊字符。而是使用破折号、下划线或大写字母。在某些应用程序中,空格和特殊字符可能会导致错误。
可以引用项目名称、创建日期、修订版本或任何其他需要了解该文件内容的有用信息。
首先,你要保持你的文件名称简短而温馨。它们应该是快速参考点,告诉你文件里有什么。
当你在文件名中包含修订号时,以零开头,这样如果你遇到两位数的修订号,就已经包含在你的惯例中了。
另一个好的规则是使用连字符、下划线或大写字母,而不是使用空格。空格和特殊字符可能不会被你的软件识别。另外,避免使用空格肯定会使在SQL中工作更容易。
我的最后一点建议:创建一个文本文件,列出你在一个项目上的所有命名惯例。如果有人新加入你的团队,或者你只是在工作中需要快速提醒的话,这真的很有帮助。
保持文件井井有条的最佳做法
请记住以下提示,以便在处理文件时保持井井有条:
- 在逻辑层次结构中创建文件夹和子文件夹,以便将相关文件存储在一起。
- 将正在进行的工作与已完成的工作分开,以便更容易找到您当前的项目文件。将旧文件存档在单独的文件夹或外部存储位置。
- 如果您的文件没有自动备份,请经常手动备份它们以避免丢失重要的工作。
10.平衡安全性和数据分析
-
加密使用一种独特的算法来更改数据,使其无法被不知道该算法的用户和应用程序使用。该算法被保存为“密钥”,可用于反向加密;因此,如果您有密钥,您仍然可以使用原始形式的数据。
-
令牌化用称为“令牌”的随机生成的数据替换您要保护的数据元素。原始数据存储在单独的位置并映射到令牌。要访问完整的原始数据,用户或应用程序需要具有使用令牌化数据和令牌映射的权限。这意味着即使标记化的数据被黑客入侵,原始数据在单独的位置仍然是安全的。
加密和令牌化只是现有的一些数据安全选项。还有很多其他的,比如将身份验证设备用于人工智能技术。















 2470
2470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









