






本文将介绍Fisher线性判别的原理和具体实践,阅读时间约8分钟,关注公众号可在后台领取数据集资源哦^-^


Fisher线性判别
1.背景介绍
生活中我们往往会遇到具有高维特性的数据,如个人信息,天气数据等。而在使用统计方法处理分类等模式识别问题时,通常是在低维空间展开研究的。而一般基于统计学习方法难以求解高维数据,所以降维成了解决问题的突破口。
对于高维空间样本,投影到一维坐标上,可能会出现样本特征混杂的现象,这将难以进行分类。如果寻找一个投影方向,使得样本集合在该投影方向最易区分,找寻这个最优方向的过程就是Fisher线性判别所解决的问题。
Fisher判别法的基本思想是将 类维数据集尽可能地投影到一条直线方向,使得类与类之间尽可能分开,再通过确定一个分类阈值来进行分类。
2.模型建立及求解方法
2.1基本参量
假设有个N1属于类的n维样本以及N2个属于类的n维样本,将两者合并成一个集合。经线性组合可得标量:
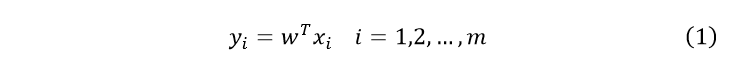
下面定义几个基本参量。在n维X空间中:
各类样本均值:
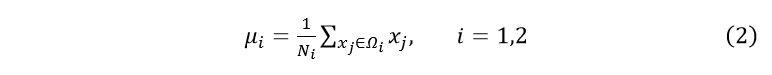
2.各类类内离散度矩阵:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









