





词性标注
简介
简单的说明一下什么是词性标注,词性(词类)是词汇中剧本的语法属性,而词性标注是在给定句子中判定每个词的语法范畴,确定它的词性并加以标注的过程。
比如给定句子“她很漂亮”,对应的词性标注结果就是“她/名词 很/副词 漂亮/形容词”,这就是一个简单的词性标注的例子。
但是在中文中有一些词语通常有多种词性,这就会对词性标注带来一些困难,解决该问题最简单的方法就是使用当前词语的高频词性来作为它的词性,虽然这样做的准确率是很高的但是它的提升空间依然很大,更好的解决办法就是像分词一样把该问题当做是一个序列问题来解决。
词性标注规范
这里列出北大的词性标注规范
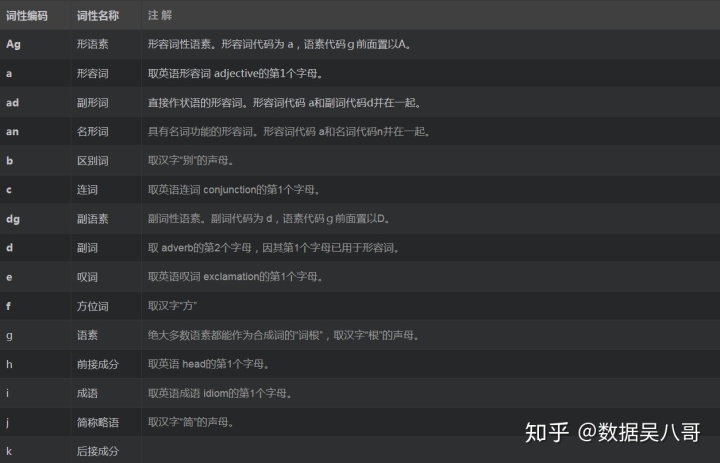


jieba词性标注实战
jieba是NLP中常用的中文分词库,这里讲解了它的原理以及使用方法——jieba分词
流程如下:
1、首先通过正则表达式来进行汉字的判断,表达式如下:

2、符合该表达式则判定为汉字,然后基于前缀词典来建立有向无环图,再基于有向无环图来计算最大概率路径,同时在前缀词典中找出它所分出的词性,若在词典中没有找到,则赋予词性为"un"(未知词性)。
在此过程中若使用HMM方式进行词性标注,且待标注词为未登录词(未登录词即没有被收录在分词词表中但必须切分出来的词,包括各类专有名词(人名、地名、企业名等)、缩写词、新增词汇等等),则会通过HMM的方式进行标注。
3、若不符合上面的正则表达式,那么将会继续通过正则表达式来判断,分别赋予:"un"(未知词性),"m"(数词),"eng"(英文)。
下面用jieba来实现一个词性标注的例子:
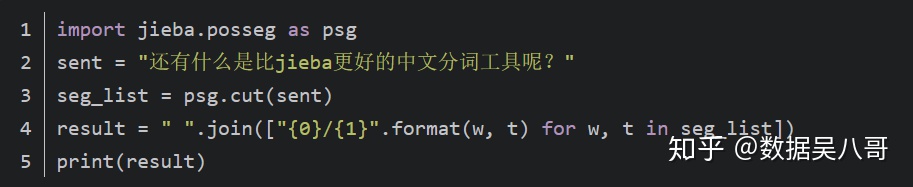
分词结果如下:
















 4093
4093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









