







在数据统计领域,去重/计数算法是一项经常使用的技术[1],例如 UV/PV 统计,日GMV统计都需要用到这项技术。
本章我们准备从业务演进的角度,来分析各类去重技术在实际生产场景的应用。这里我们以知乎网站为例,看看它发展历程中"可能"使用了哪些去重和计数算法,该过程中很多技术方案有更好的实践,但是为了更好的给大家讲解,只能假设B乎的技术较为拙劣了。
Redis/DB计数
2007年知乎网站建立,网站初始无论是QPS还是存储量都比较小。站长要求猿能实现文章点赞计数的功能,程序使用redis和DB就能对网站的数据进行累加计数。这时候千八百QPS,千万文章的量应该是毫无压力的。
BloomFilter去重
没一会儿点赞的功能开发好了, 然而由于没做用户防重,用户可以不断刷点赞,于是亿级点赞的文章汗牛充栋。美美与共的媛猿们想到学过的布隆过滤器,信手一试完成了功能。
BloomFilter 是一种非精确去重的算法,去重不能取消,占用空间较小,有可能出现误判。
算法原理是利用N个Hash函数和对应的N个K位的一维数组,对于新的元素,用N个Hash函数进行hash之后,获取其N个数组中的位置,如果N个数组中对应的位置都是1,那么说明该元素已经重复了。
BitMap / RoaringBitMap
然后布隆过滤器有着很大的问题, 用户点赞后无法取消点赞。另外布隆过滤器没有那么精确,导致了很多用户无法进行第一次点赞,引起了很多客诉。
百度一下,猿准备用BitMap进行存储点赞用户的id。然而对于一些点赞数目很少的文章,预存相当浪费空间。于是RoaringBitMap这样的根据元素数目来确定相应数据结构的结构就派上用场。
BitMap/ RoaringBitMap 是一种精确去重技术,消耗内存较少。
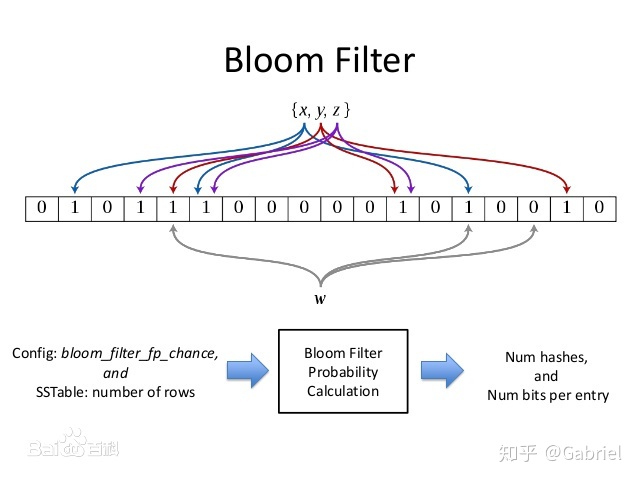
BitMap相对比较简单,这里着重讲下RoaringBitMap,RoaringBitMap技术实现分为两部分。
第一部分:差异化容器类型,前N位作为头,形成多个槽位,这样不同槽位就有不同的表达方式。
第二部分: 多种数据结构, 数据类型根据数据特征形成了以下几个特征:
ArrayContainer:
当数据量低于4096时,采用ArrayContainer存储,这个容器也比较简单,核心是一个short数组,我们知道short是2字节,因此存储的数字大小不能超过65536。将65536范围内的数字散布在4096个槽位里,因此这个数组里数组的分布是稀疏的。每次寻找数据也只需二分查找即可。
BitmapContainer
当存储的数据4096个数字后,RoaringBitmap采用Bitmap来存储所有的数字,包括之前那4096个数字。这一次的数量限制是2^16,也就是65536。这个数字很容易计算出,由于存储在container的数据只有32位中的低16位,因此作为Bitmap,只需要提供2^16个bit即可。
在这个容器中,核心是一个long数组,为了2^16个bit,这个数组分配了1024个空间,也是正好满足了2^16个bit。这里可以看出,BitmapContainer占用空间的上限也同样是8*1024=8KB,因此ArrayContainer的长度超过4096转换成BitmapContainer可以节省更多的空间,这也解释了为什么ArrayContainer的上限是4096了。
RunContainer
RunContainer是基于一种Run Length Encoding压缩算法的容器,其压缩原理是对于连续的数字只记录初始数字以及连续的长度,比如有一串数字 2,3,4,5,6 那么经过压缩后便只剩下2,5。从压缩原理我们也可以看出,这种算法对于数据的紧凑程度非常敏感,连续程度越高压缩率也越高。
字典树
然而产品的想法总是千变万化, 为了让互动率这个KPI变得更好看一些, 产品觉得每篇文章最多可以点赞3次。这样BitMap就用不了了。猿们需要通过能够精确计数的工具来便于对用户是否点过赞或者点赞几次进行判断。百度之后,于是从github上拉取了字典树的功能,成功的把开源的变成了自己的。虽然字典树在该场景并不完美,但是完成工作,进行无产阶级摸鱼再是最横的。
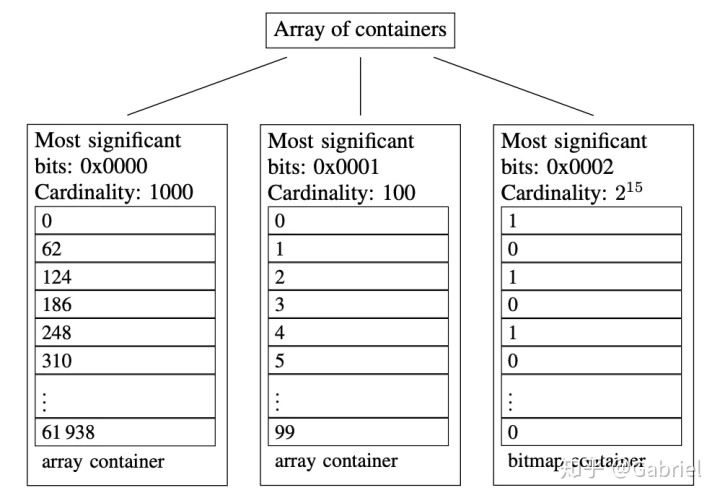
字典树是一种可计数的精确去重工具,实现原理相对简单。用中文解释原理可能比较容易点,班级有4个人,2个叫张伟,1个叫张伟达,1个叫张伟岸,构建出来的模型:
HyperLogLog
B乎一天天大了起来, 每天进行统计各类数据越来越,内存存储的支出也越来越大,再这样还怎么上市!在工头的压迫下,媛猿们百度到了hyperLogLog, 一项新的技术在公司的线上场景上得意洋洋的使用了起来。
HyperLogLog是一种基于概率算法的基数去重工具,数据量消耗极小,就是几bit的消耗量,在大数据量的情况下比较精确。其原理非常像生活中的幸存者效应或者冰山效应。举个例子你偶然看到某人扣脚一次,根据概率你可以判断此人抠脚次数达到过100次以上。
我们用实际的案例来解释其原理: 用户abcdef在HashA的hashCode是11001010, 这里方便理解我们按连续出现N次0的数量作为概率计算标志。 连续两次数字0, 1次数字1 [2],
(1/2 ✖️ 1/2 ✖️1/2 )至少有8次,我们计数为8。在HashB的hashCode是 11111101, 连续1次数字0, 一次数字1计数为(1/2 ✖️ 1/2 ) 至少4次。我们对这俩数做平均算法之后就是我们实际的统计基数6[3],正如实例描述在小数据量情况下不是十分精准。
参考
- ^去重往往可以计数,一些概率计数反而不能去重
- ^这边固定多计算一次1是为了调和,防止出现0概率出现
- ^这里为了简单描述用的算数平均,实际是调和平均















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









