







DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(3) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `test`.`t_user` (`id`, `name`, `age`) VALUES (1, 'aa', 12);
INSERT INTO `test`.`t_user` (`id`, `name`, `age`) VALUES (2, 'bb', 18);
INSERT INTO `test`.`t_user` (`id`, `name`, `age`) VALUES (3, 'cc', 22);
INSERT INTO `test`.`t_user` (`id`, `name`, `age`) VALUES (4, 'dd', 33);
INSERT INTO `test`.`t_user` (`id`, `name`, `age`) VALUES (5, 'aa', 12);
INSERT INTO `test`.`t_user` (`id`, `name`, `age`) VALUES (6, 'bb', 18);

#重复数据中ID小的假设是原始项,ID大的就是重复项
select * from t_user
where id in
(select min(id) minid from t_user
group by `name`, age
)
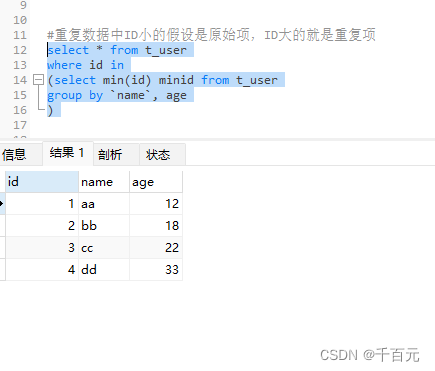
以name age分组查询,只保留最小的id,即不重的数据,再删除除最小id的其他数据
#删除重复的数据(ID最小的是要保留的数据,其他都是不要的)
delete from t_user
where id not in
(select min(id) minid from t_user
group by `name`, age
)
#查询出所有重复的数据(包含原始项和重复项)
select * from t_user a
right join
(select `name`, age from t_user
group by `name`, age
having count(*)>1) b
on a.`name`=b.`name`
and a.age=b.age 示例中 id为1,5 ; 2,6 重复
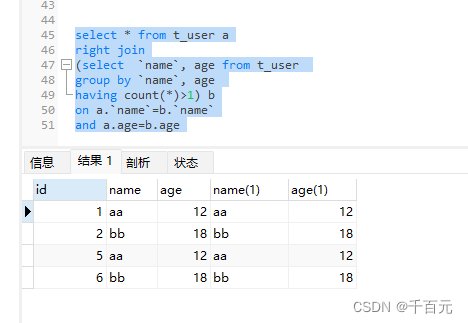
查询两列相同行数大于1的记录
#查询两列相同的个数
SELECT
`name`, age,
COUNT(*) AS count
FROM
t_user
GROUP BY
`name`, age
HAVING count > 1;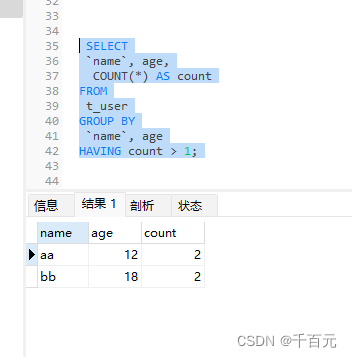















 3895
3895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









