









Improving Deep Neural Networks[1]
对吴恩达老师的《优化深度神经网络》课程作业知识进行总结。
文章目录
参数初始化 Initialization
首先,明确参数初始化的目的:
- 好的初始化策略能加快梯度下降的收敛速度;
- 能降低梯度下降收敛过程中出错的概率。
在本节,吴恩达主要介绍了三种初始化策略:
- 零初始化 Zeros initialization
- 随机初始化 Random initialization
- He初始化 He initialization
在神经网络中,需要初始化的参数有:
- 权重: ( W [ 1 ] , W [ 2 ] , W [ 3 ] , . . . , W [ L − 1 ] , W [ L ] ) (W^{[1]}, W^{[2]}, W^{[3]}, ..., W^{[L-1]}, W^{[L]}) (W[1],W[2],W[3],...,W[L−1],W[L])
- 偏移量: ( b [ 1 ] , b [ 2 ] , b [ 3 ] , . . . , b [ L − 1 ] , b [ L ] ) (b^{[1]}, b^{[2]}, b^{[3]}, ..., b^{[L-1]}, b^{[L]}) (b[1],b[2],b[3],...,b[L−1],b[L])
其中,每一个权重的维度都是[当前层的神经元数,前一层的神经元数],每一个偏移量都是标量。
1 零初始化 Zeros initialization
def initialize_parameters_zeros(layers_dims):
parameters = {}
L = len(layers_dims) # number of layers in the network
for l in range(1, L):
parameters['W'+str(l)] = np.zeros((layers_dims[l], layers_dims[l-1]))
parameters['b'+str(l)] = np.zeros((layers_dims[l], 1))
return parameters
在例程中,使用 np.zeros((dim_x, dim_y)) 初始化了参数。
然而,实验结果是出人意料的:
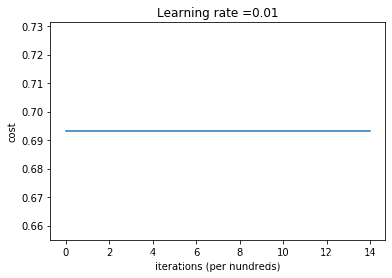
经过迭代没有任何变化。
原因分析:
初始化所有的权重为0,前向传播,因此Z1, Z2, … Zn都为0;
经过激活函数后值相同,A1 = A2 = … = An = g(Zi) = g(0).
反向传播,参数的梯度改变是一样的,所以新的参数相同。
因此,不管进行多少轮前向以及反向传播,每俩层之间的参数都是一样的。
没有打破对称性 Fail to break Symmetry
换句话说,本来我们希望不同的结点学习到不同的参数,但是由于参数相同以及输出值都一样,不同的结点根本无法学到不同的特征!这样就失去了网络学习特征的意义了。
隐藏层与其它层多个结点,其实仅仅相当于一个结点。
Ref: 为什么神经网络参数不能全部初始化为0?
2 随机初始化 Random initialization
在吴恩达老师的课程中,随机初始化可以将参数初始化为:
- 较大的参数
- 较小的参数
同时,提出了一个疑问:如果较大/较小的参数表现较好,那么需要设置为多大/小呢?
def initialize_parameters_random(layers_dims):
np.random.seed(3)
parameters = {}
L = len(layers_dims)
for l in range(1, L):
parameters['W'+str(l)] =
np.random.randn(layers_dims[l], layers_dims[l-1]) * 10
parameters['b'+str(l)] =
np.zeros((layers_dims[l], 1))
return parameters
在本例中,使用np.random.randn(layers_dims[l], layers_dims[l-1]) * 10将参数初始化为一个比较大的值,来测试较大的参数表现如何。
结果如下:
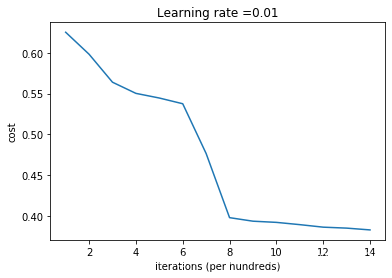
代价从一个极高的值开始(实际上在本例是-inf),在迭代过程中容易出现梯度消失或梯度爆炸。
预测结果如下:
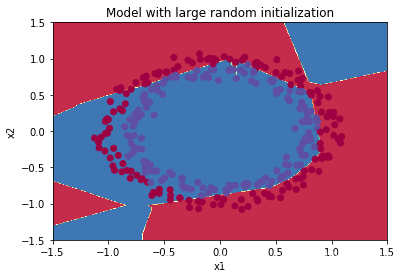
显然,这不是一个好的预测模型。
笔者同时在上代码段修改np.random.randn(layers_dims[l], layers_dims[l-1]) * 0.1将参数初始化为一个很小的值,来测试较小的参数表现如何。
cost - iteration图如下:
预测结果如下:
同样,太小的参数也不是一个可取的结果。
在此基础上,吴恩达老师继续介绍了下一种可行的初始化方法。
3 He初始化 He initialization
He 初始化由He等人在2015年首次提出,与著名的Xavier initialization只有一点细微的差别。
Xavier: sqrt(1./layers_dims[l-1])
He: sqrt(2./layers_dims[l-1])
二者在对W进行标准化的时候采用了以上两种不同的策略(尽管只有极其微小的差别)。
def initialize_parameters_he(layers_dims):
np.random.seed(3)
parameters = {}
L = len(layers_dims)
for l in range(1, L):
parameters['W'+str(l)] =
np.random.randn(layers_dims[l], layers_dims[l-1]) *
np.sqrt(2./layers_dims[l-1])
parameters['b'+str(l)] =
np.zeros((layers_dims[l], 1))
return parameters
cost - iteration图如下:
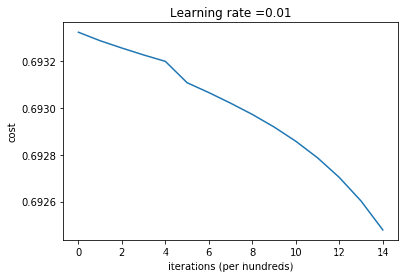
预测结果如下:
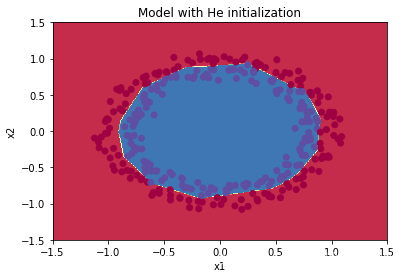
显然,预测结果是很不错的。
关于He 与 Xavier两个初始化方式,简单总结如下:
- He initialization works better for layers with ReLu activation.
- Xavier initialization works better for layers with sigmoid activation.
He 初始化在使用ReLu激活函数时表现很好;Xavier 初始化在使用sigmoid激活函数时表现很好。
二者的基本思想都是:防止方差因为较大或较小的初始值而变化,进而导致梯度在传播过程中(前向、反向)消失等意外的发生。
Ref: Difference between “he and xavier initialization”
4 总结 Conclusion
吴恩达老师在本节末提到:
- Different initializations lead to different results.
- Random initialization is used to break symmetry and make sure different hidden units can learn different things.
- Don’t initialize to values that are too large .
- He initialization works well for networks with ReLU activations.
下一篇:Improving Deep Neural Networks [2]
2019/10 Karl














 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









