






 点击“蓝字”关注我们吧
点击“蓝字”关注我们吧
1 线性模型的局限性
在线性模型中,一个重要的条件便是响应变量 须服从正态分布。然而,实际问题往往更加复杂, 并不总是满足正态分布的假设。
例如,在医学诊断中,我们希望通过病人的各项检查数据判断其是否患癌症。这里是否患癌症作为响应变量 只有两个可能的取值:患和不患。 显然, 不服从正态分布。
类似的例子还有很多。在气象领域中,通过观测到的气象数据判断是否会下雨;在金融领域中,根据当前的金融指标判断是否抛售股票;在图像领域,综合输入的人脸数据判断是否通过验证...
上述问题的共同点是, 的取值是离散的,我们关心的不再是预测具体数值而是变成判断分类。
为了讨论方便,我们以下考虑二分类问题。
机灵的同学可能想到,依然对数据建立线性模型,然后再设定一个阈值 ,当 时,预测数据归为一类;当 时,预测数据归为另一类。
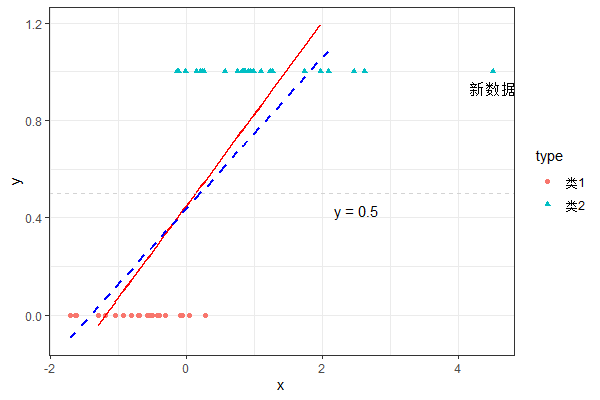
这么做确实可以得到一个分类模型(上图红实线)。但是,如果我们在原有数据上额外得到一个新观测且远离原始数据时, 线性思路得到的新模型就会出现明显的变动(上图蓝虚线)。
2 逻辑回归
究竟哪里出现问题了呢?我们回忆所学的线性模型的形式:
对模型两边取期望和方差可得:
显然可以看出:(1)线性模型对y的估计,本质是对 期望的估计;(2)线性模型中 的期望和方差两者互相独立。
接着来看二分类问题,一般我们考虑 独立同分布于成功概率为 的伯努利分布(Bernouilli Distribution):
两边取期望和方差可得:
此时的期望和方差两者之间存在函数关系且期望取值在 之内。 因此,在二分类问题中完全套用线性模型的框架显然是有问题。
该怎么办呢?
试想 是一个随机变量,在不知道额外信息的前提下,用它的期望作为估计还是挺合理的。因此,我们可以继续采用期望估计的思路。 但是二分类问题中 的期望有0-1的约束,这就需要我们寻找一种满足该要求的函数。通常,这样的函数选取成Logistic函数:
很容易验证Logistic函数满足前面的条件。选取这种函数形式的深层原因,从统计的角度来看,源自于指数族分布。 有兴趣的朋友可以翻阅我关于广义线性模型相关理论的介绍以及其他参考资料。
于是,我们终于等到本次的主角——逻辑回归模型(Logistic Regression Model):
我们之所以称其为回归模型,是因为线性回归深入人心,在其之上生长发展的理论便继承了这个名称。事实上,逻辑回归更多的是面向分类问题。
3 逻辑回归的求解
3.1 极大似然法
最小二乘常被用来求解线性模型中的系数估计值,这在逻辑回归中失效了——我们无法得到逻辑回归的最小二乘损失函数的具体形式。
然而我们知道问题的概率分布信息,因此可以得到相应的似然函数:
再进而得到对数似然函数并进行优化即可。不过,与线性模型具有显示解不同,逻辑回归没有解析解,故而需要结合梯度下降法等算法进行求解,可参考广义线性模型中的相关方法。限于篇幅,不在赘述。
3.2 R求解逻辑回归模型
R中内置glm函数可以求解逻辑回归模型,它的使用方式如下所示。
logmodel predict.glm(logmodel, newdata)# 预测模型与线性模型求解函数lm区别在于,glm需要添加link参数。我们使用该函数对前面的模型再次求解并做图,如下所示。
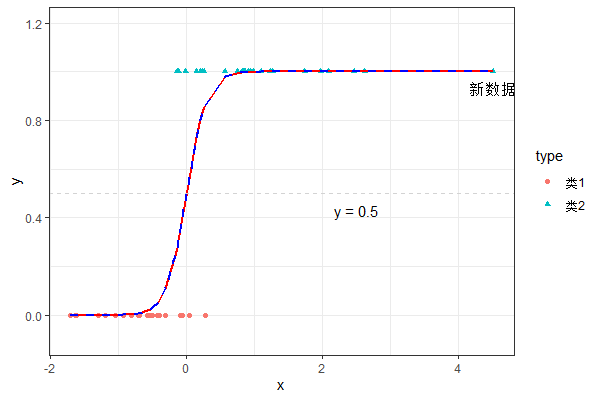
可见,逻辑回归很好的刻画了模型的主要特征,且不会因为新数据的出现模型发生巨大变动。
4 案例分析
4.1 数据描述
我们从UCI机器学习数据库中获取到威斯康辛乳腺癌数据(Breast Cancer Wisconsin)共计569个观测,包含1个字符型分类变量,取值B表示良性肿瘤,取值M表示恶性肿瘤;30个数值型检测指标,如肿块厚度、大小、形态等。
4.2 建立逻辑回归模型
我们使用R读入数据并进行分析。由于数据没有特定顺序,我们选择前70%作为训练集,剩下的作为测试集。为了方便展示结果,我们仅选取前三个变量 进行模型拟合,对应的代码如下所示。
## 逻辑回归模型处理WDBC数据
wdbc colnames(wdbc) wdbc$y # 划分训练集和测试集
wdbc_train wdbc_test # 训练模型
wdbc_fit 4.3 评价模型
首先,我们使用summary()函数查看模型相关的统计指标,具体如下所示。
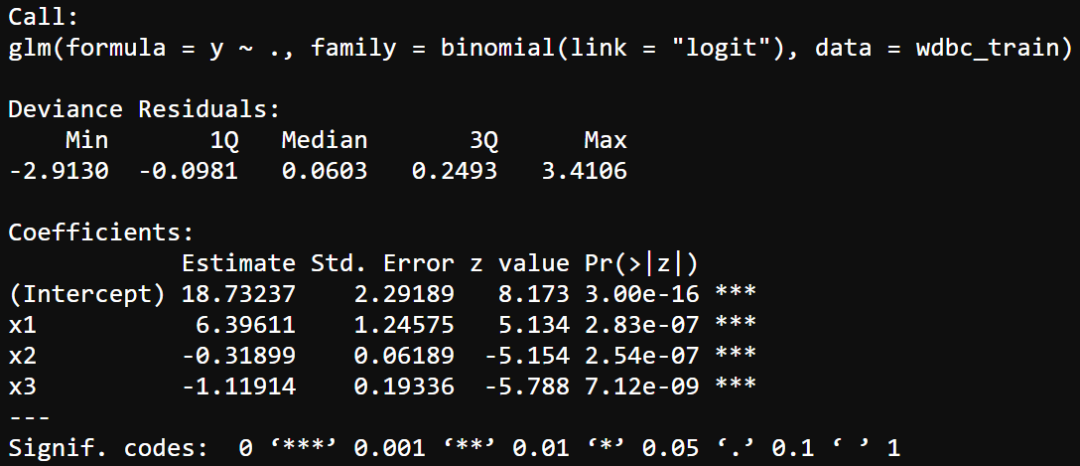
可见,三个系数都非常显著。
其次,我们使用predict.glm()查看模型的内预测效果,得到混淆矩阵(Confusion Matrix)如下
| 真实M | 真实B | 总计 | |
|---|---|---|---|
| 预测M | 215 | 18 | 233 |
| 预测B | 12 | 155 | 167 |
| 总计 | 227 | 173 | 400 |
可以算出模型的预测准确率为(155+215)/400=0.925,仅三个变量就可以很好的预测病人肿瘤的状态。
不过分类问题中,大家比较关心模型的敏感性和特异性。 敏感性指真阳性率,而特异性指真阴性率。以本案例而言,模型的敏感性为0.947,特异性为0.896。这么看来,我们的模型假阳性率为0.104,还是不太好。
library(pROC)
roclong percent=TRUE,ci=TRUE,col="red",
print.auc = T,print.auc.cex = 0.8,print.auc.x = 60,print.auc.y = 50,
main = "逻辑回归的ROC曲线和AUC值")进一步分析敏感性和特异性,可以利用ROC曲线 和AUC值 来刻画。我们在R中使用pROC包画出ROC曲线以及进行AUC的计算和检验,结果参见下图。
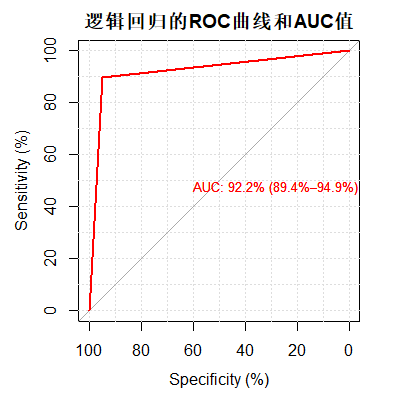
AUC达到了92.2%, 说明模型能够很好的刻画我们的数据。
最后,我们对剩下的测试集进行验证,得到预测准确率为88.76%,还是挺理想的——毕竟我们仅使用三个变量进行建模。关于逻辑回归更多的内容,还请读者自己了解。
参考文献
Myers, Raymond H., et al. Generalized linear models: with applications in engineering and the sciences. 2012.
 扫码关注我们小Q统计专注统计学习知识分享
扫码关注我们小Q统计专注统计学习知识分享














 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









