









1.购买阿里云ECS
最近阿里云有活动,99元一年:2核2G 3M固定带宽 40G ESSD Entry云盘
2.安装JDK
安装1.8的jdk,下载地址:
Oracle官网:Java Downloads | Oracle
华为云镜像:Index of java-local/jdk/8u202-b08
选择x86的rpm包下载即可,如果不知道自己的服务器cpu架构可以执行命令行 arch 查看
先下载
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.rpm下载好之后安装
rpm -ivh jdk-8u202-linux-x64.rpm设置java home环境变量,修改/ect/profile
export JAVA_HOME=/usr/java/jdk1.8.0_202-amd64 # jdk安装路径
export PATH=$PATH:$JAVA_HOME/bin # 在PATH配置后面追加 jdk安装路径的bin目录3.安装Spark
先在root下创建spark文件夹,然后切到该文件夹下进行下载:
3.1 下载Spark 3.3
wget https://archive.apache.org/dist/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3-scala2.13.tgz3.2 解压
tar zxvf spark-3.3.0-bin-hadoop3-scala2.13.tgz3.3 修改/etc/profile文件,新增spark环境变量:
# Spark Environment Variables
export SPARK_HOME=/root/spark/spark-3.3.0-bin-hadoop3-scala2.13
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin3.4 生效profile文件
source /etc/profile3.5 修改spark-env.sh
#切换到conf目录
cd /root/spark/spark-3.3.0-bin-hadoop3-scala2.13/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh增加
export JAVA_HOME=/usr/java/jdk1.8.0_202-amd643.6 启动
#切换到sbin目录
cd /root/spark/spark-3.3.0-bin-hadoop3-scala2.13/sbin
./start-all.sh4.运行例子
启动spark-shell
#切换到sbin目录
cd /root/spark/spark-3.3.0-bin-hadoop3-scala2.13/sbin
./spark-shell运行例子
val seq= Seq(("1","xiaoming",15),("2","xiaohong",20),("3","xiaobi",10))
var rdd1 = sc.parallelize(seq)
val df = rdd1.toDF("id","name","age")
df.select("name","age").filter("age >10").show参考:spark-sql入门(一)通过spark-shell命令行操作_sparkshell执行sql命令-CSDN博客
5.打开Web UI
5.1 需要先添加安全组规则
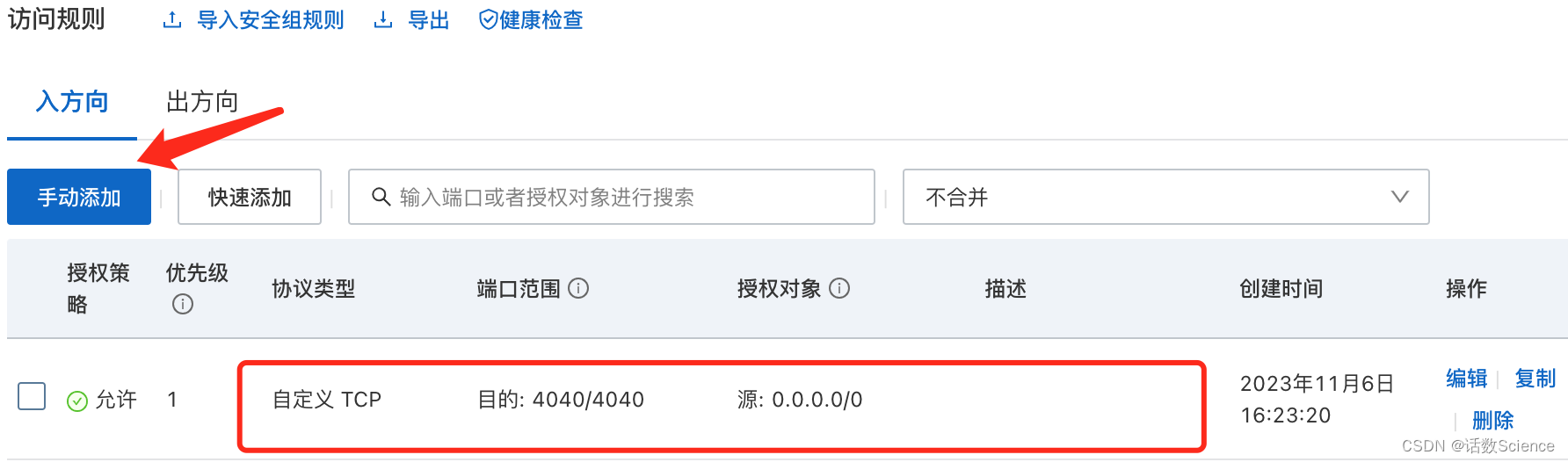
5.2 根据启动时提示的Web UI地址,替换为公网IP即可打开
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Scala version 2.13.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
23/11/06 16:20:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://换成公网ip:4040
Spark context available as 'sc' (master = local[*], app id = local-1699258836302).
Spark session available as 'spark'.5.3 Web UI展示
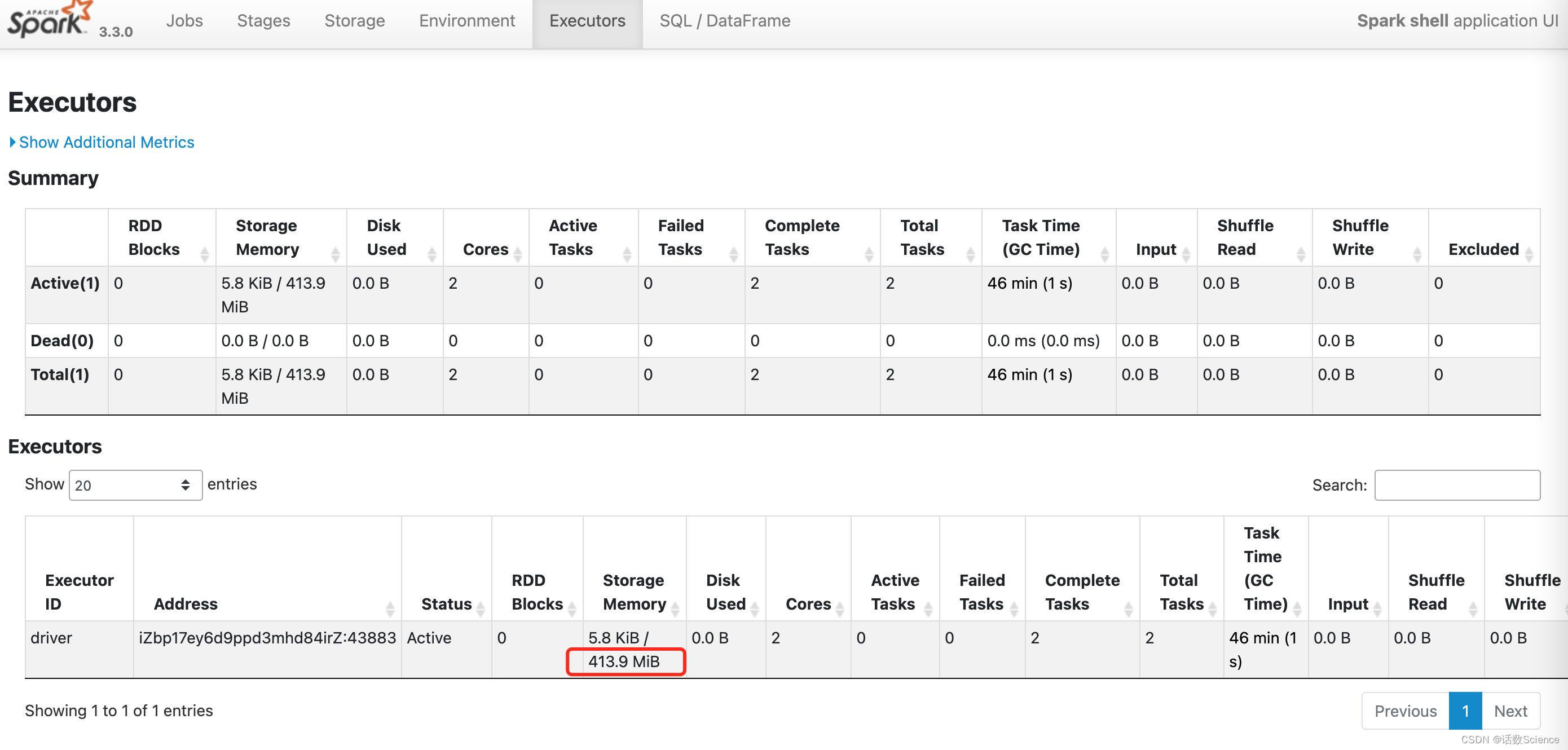
Spark Web UI 中的 Storage Memory 413.9 MiB 计算逻辑:Spark内存管理计算详述-CSDN博客
















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











