










一、LACP:
1、概念
链路聚合控制协议LACP(Link Aggregation Control Protocol),是基于IEEE802.3ad标准的一种实现链路动态聚合与解聚合的协议,以供设备根据自身配置自动形成聚合链路并启动聚合链路收发数据,LACP模式就是采用LACP的一种链路聚合模式。聚合链路形成以后,LACP负责维护链路状态,在聚合条件发生变化时,自动调整链路聚合。
具体工作方式参考(https://support.huawei.com/enterprise/zh/doc/EDOC1100086517/)
所以,通俗的讲,就是多条实体线路合并为一条逻辑线路,通过这种功能可以让网络特定的装置之间的通信速度迅速提升、确保备援能力、提升容错功能。
2、实验
(1)背景知识
实验基于Ubuntu系统进行的,也就是进行多网卡聚合实验。对于本次实验,由于在两个设备(如交换机)之间的链路实质上就是两个对应的网卡,所以链路聚合也就是网卡的聚合,即多个网卡绑定同一个ip地址。
多网卡的聚合有7中绑定模式:0. round robin,1.active-backup,2.load balancing (xor), 3.fault-tolerance (broadcast), 4.lacp, 5.transmit load balancing, 6.adaptive load balancing
第一种模式:mod=0 ,即:(balance-rr) Round-robin policy(平衡抡循环策略)
特点:传输数据包顺序是依次传输(即:第1个包走eth0,下一个包就走eth1….一直循环下去,直到最后一个传输完毕),此模式提供负载平衡和容错能力;但是我们知道如果一个连接或者会话的数据包从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降
第二种模式:mod=1,即: (active-backup) Active-backup policy(主-备份策略)
特点:只有一个设备处于活动状态,当一个宕掉另一个马上由备份转换为主设备。mac地址是外部可见得,从外面看来,bond的MAC地址是唯一的,以避免switch(交换机)发生混乱。此模式只提供了容错能力;由此可见此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有 N 个网络接口的情况下,资源利用率为1/N
第三种模式:mod=2,即:(balance-xor) XOR policy(平衡策略)
特点:基于指定的传输HASH策略传输数据包。缺省的策略是:(源MAC地址 XOR 目标MAC地址) % slave数量。其他的传输策略可以通过xmit_hash_policy选项指定,此模式提供负载平衡和容错能力
第四种模式:mod=3,即:broadcast(广播策略)
特点:在每个slave接口上传输每个数据包,此模式提供了容错能力
第五种模式:mod=4,即:(802.3ad) IEEE 802.3ad Dynamic link aggregation(IEEE 802.3ad 动态链接聚合)
特点:创建一个聚合组,它们共享同样的速率和双工设定。根据802.3ad规范将多个slave工作在同一个激活的聚合体下。
外出流量的slave选举是基于传输hash策略,该策略可以通过xmit_hash_policy选项从缺省的XOR策略改变到其他策略。需要注意的 是,并不是所有的传输策略都是802.3ad适应的,尤其考虑到在802.3ad标准43.2.4章节提及的包乱序问题。不同的实现可能会有不同的适应性。
必要条件:
条件1:ethtool支持获取每个slave的速率和双工设定
条件2:switch(交换机)支持IEEE 802.3ad Dynamic link aggregation
条件3:大多数switch(交换机)需要经过特定配置才能支持802.3ad模式
第六种模式:mod=5,即:(balance-tlb) Adaptive transmit load balancing(适配器传输负载均衡)
特点:不需要任何特别的switch(交换机)支持的通道bonding。在每个slave上根据当前的负载(根据速度计算)分配外出流量。如果正在接受数据的slave出故障了,另一个slave接管失败的slave的MAC地址。
该模式的必要条件:ethtool支持获取每个slave的速率
第七种模式:mod=6,即:(balance-alb) Adaptive load balancing(适配器适应性负载均衡)
特点:该模式包含了balance-tlb模式,同时加上针对IPV4流量的接收负载均衡(receive load balance, rlb),而且不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的。bonding驱动截获本机发送的ARP应答,并把源硬件地址改写为bond中某个slave的唯一硬件地址,从而使得不同的对端使用不同的硬件地址进行通信。
来自服务器端的接收流量也会被均衡。当本机发送ARP请求时,bonding驱动把对端的IP信息从ARP包中复制并保存下来。当ARP应答从对端到达 时,bonding驱动把它的硬件地址提取出来,并发起一个ARP应答给bond中的某个slave。使用ARP协商进行负载均衡的一个问题是:每次广播 ARP请求时都会使用bond的硬件地址,因此对端学习到这个硬件地址后,接收流量将会全部流向当前的slave。这个问题可以通过给所有的对端发送更新 (ARP应答)来解决,应答中包含他们独一无二的硬件地址,从而导致流量重新分布。当新的slave加入到bond中时,或者某个未激活的slave重新 激活时,接收流量也要重新分布。接收的负载被顺序地分布(round robin)在bond中最高速的slave上
当某个链路被重新接上,或者一个新的slave加入到bond中,接收流量在所有当前激活的slave中全部重新分配,通过使用指定的MAC地址给每个 client发起ARP应答。下面介绍的updelay参数必须被设置为某个大于等于switch(交换机)转发延时的值,从而保证发往对端的ARP应答 不会被switch(交换机)阻截。
必要条件:
条件1:ethtool支持获取每个slave的速率;
条件2:底层驱动支持设置某个设备的硬件地址,从而使得总是有个slave(curr_active_slave)使用bond的硬件地址,同时保证每个bond 中的slave都有一个唯一的硬件地址。如果curr_active_slave出故障,它的硬件地址将会被新选出来的 curr_active_slave接管;
其实mod=6与mod=0的区别:mod=6,先把eth0流量占满,再占eth1,….ethX;而mod=0的话,会发现2个口的流量都很稳定,基本一样的带宽。而mod=6,会发现第一个口流量很高,第2个口只占了小部分流量。
(2)实验过程
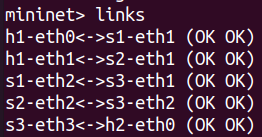
实验的拓扑如下所示,采用mininet构建网络拓扑,这里h1拥有两个网卡,实验中对h1的两个网卡进行聚合绑定。

拓扑创建完成后,运行拓扑,输入命令links,端口对应关系如下所示。
接下来,打开h1的终端,新建文件/etc/modprobe.d/bonding.conf,并写入如下命令
alias bond0 bonding
options bonding mode=4其中,mode=4表示采用第五种模式(IEEE 802.3ad 动态链接聚合)。
然后,执行命令,相当于加载创建的bonding文件。
modprobe bonding接下来,是关键的步骤。需要建立一个名为bond0逻辑界面,设定MAC地址,将h1的两个网卡加入建立好的逻辑界面bond0中,最后启动逻辑界面bond0。具体的命令如下所示。
# 新建一个逻辑界面bond0
ip link add bond0 type bond
# 分配mac地址
ip link set bond0 address 02:01:02:03:04:08
# 将h1的网卡加入bond0中
ip link set h1-eth0 down
ip link set h1-eth1 down
ip link set h1-eth0 address 00:00:00:00:00:11
ip link set h1-eth0 address 00:00:00:00:00:22
ip link set h1-eth0 master bond0
ip link set h1-eth1 master bond0
# 为bond0分配ip地址,并启动逻辑界面
ip addr add 10.0.0.1/24 dev bond0
ip link set bond0 up设置完成后,在h1的终端输入ip a查看网卡信息如下所示:

可以使用下列命令查看bonding的状态,如下所示:
cat /proc/net/bonding/bond0
如上图,在bond中,逻辑界面bond0为master,实体界面h1-eth0和h1-eth1为slave,而且bond0、h1-eth0和h1-eth1的mac地址全部相同。
接下来,进入h2的终端中,为h2的网卡分配ip地址。

至此,所以的设置已经完成,接下来进行试验验证。
首先,在h1中ping h2,此时可以正常地进行通信,结果如下:

然后,断开h1--s1或者h1--s2的链接之后再ping,此时依然可以正常地进行通信,结果如下:

只要两个链路都断开后,通信才不能正常进行。
二、openflow group:(https://blog.csdn.net/weixin_40042248/article/details/113520029?spm=1001.2014.3001.5501)
1、概念
OpenFlow v1.1中增加了组表(Group Table)的概念,并一直被后续的版本所沿用。
OpenFlow支持四种组表类型:
Indirect:执行该group中一个已定义的bucket, 该组仅支持一个bucket。 允许多个流表项或组表项指向一个公共的组(例如IP转发的下一跳)。 这是最简单的group类型,交换机通常比较支持这种类型的group。
All:执行该group中所有的bucket。这种类型的group用来进行multicast和broadcast。为每个bucket克隆一份数据包,然后分别执行每个bucket中的actions。
Select:执行该group中的一个bucket。基于一种选择算法(用户定义的哈希算法或者轮询算法)选择group中的一个bucket对数据包执行actions。这种选择算法应该尽量支持负载均衡并且为每个bucket提供一个权重用于分配。当一个bucket指定的端口down掉,交换机应该将选择限制在剩下的正常的bucket中而不是丢掉,这是为了减少链路中断。
Fast failover:执行第一个活动的bucket。 每个action bucket都与控制其活动性的特定端口和/或组相关联。 按照group定义的顺序评估bucket,并选择与活动端口/组关联的第一个bucket。 这个group类型使交换机可以更改转发行为而无需往返于控制器。 如果没有bucket,则丢弃数据包。
2、实验
通过fast failover这个名字就能发现该类型是一个快速恢复的类型。具体来说就是当转发的端口down掉之后组表能够感知到并且切换到另一个up的端口。在这种类型的组表的行动桶中,具有设置监视对象端口 的watch_port这一个设置项目,可以实现对物理端口的监控,从而实现当转发的端口down掉之后组表能够感知到并且切换到另一个up的端口。
在这里,重新构建了一个网络拓扑如下所示。其中,h1,h2,h3的ip分别设置为10.0.1.1/24,10.0.1.2/24,10.0.1.3/24。

端口对应的关系如下所示。
实验中,设置两个组表的bucket,分别监听s1-eth2和s1-eth3,output分别对应的h2和h3。组表的命令如下。
ovs-ofctl -O openflow13 add-group s1 group_id=1,type=ff,bucket=watch_port:2,actions=output:2,bucket=watch_port:3,actions=output:3接下来,对s1添加流表,命令如下。
ovs-ofctl add-flow s1 priority=1,in_port=1,actions=group:1 -O openflow13
ovs-ofctl add-flow s1 priority=1,in_port=2,actions=output:1 -O openflow13
ovs-ofctl add-flow s1 priority=1,in_port=3,actions=output:1 -O openflow13流表添加完成后,就可以开始实验结果验证了。
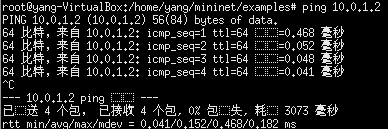
首先,在h1中 ping h2,结果如下所示。可以正常的ping通。
然后,在h1中 ping h3,结果如下所示。无法ping 通。

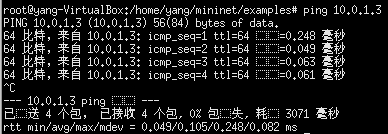
此时,若断开s1-h2之间的链路,就可以实现h1 ping h3了。接下来,将s1-h2之间的链路断开,再在h1中 ping h3,结果如下所示。可以发现已经能够相互ping通了。
















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











