






- 去重函数distinct
删除重复项取唯一值
案例一
--针对table1 中的id,name去重,取唯一值
select distinct id
,name
from table1
;
案例二
--针对table1中的id去重后统计数量
select count(distinct id) as id_cnt
from table1
;
案例三
--针对table1中的id,name去重后统计数量(即id和name均相同的统计为1)
select count(distinct id,name) as cnt
from table1
;
- 字符串分割函数SUBSTRING_INDEX
用于从字符串中获取指定分隔符分割后的子串
语法:SUBSTRING_INDEX(str,delim,count),其中,str 是要分割的字符串,delim 是分隔符,count 表示返回的子串数量。
案例一
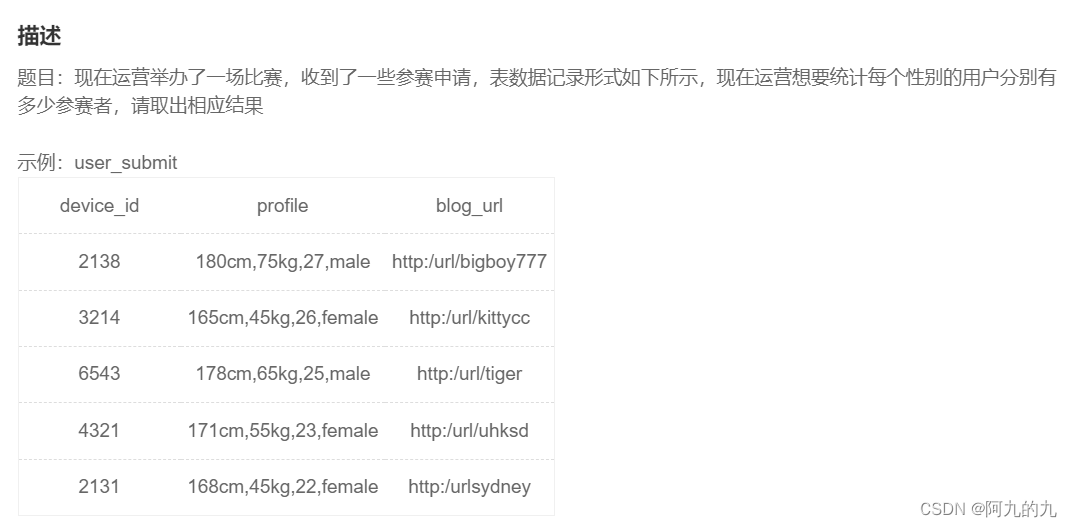
解析:
--substring_index(profile, ',', 3) 返回3个字串
select substring_index(profile, ',', -1) as gender
,count(device_id) as number
from user_submit
group by gender
;
其他解题思路:
1.使用 case when + like 拆分出性别作为gender字段后统计
select
--case when 有顺序,female中包含字符male,先选出female防止将female误分为male
case
when profile like '%female%' then 'female'
when profile like '%male%' then 'male'
else '其他'
end as gender
,count(device_id) as number
from user_submit
group by gender
;
--或者
select
--加上‘,’作为识别
case
when profile like '%,male' then 'male'
when profile like '%,female' then 'female'
else '其他'
end as gender
from user_submit
group by gender
;
2.使用 case when + find_in_set
find_in_set(str, strlist) 其中 str 为要查询的字符串,strlist 为被查询的字段,精确匹配,以英文 ‘,’ 分隔;
select
case
when find_in_set('female', profile) then 'female'
when find_in_set('male',profile) then 'male'
else '其他'
end as gender
,count(device_id) as number
from user_submit
group by gender
;
案例二
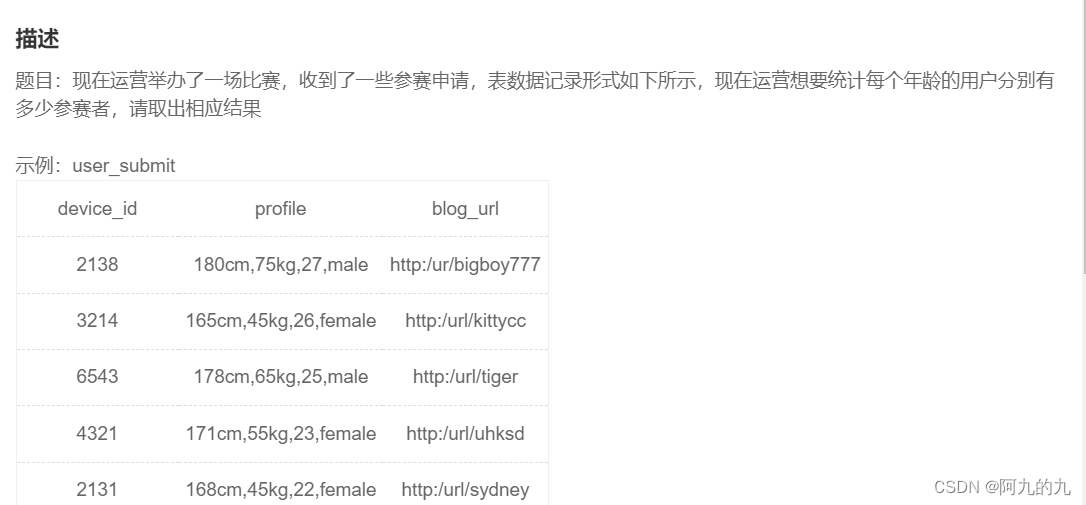
解析:
--截取出年龄,再根据年龄分组计数
select substring_index(substring_index(profile,',',3),',',-1) as age
,count(device_id) as number
from user_submit
group by age
;















 6796
6796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









