







1. 官方文档
heapq --- 堆队列算法 — Python 3.12.4 文档
2. 相关概念
堆 heap 是一种具体的数据结构(concrete data structures);优先级队列 priority queue 是一种抽象的数据结构(abstract data structures),可以通过堆、二叉搜索树、链表等多种方式来实现 priority queue,其中,堆是最流行的实现优先级队列的具体数据结构。
2.1 优先级队列 Priority Queue
抽象数据结构是一种逻辑上的概念,描述了数据的组织方式和操作方式。优先级队列 Priority Queue 通常用于优化任务执行,其目标是处理具有最高优先级的任务。任务完成后,其优先级降低,并返回到队列中。
Priority Queue 支持三种操作:
- is_empty:检查队列是否为空。
- add_element:向队列中添加一个元素。
- pop_element:弹出优先级最高的元素。
对于元素的优先级有两种约定(约定或惯例 convention,指约定俗称的用法或含义,特定上下文中使用的特定术语、符号、语法或行为的含义):1. 最大的元素具有最高的优先级;2. 最小的元素具有最高的优先级。
这两种约定其实是等价的,如果元素由数字组成,那么使用负数即可完成转换。Python heapq 模块使用第二种,这也是两种约定中更常见的一种。在这个约定下,最小的元素具有最高的优先级。
优先级队列对于查找某个极端元素是非常有用的,如:找到点击率前三的博客文章、找到从一个点到另一个点的最快方法、根据到站频率预测哪辆公共汽车将首先到达车站等问题。
2.2 堆 heap
2.2.1 堆属性
堆是特殊的完全二叉树(complete binary tree),其中每个上级节点的值都小于等于它的任意子节点(堆属性),堆常用于实现优先级队列。
二叉树(binary tree)中,每个节点最多有两个子节点。完全二叉树是一种特殊的二叉树,其定义是: 若设二叉树的深度为 h,除第 h 层外,其它各层 1~h-1 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边。也就是说,完全二叉树的所有非叶子节点都必须被填满,叶子节点都必须连续排列在最左边。满二叉树是特殊的完全二叉树。完全二叉树的性质保证,树的深度是元素数的以2为底的对数向上取整。
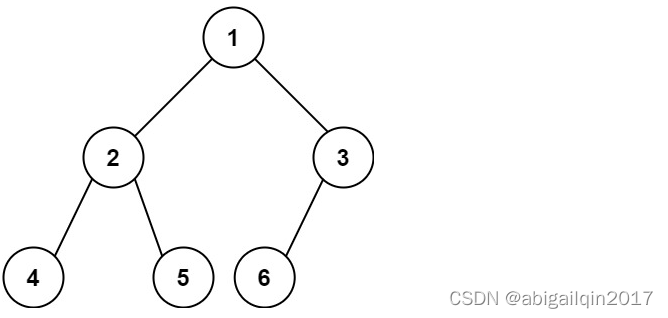
在堆树中,一个节点的值总是小于它的两个子节点,这被称为堆属性(与二叉搜索树不同,二叉搜索树中,只有左侧节点的值小于其父节点的值)。在堆中,同一层的节点之间并没有大小关系的限制,唯一的限制是每个节点的值必须符合堆属性。
add 操作: 1. 创建新节点添加到堆的末尾。如果底层未满,将节点添加到最深层下一个开放槽中,否则,创建一个新的层级,将元素添加到新的层中。 2. 将新元素与其父节点比较,如果新元素比父节小,则交换它们的位置,直到新元素的值小于其父节点的值或者新元素成为了根节点。
pop 操作: 1. 根据堆属性,该元素位于树的根。将堆顶元素弹出,并将堆末尾元素移到堆顶。 2. 将堆顶元素与其左右子节点比较,将其与较大(或较小)的子节点交换位置,直到堆顶元素的值大于(或小于)其左右子节点的值或者堆顶元素成为了叶子节点。
2.2.2 性能保证 performance guarantees
具体数据结构实现抽象数据结构中定义的操作,并明确性能保证 performance guarantees,即数据规模和操作所需时间之间的关系,性能保证可用于预测程序行为,比如,当输入的大小发生变化时,程序将花费多少时间完成操作。
优先级队列的堆实现保证推入(添加)和弹出(删除)元素都是对数时间操作。这意味着执行push 和 pop 所需的时间与元素数量的以2为底的对数成正比。对数增长缓慢。以2为底15的对数约为4,以2为底1万亿的对数约为40。这意味着,如果一个算法在处理15个元素时足够快,那么它在处理1万亿个元素时只会慢10倍。
2.2.3 堆与二叉搜索树的区别
排序方式不同:堆是一种基于完全二叉树的数据结构,它的每个节点都满足堆的性质,即父节点的值大于(最大堆)(或小于,即最小堆)子节点的值。而二叉搜索树则是一种有序的二叉树结构,它的每个节点都满足左子树的节点值小于该节点的值,右子树的节点值大于该节点的值。
操作不同:堆常用于实现优先队列,可以快速找到最大或最小值。堆的插入和删除操作都比较快,但查找操作比较慢。而二叉搜索树可以快速查找、插入和删除节点,但是在某些特殊情况下,可能会出现树的不平衡,导致性能下降。
强调:Python 的 heapq 模块和堆数据结构一般都不支持查找除最小元素之外的任何元素,如果想检索指定大小的元素,可以使用二叉搜索树。
堆作为优先级队列的实现,是解决涉及极端问题的好工具,当在问题描述中存在如:最大、最小、前、底、最低,最优等字眼,表明需要寻找某些极端元素时,可以考虑一下堆。
3. Python heapq Module
前面将堆描述为树,不过它是一个完全二叉树,这意味着除了最后一层之外,每层有多少元素是确定的。因此,堆可以使一个列表实现。Python 中的 heapq 模块就是使用列表实现堆的,heapq 将列表的第一个元素视为堆的根节点。
堆队列中,索引为 k 的元素与其周围元素之间的关系:
- 它的第一个子结点是 2*k + 1。
- 它的第二个子结点是 2*k + 2。
- 它的父结点是 (k - 1) // 2。
堆队列中的元素总是有父元素,但有些元素可能没有子元素。如果 2*k 超出了列表的末尾,则该元素没有任何子元素。如果 2*k + 1是有效索引,但 2*k + 2不是,则该元素只有一个子元素。
h[k] <= h[2*k + 1] and h[k] <= h[2*k + 2] 可能引发IndexError,但永远不会为False。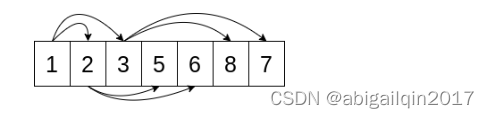
3.1 heapq 模块
Python 的 heapq 模块使用列表实现堆操作,与许多其他模块不同,heapq 模块不定义自定义类,但定义了直接处理列表的函数。
3.1.1 堆函数
| 函数 | 功能 |
| heapq.heapify(x) | 将list x 转换成堆,原地,线性时间内。 |
| ===== heapq 模块中的其他基本操作假设列表已经是堆 ===== | |
| heapq.heappush(heap, item) | 将 item 的值加入 heap 中,保持堆的不变性。 |
| heapq.heappop(heap) | 弹出并返回 heap 的最小的元素,保持堆的不变性。 如果堆为空,抛出 IndexError 。 使用 heap[0] ,可以只访问最小的元素而不弹出它。 |
| heapq.heappushpop(heap, item) | 将 item 放入堆中,然后弹出并返回 heap 的最小元素。 heappushpop() is equivalent to heappush() followed by heappop(). |
| heapq.heapreplace(heap, item) | 弹出并返回 heap 中最小的一项,同时推入新的 item。 如果堆为空引发 IndexError。 heapreplace() is equivalent to heappop() followed by heappush(). 单步骤 heappushpop 和 heaprepalce 比分开执行 pop 和 push 更高效; 它们是 pop 和 push 的组合,非常适合在固定大小的堆使用: heapreplace() 从堆中返回一个元素并将其替换为 item;heaprepalce 返回的值可能会比新加入的值大,如果不希望如此,可改用 heappushpop(),它返回两个值中较小的一个,将较大的留在堆中。 |
- 空列表或长度为1的列表总是一个堆。
- 创建堆时,可以从空堆开始,将元素一个接一个地插入到堆中。如果已经有一个元素列表,使用 heapq 模块 heapify() 函数把它原地转换成有效堆。
- heapify() 就地修改列表,但不对其排序,堆不必为了满足堆属性而进行排序。但是,由于每个排序列表都满足堆属性,在排序列表上运行 heapify() 不会改变列表中元素的顺序。
- 由于树的根是第一个元素,第一个元素 a[0] 总是最小的元素。
import heapq
a = [3, 5, 1, 2, 6, 8, 7]
heapq.heapify(a)
a
# [1, 2, 3, 5, 6, 8, 7]
heapq.heappop(a)
# 1
a
# [2, 5, 3, 7, 6, 8]
heapq.heappush(a, 4)
heapq.heappop(a)
# 2
heapq.heappop(a)
# 3
heapq.heappop(a)
# 43.1.2 通用函数
| 函数 | 功能 |
| heapq.merge(*iterables, key=None, reverse=False) | merge 函数用于 merging sorted sequences,它假设输入的可迭代对象已经排序,使用堆来合并多个可迭代对象(例如,合并来自多个日志文件的带时间戳的条目),返回一个迭代器,而不是一个列表。 类似于 sorted(itertools.chain(*iterables)), 但需假定每个输入流都是已排序的(从小到大),且返回一个可迭代对象 iterator,不会一次性地将数据全部放入内存(节省内存)。 具有两个可选参数: key 指定带有单个参数的 key function,用于从每个输入元素中提取比较键。 默认值为 None (直接比较元素)。 reverse 为一个布尔值。 如果设为 True,则输入元素将按比较结果逆序进行合并。 要达成与 sorted(itertools.chain(*iterables), reverse=True) 类似的行为,所有可迭代对象必须是已从大到小排序的。 |
| heapq.nlargest(n, iterable, key=None) | 从 iterable 所定义的数据集中返回前 n 个最大元素组成的列表。 key 为一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。 等价于:sorted(iterable, key=key, reverse=True)[:n]。 |
| heapq.nsmallest(n, iterable, key=None) | 从 iterable 所定义的数据集中返回前 n 个最小元素组成的列表。 key 为一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。 等价于: sorted(iterable, key=key)[:n]。 在 n 值较小时可考虑使用 heapq.nlargest 和 heapq.nsmallest; 对于较大的值,使用 sorted() 函数更有效率; 当 n==1 时,使用内置的 min() 和 max() 函数更高效; 如果需要重复使用这些函数,可考虑将可迭代对象转为真正的堆。 |
3.1.3 应用示例
调度(合并)多组周期性任务
假设有一个系统,系统中存在几种电子邮件,不同类型的电子邮件有不同发送频率,比如 A 类邮件每15分钟发送一次,B 类每40分钟发送一次。 可以使用堆设计一个调度程序:首先,将各种类型的电子邮件添加到队列中,每封电子邮件带一个时间戳,指示下一次发送的时间;然后,查看具有最小时间戳的元素,计算在发送之前需要睡眠的时间,当调度程序醒来时,处理此邮件;处理完成后,从优先级队列中取出电子邮件,计算该邮件的下一个时间戳,放回到队列中正确的位置。
import datetime
import heapq
def email(frequency, email_type):
current = datetime.datetime.now()
while True:
current += frequency
yield current, email_type
fast_email = email(datetime.timedelta(minutes=10), "fast email")
slow_email = email(datetime.timedelta(minutes=30), "slow email")
unified = heapq.merge(fast_email, slow_email)
for _ in range(10):
print(next(unified))
# (datetime.datetime(2024, 6, 14, 16, 40, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 16, 50, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 0, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 0, 8, 28884), 'slow email')
# (datetime.datetime(2024, 6, 14, 17, 10, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 20, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 30, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 30, 8, 28884), 'slow email')
# (datetime.datetime(2024, 6, 14, 17, 40, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 50, 8, 28884), 'fast email')上述代码中,heapq.merge() 的输入是无限生成器,返回值也是一个无限迭代器,这个迭代器将按照未来时间戳的顺序生成待发送的电子邮件序列。观察 print 打印的结果,fast email 每10分钟发送一次,slow email 每40分钟发送一次,两种邮件合理交错。merge 不读取所有输入,而是动态地工作,因此,尽管两个输入都是无限迭代器,前10项的打印依然能很快完成。
得分前 N 项(后 N 项)
已知2016年夏季奥运会女子100米决赛的成绩,要求打印前三名运动员姓名。
import heapq
results="""\
Christania Williams 11.80
Marie-Josee Ta Lou 10.86
Elaine Thompson 10.71
Tori Bowie 10.83
Shelly-Ann Fraser-Pryce 10.86
English Gardner 10.94
Michelle-Lee Ahye 10.92
Dafne Schippers 10.90
"""
top_3 = heapq.nsmallest(3, results.splitlines(), key=lambda x: float(x.split()[-1]))
print("\n".join(top_3))
# Elaine Thompson 10.71
# Tori Bowie 10.83
# Marie-Josee Ta Lou 10.86















 1948
1948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









