






- 一问:人工智能为什么突然火了?
- 二问:人工智能会造成大规模失业吗?
- 三问:人工智能可以预测女朋友什么时候生气吗?
- 四问:如何快速上手数据分析,加入人工智能行业?
一问:人工智能为什么突然火了?
人工智能(Artificial Intelligence,简称AI)是制造智能机器、可学习计算程序和需要人类智慧解决问题的科学和工程,回顾人工智能的发展历程,我们可以看到,它并不是一个全新的概念,业界普遍认定1956年一场在美国达特茅斯(Dartmouth)大学召开的学术会议为人工智能研究的起点,到2016年 AlphaGo 击败李世石,正好60年时间。已经发展了60多年的人工智能研究,何以突然在近些年如此的火热,迎来爆发式的增长?主要有三方面原因:
首先,从计算力方面看,随着硬件成本的不断下降,以及大数据、云计算等“计算基础设施”的不断发展,人工智能所需要的强大算力已经得到保证。多层神经网络以及BP反向传播算法等,在1986年就已经问世,可见,人工智能需要的算法早已具备,只是计算力一直没有增长到足矣支撑人工智能计算量的水平,即短时间内可进行海量数据的计算和反复迭代。如今,随着量子计算研究的不断进展,原有冯诺依曼体系的架构面临新的突破,人类所能创造的算力还有可能进一步飞跃,届时人工智能想必还有更加长足的发展;
其次,人工智能算法本身也有长足发展。机器学习算法一般可分为三种:有监督机器学习(如回归,分类等算法)、无监督机器学习(如聚类、关联规则等)、增强学习或强化学习,人工智能前60年的研究主要集中在有监督学习上,即在给定样本情况下的机器学习,应用领域包括图像、语音识别,NLP(Natural Language Processing,自然语言处理,以下简称NLP)等。无监督学习与有监督学习相反,不给定样本,或者说数据没有标签,让机器自己推断出数据中的内在结构或关系,近年来随着金融等领域的应用,无监督学习的研究也有了很大发展。而增强学习的研究,则是以AlphaGo的横空出世为里程碑,在增强学习中,机器与外部环境不断交互,通过不断尝试,获取正向或负向的回报,根据回报的累计来学习最佳策略。可以看出,强化学习与人类或者说生物学习的过程是更加接近的,这也让人工智能更加的“像人”,而不仅是冷冰冰的机器和算法。
最后,产业界的强烈需求也促使人工智能应用的落地。各行各业的人力成本不断高企,计算成本逐渐下降,替代人工、解放劳动力的呼声愈发强烈,同时,每天全球各行各业产生的海量数据也成为人工智能应用的“粮食”。
二问:人工智能会造成大规模失业吗?
先说结论:AI 会带来大规模失业吗?——会
这个问题其实隐含了另一个问题:我们需要担心吗?——不用过于担心
我们先来看第一个问题:
为什么 AI 会带来大规模失业?
事实上,失业已经发生了,只是是否需要定义为大规模的问题:
高盛只剩三名股票交易员
花旗银行总裁Forese表示,集团未来5年将减少花旗银行总裁Forese表示,集团未来5年将减少10000名技术和运营人员。微软解雇了数十名为Microsoft News和MSN网站编辑新闻的记者和工作人员。解雇后,微软采取了一项措施,转向依靠人工智能挑选MSN网站以及该公司新闻软件Microsoft News上展现的新闻和内容。
随手一搜,这样的新闻不在少数。究其原因,自然是因为 AI 相比于人类有诸多优势:
严格遵守纪律,不会被情绪影响——适合从事自动化交易、客服等工作;
计算能力强,处理速度快——适合从事计算量大,但是场景相对单一的工作;
单一场景经过训练后超过人类——适合从事违规图像识别、违规检测等工作;
不眠不休,有点就能持续工作——适合从事……几乎所有职业这一点上都秒杀人类。
此外,可以与任何智能设备融合,这又使他们获得了机器人的优势:
行为可操控,动作精确度大大超过人类——适合从事制造业、生物科学;
不惧怕病毒、辐射、寒冷、高热等恶劣条件——适合从事救援、探索、高危作业。
这些想必大家也都清楚,不然也不会有这个问题问出来了。我们重点来看看:
为什么我们不需要担心?
- AI距离大规模落地,道阻且长
与其担心AI带来大规模失业,先担心一下AI从业者大规模失业吧。
我们来看看著名的Gartner Hype Cycle,到底是个啥,靠不靠谱?
时光倒回7-8年前,那时候还没人提人工智能、区块链,因为他们还处于技术萌芽期,最火的当数大数据,再早几年是云计算,我们看看2012年,他们在Gartner Hype Cycle上处于什么位置:
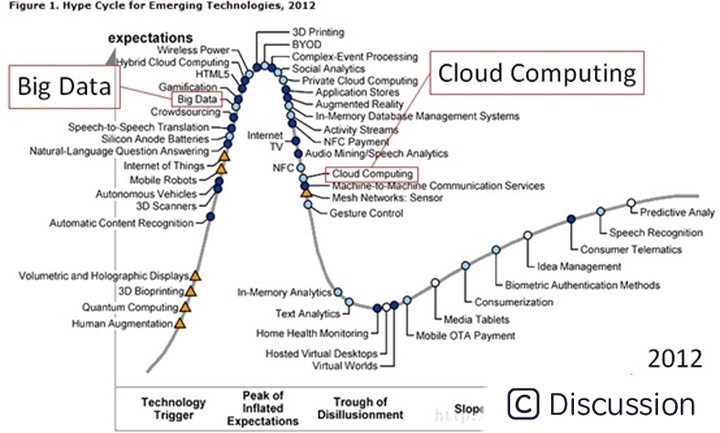
可以看到,大数据即将爬升到泡沫顶峰,云计算已经开始下降,仔细看看,还可以看到很多大家熟悉的技术,比如HTML5,NFC支付等。
来到2014年:

大数据和云计算都进入下降通道,泡沫加速破灭。到了今天,我们在图上已经看不到他们了,因为他们已经走完了爬坡期,进入成熟期,不再是一种新技术了。在工业界的应用情况呢?现在哪家互联网公司还没部署Hadoop?初创公司不用AWS、阿里云?听起来好像不可思议,落地成果满地开花。
说回我们的主角——人工智能,2017年的Hype Cycle:
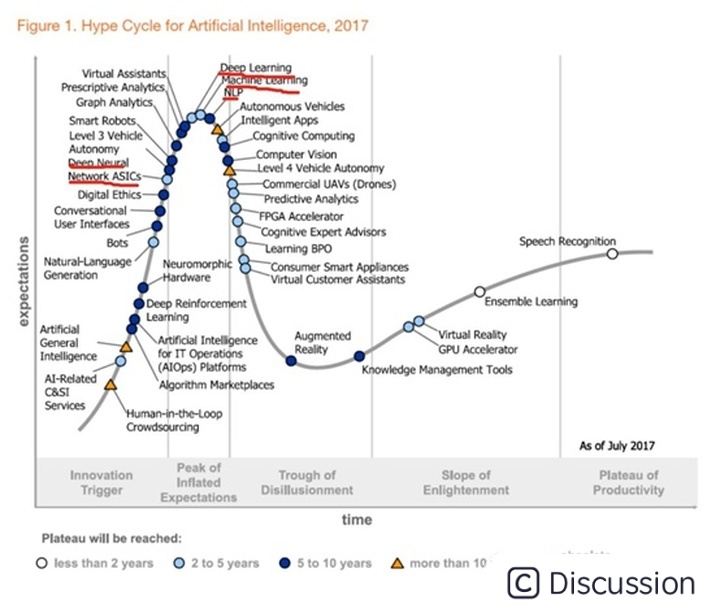
AI相关技术加速爬升,到了2019年:

开始进入泡沫破裂期。影响体现在方方面面,招聘缩水,独角兽破产,明星企业裁员……
当然,还会有AI行业的从业者失业,虽然这并不是问题的初衷,但是结果是一样的。
距离AI真正落地,还有相当长的时间,并且,现在的人工智能,还是“人工”智能,或者叫弱人工智能,和大家在电影里看到的强人工智能还有非常大的差距,要替代人类的工作还有很长的路要走。
- AI在导致失业的同时,会创造新的工种和职位
为了让AI有充足的样本进行训练,AI行业也开始大规模启用线上外包模式。比如图片标注,我们想训练AI识别一张图片是猫还是狗,对于人类来说,哪怕是婴儿,也只需要简单训练几次即可,但是对于AI,需要大量的人,将很多张图片,标注成是猫还是狗,在学习到足够多的样本,抽象出足够多的特征后,AI才能自己识别新图片。
因此这是一个劳动密集型的行业,标注者的水平不用太高。当然,除了图片标注,还有语音识别,不然你以为Siri、小米小爱、天猫精灵、科大讯飞都是怎么学习用户声音的?

还有,另一个行业也有大量的标注需求,那就是自动驾驶

所以数据标注员,被称为最后被AI取代的人,因为AI一直需要他们。
数据标注员,就是AI创造的新工种,被称为人工智能时代的“农民工”。这个行业还可以给很多残障人士提供就业机会:
作为一名换过40份工作的聋哑人,他很庆幸,终于在“数据标注”领域成了“有用的人”。小袁是京东众智平台上“静公会”的聋哑人标注员,这个公会全部由听障人士组成。——咖啡猫,公众号:甲子光年“数据折叠”:今天,那些人工智能背后“标数据的人”正在回家 | 甲子光年
今后,还会有更多的类似职位出现,虽然说起来有点悲哀,他们总是处在人工智能光鲜亮丽的阴暗面,为人工智能的成长提供养料。但是相比失业来说,相比从事重体力劳动来说,相比从事高危作业来说,这样的工作更加安全,薪水也不少,不失为一种更好的选择。
- AI无法真正的取代人类
前面提到,目前的人工智能,说好听点叫弱人工智能,说难听点就是人工智障,别说人类了,连乌鸦都比不过。下面节选朱松纯教授的《浅谈人工智能》给大家看看:

上图a是一只乌鸦,被研究人员在日本发现和跟踪拍摄的。乌鸦是野生的,也就是说,没人管,没人教。它必须靠自己的观察、感知、认知、学习、推理、执行,完全自主生活。假如把它看成机器人的话,它就在我们现实生活中活下来。如果这是一个自主的流浪汉进城了,他要在城里活下去,包括与城管周旋。浅谈人工智能:现状、任务、构架与统一 | 正本清源
首先,乌鸦面临一个任务,就是寻找食物。它找到了坚果(至于如何发现坚果里面有果肉,那是另外一个例子了),需要砸碎,可是这个任务超出它的物理动作的能力。其它动物,如大猩猩会使用工具,找几块石头,一块大的垫在底下,一块中等的拿在手上来砸。乌鸦怎么试都不行,它把坚果从天上往下抛,发现解决不了这个任务。在这个过程中,它就发现一个诀窍,把果子放到路上让车轧过去(图b),这就是“鸟机交互”了。后来进一步发现,虽然坚果被轧碎了,但它到路中间去吃是一件很危险的事。因为在一个车水马龙的路面上,随时它就牺牲了。我这里要强调一点,这个过程是没有大数据训练的,也没有所谓监督学习,乌鸦的生命没有第二次机会。这是与当前很多机器学习,特别是深度学习完全不同的机制。
然后,它又开始观察了,见图c。它发现在靠近红绿路灯的路口,车子和人有时候停下了。这时,它必须进一步领悟出红绿灯、斑马线、行人指示灯、车子停、人流停这之间复杂的因果链。甚至,哪个灯在哪个方向管用、对什么对象管用。搞清楚之后,乌鸦就选择了一根正好在斑马线上方的一根电线,蹲下来了(图d)。这里我要强调另一点,也许它观察和学习的是别的地点,那个点没有这些蹲点的条件。它必须相信,同样的因果关系,可以搬到当前的地点来用。这一点,当前很多机器学习方法是做不到的。比如,一些增强学习方法,让机器人抓取一些固定物体,如积木玩具,换一换位置都不行;打游戏的人工智能算法,换一换画面,又得重新开始学习。
它把坚果抛到斑马线上,等车子轧过去,然后等到行人灯亮了(图e)。这个时候,车子都停在斑马线外面,它终于可以从容不迫地走过去,吃到了地上的果肉。你说这个乌鸦有多聪明,这是我期望的真正的智能。
——朱松纯,公众号:视觉求索
类似这样的智能,才是我们期望中强人工智能的样子。我们距离这种智能,还太远太远了。哪怕有朝一日,真的实现了类似智能,距离人类仍然十分遥远,我们有生之年未必能够看见。
所以,结论是人工智能带来大规模失业,但是我们不必过于担心,因为AI距离真正落地,道阻且长,而且会产生很多新的工种和职业,并且目前的 AI 即便真的落地了,也是弱人工智能,距离大家想象中的强人工智能,还有很长的距离。
与其杞人忧天,不如抓紧过好当下,找到自己真正热爱的职业,才是我们现在要做的,也是我们一直应该做的。
三问:人工智能可以预测女朋友什么时候生气吗?
从理论上来说,只要一件事情满足一定的规律,或者说,在大多数情况下满足某一规律,那么人工智能都可以预测,难点在于:
1. 数据的收集
2. 外界因素的变化对样本的影响难以估计
我们先来看看第一点,数据的收集对于人工智能来说至关重要,你需要告诉人工智能,在发生了什么事件(自变量x)时,会导致什么事件发生(因变量y),经过大量的样本训练之后,算法才知道遇到什么事件的时候,发生目标事件的概率是多少。
预测女朋友生气,同样需要大量样本的收集。在这个场景下,就带来两个问题:
- 样本量越大,预测的结果越精准
- 样本量越大,女朋友生气次数越多,离开你的可能性越大
所以,如果你的目的是为了让人工智能帮助你预测女朋友生气的事件,进而避开相关前置事件,从而达到和女朋友稳定关系的目的,那么训练这个人工智能的过程则有可能让你失去你的女朋友。因为这些样本必须来自于你的女朋友生气,而不能来自于其他女性的生气,毕竟不同的人对于生气的触发条件大相径庭。
好吧,我们先假设这个悖论被解决了,你拿捏得恰到好处,获取了足够的样本,又不至于让你女朋友离你而去。
那么关键的问题就在于就是样本的数据如何收集了。 文本数据的收集其实已经比较成熟了,基于文本数据收集后的NLP应用方面,微软小冰已经做得相当好了,体验过的同学应该明白。此处我们来想想,基于非文本的收集采集怎么做呢?
我们假设,样本的采集,限定在你和你女朋友相处的时间段。那么非文本的数据,大概有视频、语音以及当时的环境要素、天气要素等,甚至包括你女朋友的身体各项指标(如体温、心跳等),当然还包括你的身体各项指标,以及你的外表、穿的衣服、刮没刮胡子等等。
视频、语音、环境等要素,可以用类似Google Glass这种设备来采集,实时上传到云端进行解析和训练,身体指标可以通过智能设备(如手环)等采集、上传和训练。对了,为了保护你和你女朋友的隐私,可以采用边缘计算+联邦学习的方式,采集数据以后,在本地进行计算,将计算后的结果,上传至云端参与训练,这样,云端是拿不到具体的视频、语音、身体指标等敏感信息的。看起来不错,至少有生之年可以实现。
当然,有人觉得,最直接的方法,是采集女朋友的详细身体指标,比如血液中激素含量等,这个绝对比外界因素更准确。且不说采集这个数据的难度如何,当激素发生变化的时候,我们认为生气已经几乎再所难免了,我们的目标是,在引起生气的前置事件发生时就加以预测和提示,彻底避免女朋友生气。
接下来看第二个问题。我们都知道,一个事情的发生,通常不是由单一因素决定的,通常是由多个因素综合决定的。加上我们需要预测的是人的行为,而人是一个极其复杂的研究对象,并且,女人比男人更加复杂。因此女生生气这件事,需要考虑的因素非常多,比如不仅取决于当时的对话内容,更取决于你的历史表现;不仅取决于你和她在一起的时间,也取决于她和你相遇之前遭遇了什么(这就涉及到数据采集的范围扩充了,但是要采集女朋友不和你在一起的时候的数据,实操上更加困难,而且会侵犯她的隐私,导致她无可挽回的生气)。
类似的情况,是金融机构预测一个人的还款意愿。相对于较容易量化的还款能力,还款意愿其实很难量化,只能根据一个人的过往借贷记录。但是当经济环境变化,借款人个人的情况、家庭的情况发生变化时,过往的借贷记录也不一定代表了他当下的意愿。
最关键的,不能让你女朋友知道你在尝试通过AI预测她生气这件事,这会导致多种不可预测的结果。要么她很好奇,开始伪造样本,假装生气后者在生气时假装平静;要么她很生气,觉得你侵犯她的隐私;要么她很欣慰,觉得你很在乎她。虽然不能确定她会怎样变化,可以肯定的是她的行为模式一定会发生变化。
这也是数据分析中很有趣的一个现象。最经典的莫过于Google Flu了,当年Google通过搜索“Flu”的用户所在地以及搜索数量,成功的遭遇CDC预测了流感的爆发地,这个故事大家都知道,但是很少有人知道,在Google Flu的成果被公布以后,其预测就不再准确了。因为很多人听说之后感到好奇,尝试性的搜索“Flu”,使得样本出现巨大偏差。
总的来说,人工智能在理论上,可以预测女朋友生气,但是实操起来难度太大。并且,以现在人工智能的水平,你在收集数据的过程中,应该会比人工智能更快的掌握导致女朋友生气的要素,从而比人工智能更快更好的预测女朋友生气。所以我认为,男同胞们可以参考人工智能学习的方法论来尝试预测女朋友生气,你会比AI更加智能。
四问:如何快速上手数据分析,加入人工智能行业?
这个问题,应该是应届生们比较关心,先来泼个冷水。我们在学习数据分析的过程中,或者说在学校里做项目、写paper,拿到的基本上是干净的数据集,要做的事情很简单,基本上可以确定X,Y以后直接进入特征工程的阶段,然而,在实际中的情况基本上都是下图的下半部分:
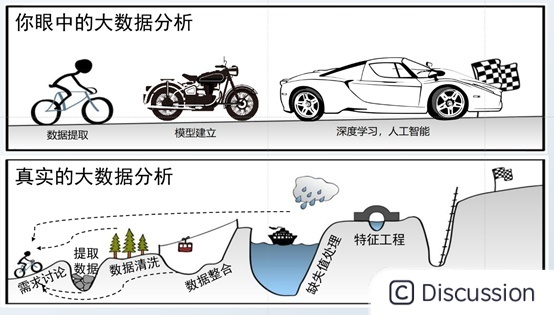
现实中的情况,首先问题和需求定义不清晰,可能业务或者产品也不太清楚他们想要什么,他们只是试探性的需要一些结论,想验证他们的想法。其次原始数据一塌糊涂,质量差,分布散,在金融行业,数据还可能有严格的管控流程,要提取生产数据基本脱层皮,因此能走到数据整合阶段基本上小半个月过去了,拿到的还是一堆一言难尽的数据。
因此,在面试的时候,面试官考察的不光是你的算法能力,同时也要看你的沟通能力,问题理解能力,问题定义能力,以及一定的工程能力。虽说越是大厂,分工越细,会有专门的数据工程师配合你,但是如果你拿到有一点问题的数据集,什么也不会干,就躺平等别人帮你清洗干净,那这样的算法同学大家都不想要。
话说回来,数据分析、人工智能仍然是未来的趋势,虽然目前遇到一些困难,但是大家也不用怀疑人生,把业余时间利用起来,Kaggle上打打比赛,还有很多企业举办的比赛也多去参加,多了解一些行业应用,想办法积累实战经验,未来仍然是属于你们的。














 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









