






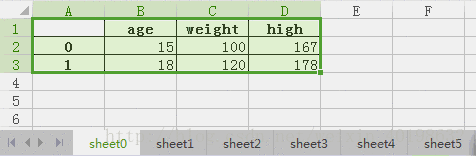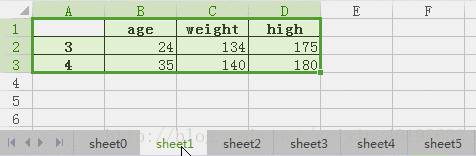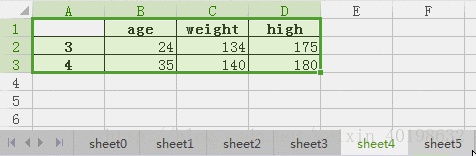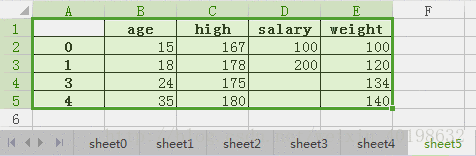
例如c是这个:
| age | weight | high | |
| 0 | 15 | 100 | 167 |
| 1 | 18 | 120 | 178 |
| age | weight | high | |
| 3 | 24 | 134 | 175 |
| 4 | 35 | 140 | 180 |
import pandas as pd
c=pd.DataFrame([[15,100,167],[18,120,178]],columns=['age','weight','high'])
d=pd.DataFrame([[24,134,175],[35,140,180]],columns=['age','weight','high'],index=[3,4])
X=[c,d]
Z=pd.concat(X)
合并后的Z展示为:
| age | weight | high | |
| 0 | 15 | 100 | 167 |
| 1 | 18 | 120 | 178 |
| 3 | 24 | 134 | 175 |
| 4 | 35 | 140 | 180 |
但是,如果两个DataFrame的columns不同时候:
如e:
| age | weight | high | salary | |
| 0 | 15 | 100 | 167 | 100 |
| 1 | 18 | 120 | 178 | 200 |
和f:
| age | weight | high | |
| 3 | 24 | 134 | 175 |
| 4 | 35 | 140 | 180 |
在这个里面e比f多个salary,合并方法也一样:
e=pd.DataFrame([[15,100,167,100],[18,120,178,200]],columns=['age','weight','high','salary'])
f=pd.DataFrame([[24,134,175],[35,140,180]],columns=['age','weight','high'],index=[3,4])
Y=[e,f]
A=pd.concat(Y)
合并后的A为:
| age | high | salary | weight | |
| 0 | 15 | 167 | 100 | 100 |
| 1 | 18 | 178 | 200 | 120 |
| 3 | 24 | 175 | 134 | |
| 4 | 35 | 180 | 140 |
注:在dataframe中的NAN在xlsx中是没有显示的
下面将五个DataFrame保存到同一个xlsx中的不同的sheet中,代码如下:
All=[c,d,Z,e,f,A]
writer = pd.ExcelWriter('d:/c.xlsx')
for i in range(6):
All[i].to_excel(writer,sheet_name='sheet'+str(i))
writer.save()















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









