







0. 运行环境:
Win10系统,Python3.9
1. 问题描述:
因为急需批量处理一些PDF文件,但在网上以 Python、PDF 等关键词一通搜索找到的东西并不能用,PyPDF2、pypdf 等一堆库也搞不清楚,所以找时间专门做了点功课,有需要自取。我的第一次尝试是:
pip install PyPDF2然后编译别人的代码就发现了以下报错:
PyPDF2.errors.DeprecationError: PdfFileWriter is deprecated and was removed in PyPDF2 3.0.0. Use PdfWriter instead.
PyPDF2.errors.DeprecationError: PdfFileReader is deprecated and was removed in PyPDF2 3.0.0. Use PdfReader instead.
PyPDF2.errors.DeprecationError: reader.getPage(pageNumber) is deprecated and was removed in PyPDF2 3.0.0. Use reader.pages[page_number] instead.
PyPDF2.errors.DeprecationError: reader.getPage(pageNumber) is deprecated and was removed in PyPDF2 3.0.0. Use reader.pages[page_number] instead.
PyPDF2.errors.DeprecationError: mediaBox is deprecated and was removed in PyPDF2 3.0.0. Use mediabox instead.
PyPDF2.errors.DeprecationError: getWidth is deprecated and was removed in PyPDF2 3.0.0. Use width instead.
PyPDF2.errors.DeprecationError: reader.getNumPages is deprecated and was removed in PyPDF2 3.0.0. Use len(reader.pages) instead.
PyPDF2.errors.DeprecationError: lowerLeft is deprecated and was removed in PyPDF2 3.0.0. Use lower_left instead.
PyPDF2.errors.DeprecationError: addPage is deprecated and was removed in PyPDF2 3.0.0. Use add_page instead.
PyPDF2.errors.DependencyError: PyCryptodome is required for AES algorithm最后一条报错貌似是与 PDF 加密解密有关系,我也不懂这些但好像并不需要我懂,我后来在官网上找到了解决方法:If you plan to use PyPDF2 for encrypting or decrypting PDFs that use AES, you will need to install some extra dependencies. Encryption using RC4 is supported using the regular installation.
pip install PyPDF2[crypto]前几条报错其实都是一样的,都是新版本的 PyPDF2 把之前旧版本的很多函数都改了,但是很多公众号或是帖子里面的教程依然还是 PyPDF2 2.0 之前的内容,而 pip 安装默认是最新版本,看起来大家确实很喜欢用这个,所以我打算简单做个翻译工作,学着那些教程(例如:Python操作PDF全总结|pdfplumber&PyPDF2、掌握PDF文件处理的神器:Python PyPDF2库详解、Python 自动化办公 —— PyPDF2 库的基本使用)把 PyPDF2 2.0 船新版本的用法写一下。
2. 关于版本
我从 https://realpython.com/pdf-python/#history-of-pypdf-pypdf2-and-pypdf4 这里看到了讲 pyPdf PyPDF2 和 PyPDF4 的历史,或 https://blog.csdn.net/qq_30007885/article/details/102314912 这是中文的,以及还有一个 常用Python PDF库对比,我觉得这个对比写的很好。确实是版本很多很复杂,我本想理一理,结果是剪不断理还乱,所以直接总结:目前为止出现的多种基于 python 的 pdf 处理库,最流行的就是 PyPDF2,但它的流行版本已经不再维护且不支持高版本的 python。除此以外我发现在 github 上搜索其实只能找到一个代码仓库,也就是 https://github.com/py-pdf/pypdf,而且诡异的是,pypdf 和 PyPDF2 的源代码都在这里,我起初认为它们是一个东西,甚至还搜索过类似 “pypdf 和 PyPDF2 的区别” 这样的问题,但是无果。从源码上来看他们确确实实不一样,不过 >2.0 版本的 PyPDF2 和 pypdf 的用法是差不多的,很多函数名都是一样的。这个结论是来自于我几乎看完了 PyPDF2 手册 和 pypdf 手册,他们的结构和内容大同小异,所以我再次直接总结:可以把高版本的 PyPDF2 和 pypdf 当成一个东西。并且我更建议学习 pypdf,其次是 >2.0 版本的 PyPDF2,别的就别用了,用的人不多有问题都找不到人问。官方给出的与 python 对应版本说明如下(左边是 pypdf 手册里的,右边是 PyPDF2 手册里的):
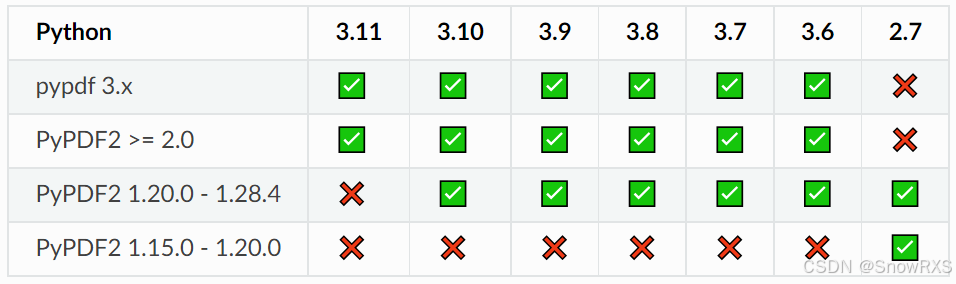
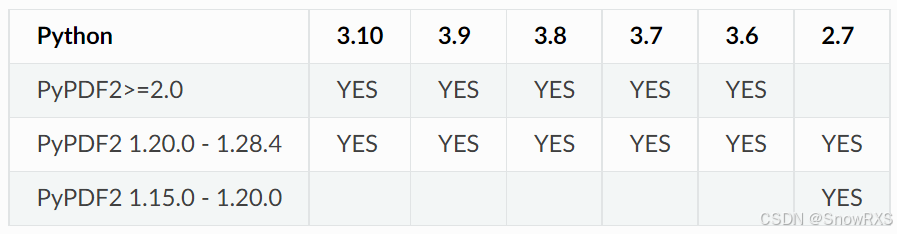
3. 使用教程
我将同时演示 PyPDF2 和 pypdf 的代码,我本人的偏向性是使用 pypdf,从运行结果是可以看出差距的。这里使用的 PyPDF2 是 3.0.1,使用的 pypdf 是 5.1.0。不过大于 2.0 的 PyPDF2 和大于 3.0 的 pypdf 应该都适用。
以下内容整理自官方的手册(英文版) PyPDF2 手册 和 pypdf 手册,如果有不愿意读英文但是想钻研手册的,我找到了一个 PyPDF2 中文教程。
3.1 安装
虽然有上面的版本对应图,但手册里还是写明了 pypdf 要求 Python 3.8+,PyPDF2 要求 Python 3.6+。我这里测试的环境是 Python 3.9。
pip install pypdf # 没用没用
pip install --user pypdf # 为当前用户安装
pip install pypdf[crypto] # 使用了 Advanced Encryption Standard (AES) 的 PDF
pip install pypdf[image] # 涉及到图像
pip install pypdf[full] # 直接安装全家桶
如果是要装 PyPDF2,指令和上面完全一样,把 pypdf 换成 PyPDF2。
3.2 新版本改动说明
官方原话 PyPDF2<2.0.0 is very different from PyPDF2>2.0.0,至于有多不同,自己看吧:https://pypdf2.readthedocs.io/en/3.x/user/migration-1-to-2.html,很神奇的是,pypdf 里面也有这么一节内容,且讲的却是 PyPDF2。
3.3 PDF 规范
特别一提,pypdf 针对的是 PDF 2.0,而 PyPDF2 是 PDF 1.7。这两个版本的规范我没有细看,https://pdfa.org/resource/pdf-specification-archive/,前者是 2020 年的,而后者是 08 年的。该怎么选大家心中有数了吧。手册中提到,在 PdfReader 也就是读取文件的函数中设置 strict=True 可以在遇到不符合规范的 PDF 时 raise an exception。
3.4 信息读取
from PyPDF2 import PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
meta = reader.metadata
print("基于 PyPDF2")
print("PDF 页数 ", len(reader.pages))
print("PDF 作者 ", meta.author)
print("PDF 创建 ", meta.creator)
print("PDF 产商 ", meta.producer)
print("PDF 主题 ", meta.subject)
print("PDF 标题 ", meta.title)
from pypdf import PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
meta = reader.metadata
print("基于 pypdf")
print("PDF 标题 ", meta.title)
print("PDF 作者 ", meta.author)
print("PDF 主题 ", meta.subject)
print("PDF 创建 ", meta.creator)
print("PDF 产商 ", meta.producer)
print("PDF 创建日期 ", meta.creation_date)
print("PDF 更新日期 ", meta.modification_date)3.5 文本提取
其实有更高级的需求,比如 pdf 转 word,这个功能只能算是 pdf 转格式化的 txt,我这里推荐一个免费良心的网站,可以解决 15Mb 以下的 pdf 文件转换 https://smallpdf.com/pdf-to-word,效果我用了感觉是不错的,如果超过大小限制,可以移步 3.15 把 pdf 分成多个,或是移步 3.13 通过删除图像、压缩图像、无损压缩 pdf 等方式降低带转换的 pdf 大小。如果转换要求不高或是文件量很大,其实下面的这几行代码更快。
from PyPDF2 import PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
page = reader.pages[0]
print(page.extract_text())
from pypdf import PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
page = reader.pages[0]
print(page.extract_text())
print(page.extract_text(0)) # 横排文字
print(page.extract_text((0, 90))) # 横排和竖排文字
print(page.extract_text(extraction_mode="layout")) # 固定宽度提取,保持原 pdf 布局
print(page.extract_text(extraction_mode="layout", layout_mode_space_vertically=False)) # 删除空行和“仅空格”行)
print(page.extract_text(extraction_mode="layout", layout_mode_strip_rotated=False)) # 排除(默认)或包含(False)相对于页面旋转的文本3.6 特殊文本处理(仅 pypdf ,未测试直接搬运)
PDF 中会有一些两个英文字母合并成一个来打印的现象,这部分需要额外的专门处理。
def replace_ligatures(text: str) -> str:
ligatures = {
"ff": "ff",
"fi": "fi",
"fl": "fl",
"ffi": "ffi",
"ffl": "ffl",
"ſt": "ft",
"st": "st",
# "Ꜳ": "AA",
# "Æ": "AE",
"ꜳ": "aa",
}
for search, replace in ligatures.items():
text = text.replace(search, replace)
return text甚至还有连字符的处理(注意存在失败可能):
from typing import List
def remove_hyphens(text: str) -> str:
"""
This fails for:
* Natural dashes: well-known, self-replication, use-cases, non-semantic,
Post-processing, Window-wise, viewpoint-dependent
* Trailing math operands: 2 - 4
* Names: Lopez-Ferreras, VGG-19, CIFAR-100
"""
lines = [line.rstrip() for line in text.split("\n")]
# Find dashes
line_numbers = []
for line_no, line in enumerate(lines[:-1]):
if line.endswith("-"):
line_numbers.append(line_no)
# Replace
for line_no in line_numbers:
lines = dehyphenate(lines, line_no)
return "\n".join(lines)
def dehyphenate(lines: List[str], line_no: int) -> List[str]:
next_line = lines[line_no + 1]
word_suffix = next_line.split(" ")[0]
lines[line_no] = lines[line_no][:-1] + word_suffix
lines[line_no + 1] = lines[line_no + 1][len(word_suffix) :]
return lines以及页眉页脚的处理(不一定是靠谱的,可能会误删):
def remove_footer(extracted_texts: list[str], page_labels: list[str]):
def remove_page_labels(extracted_texts, page_labels):
processed = []
for text, label in zip(extracted_texts, page_labels):
text_left = text.lstrip()
if text_left.startswith(label):
text = text_left[len(label) :]
text_right = text.rstrip()
if text_right.endswith(label):
text = text_right[: -len(label)]
processed.append(text)
return processed
extracted_texts = remove_page_labels(extracted_texts, page_labels)
return extracted_texts3.7 图像提取
尝试提取整个 PDF 文档中的图片并保存到当前文件夹中,我测试了一篇图比较多的论文,这两个库都没有提取全,PyPDF2 提出来 8 张图,而 pypdf 提出来 13 张,而论文中一共有 15 张图(且看我的后续分析)。
from PyPDF2 import PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
count = 0
for page in reader.pages:
for image_file_object in page.images:
with open(str(count) + image_file_object.name, "wb") as fp:
fp.write(image_file_object.data)
count += 1
print("总计保存图片 {} 幅。".format(count))
from pypdf import PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
count_all = 0
for page in reader.pages:
for count, image_file_object in enumerate(page.images):
with open(str(count) + image_file_object.name, "wb") as fp:
fp.write(image_file_object.data)
count_all += 1
print("总计保存图片 {} 幅。".format(count_all))pypdf 的文档中指出 Some other objects can contain images, such as stamp annotations. 所以有以下的修正:
from pypdf import PdfReader
reader = PdfReader("test_stamp.pdf")
im = (
reader.pages[0]["/Annots"][0]
.get_object()["/AP"]["/N"]["/Resources"]["/XObject"]["/Im4"]
.decode_as_image()
)
im.show()
不过我的测试文件并不是它说的图像包含在注释中。我使用的测试 pdf 是一篇英文文献:Vision-Only Robot Navigation in a Neural Radiance World(欢迎一起测试),我找到了漏检的两张图,发现图中的英文单词甚至都可以选中:如下所示黄色高亮部分:
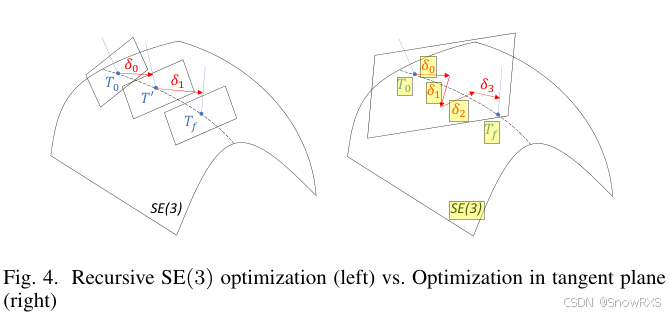
所以我怀疑这两张漏检的图可能是代码生成的(也就是在 LaTex 中直接绘制生成 PDF,而不是插图的方式),通过这种方式生成的图也许不能被 pypdf 检测出来,而 PyPDF2 就更不用说了,它漏的更多。当然这是我的个人猜测,如果有懂行的大佬希望不吝赐教。不考虑这种情况的话,一般的插图,pypdf 的检测效果还是非常不错的。
3.8 添加密码
pypdf 和 PyPDF2 的区别在于,前者可以把密码设置成中文字符,后者不可以,会直接打不开文件。不过如果把密码设置成中文,输入的时候打字是不行的,可以复制粘贴汉字。这个功能还是挺好玩的,可以让自己的 pdf 文件需要密码才能打开。
from pypdf import PdfReader, PdfWriter
reader = PdfReader("你的PDF文件路径.pdf")
writer = PdfWriter(clone_from=reader)
writer.encrypt("密码可以是中文但是只能粘贴", algorithm="AES-256")
with open("你的加密PDF输出路径.pdf", "wb") as f:
writer.write(f)
from PyPDF2 import PdfReader, PdfWriter
reader = PdfReader("你的PDF文件路径.pdf")
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
writer.encrypt("密码不能是中文")
# Save the new PDF to a file
with open("你的加密PDF输出路径.pdf", "wb") as f:
writer.write(f)3.9 多 PDF 拼接
顾名思义。这种基本功能,两个库的代码也是完全一致。pypdf 有更加灵活的用法,我就不搬过来了,我也没测试过,可以移步 https://pypdf.readthedocs.io/en/latest/user/merging-pdfs.html
from PyPDF2 import PdfWriter
merger = PdfWriter()
for pdf in ["你的PDF文件1路径.pdf", "你的PDF文件2路径.pdf", "你的PDF文件3路径.pdf"]:
merger.append(pdf)
merger.write("拼接的PDF文件输出路径.pdf")
merger.close()
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["你的PDF文件1路径.pdf", "你的PDF文件2路径.pdf", "你的PDF文件3路径.pdf"]:
merger.append(pdf)
merger.write("拼接的PDF文件输出路径.pdf")
merger.close()3.10 剪裁和旋转(未测试直接搬运)
说实话我感觉我用不到这个功能,从未有过这个需求,可能还是我见识少了。先是 pypdf 的:
from pypdf import PdfReader, PdfWriter
reader = PdfReader("example.pdf")
writer = PdfWriter()
# Add page 1 from reader to output document, unchanged.
writer.add_page(reader.pages[0])
# Add page 2 from reader, but rotated clockwise 90 degrees.
writer.add_page(reader.pages[1].rotate(90))
# Add page 3 from reader, but crop it to half size.
page3 = reader.pages[2]
page3.mediabox.upper_right = (
page3.mediabox.right / 2,
page3.mediabox.top / 2,
)
writer.add_page(page3)
# Write to pypdf-output.pdf.
with open("pypdf-output.pdf", "wb") as fp:
writer.write(fp)
from pypdf import PdfReader, PdfWriter
reader = PdfReader("input.pdf")
writer = PdfWriter()
writer.add_page(reader.pages[0])
writer.pages[0].rotate(90)
with open("output.pdf", "wb") as fp:
writer.write(fp)然后是 PyPDF2 的:
from PyPDF2 import PdfWriter, PdfReader
reader = PdfReader("example.pdf")
writer = PdfWriter()
# add page 1 from reader to output document, unchanged:
writer.add_page(reader.pages[0])
# add page 2 from reader, but rotated clockwise 90 degrees:
writer.add_page(reader.pages[1].rotate(90))
# add page 3 from reader, but crop it to half size:
page3 = reader.pages[2]
page3.mediabox.upper_right = (
page3.mediabox.right / 2,
page3.mediabox.top / 2,
)
writer.add_page(page3)
# add some Javascript to launch the print window on opening this PDF.
# the password dialog may prevent the print dialog from being shown,
# comment the the encription lines, if that's the case, to try this out:
writer.add_js("this.print({bUI:true,bSilent:false,bShrinkToFit:true});")
# write to document-output.pdf
with open("PyPDF2-output.pdf", "wb") as fp:
writer.write(fp)
from PyPDF2 import PdfWriter, PdfReader
reader = PdfReader("input.pdf")
writer = PdfWriter()
writer.add_page(reader.pages[0])
writer.pages[0].rotate(90)
with open("output.pdf", "wb") as fp:
writer.write(fp)3.11 注释的读取和添加(未测试也没搬运)
PDF 规范 2.0 里面规定了以下的类型的注释:Text、Link、FreeText、Line、Square、Circle、Polygon、PolyLine、Highlight、Underline、Squiggly、StrikeOut、Caret、Stamp、Ink、Popup、FileAttachment、Sound、Movie、Screen、Widget、PrinterMark、TrapNet、Watermark、3D、Redact、Projection、RichMedia 这些都可以用 pypdf 读出来,或是添上去,其中最后三个是 PyPDF2 不支持的,因为 PDF 规范 1.7 里面没有。我觉得这些应该是一个 PDF 阅读器的内置功能,但写代码高效办公似乎并不需要这样。所以码一下,如果有需要我再补充。
3.12 添加水印或是邮戳或是盖章
喜闻乐见(不是)。水印和邮戳盖章的区别是,水印是在 PDF 的文字下面,而邮戳盖章是浮于表面覆盖了文字。
from pathlib import Path
from typing import List, Union
from pypdf import PdfReader, PdfWriter, Transformation
def stamp(
content_pdf: Union[Path, str],
stamp_pdf: Union[Path, str],
pdf_result: Union[Path, str],
page_indices: Union[None, List[int]] = None,
):
# 选用的是存放着邮戳的 pdf 的第一页内容
stamp_page = PdfReader(stamp_pdf).pages[0]
writer = PdfWriter()
reader = PdfReader(content_pdf)
writer.append(reader, pages=page_indices)
# 每一页都盖印章
for content_page in writer.pages:
content_page.merge_transformed_page(
stamp_page,
Transformation().scale(0.5),
)
writer.write(pdf_result)
stamp("你的PDF文件路径.pdf", "邮戳或是水印.pdf", "生成的PDF文件路径.pdf")也可以用图片。但是 pypdf 的处理逻辑还是图像转换为 pdf 然后叠起来。
from io import BytesIO
from pathlib import Path
from typing import List, Union
from PIL import Image
from pypdf import PageRange, PdfReader, PdfWriter, Transformation
def image_to_pdf(stamp_img: Union[Path, str]) -> PdfReader:
img = Image.open(stamp_img)
img_as_pdf = BytesIO()
img.save(img_as_pdf, "pdf")
return PdfReader(img_as_pdf)
def stamp_img(
content_pdf: Union[Path, str],
stamp_img: Union[Path, str],
pdf_result: Union[Path, str],
page_indices: Union[PageRange, List[int], None] = None,
):
# 图片被转换成 pdf
stamp_pdf = image_to_pdf(stamp_img)
stamp_page = stamp_pdf.pages[0]
writer = PdfWriter()
reader = PdfReader(content_pdf)
writer.append(reader, pages=page_indices)
for content_page in writer.pages:
content_page.merge_transformed_page(
stamp_page,
Transformation(),
)
with open(pdf_result, "wb") as fp:
writer.write(fp)
stamp_img("你的PDF文件路径.pdf", "邮戳或是水印.png", "生成的PDF文件路径.pdf")如果要改成水印,也就是放到文字下面,简单在 merge_transformed_page 这个函数的参数里面加一个 over=False,即:
for content_page in writer.pages:
content_page.merge_transformed_page(
stamp_page,
Transformation(),
over=False,
)3.13 压缩文件尺寸(未测试直接搬运)
这似乎涉及到一些存储方面的东西,其实 PDF 已经很紧凑了,不过存在一些情况:例如 PDF 文档多次包含同一对象采用了多次嵌入,如果改成嵌入一次并引用两次就可以缩小尺寸。使用 PyPDF2 进行一次文件的读写就可以在暗中解决这个问题。
from PyPDF2 import PdfReader, PdfWriter
reader = PdfReader("big-old-file.pdf")
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
writer.add_metadata(reader.metadata)
with open("smaller-new-file.pdf", "wb") as fp:
writer.write(fp)pypdf 似乎没有这么方便,它需要增加一行如下代码:其中 remove_identicals 是删除重复,而 remove_orphans 是删除没有使用的对象。
writer.compress_identical_objects(remove_identicals=True, remove_orphans=True)图像是最占用 PDF 大小的东西,如果不想删除,也可以压缩一下,pypdf 是支持的:
from pypdf import PdfWriter
writer = PdfWriter(clone_from="example.pdf")
for page in writer.pages:
for img in page.images:
img.replace(img.image, quality=80)
with open("out.pdf", "wb") as f:
writer.write(f)更高级一些的是无损压缩。像 PyPDF2 和 pypdf 都支持 FlateDecode 过滤器,该过滤器使用 zlib/defrate 压缩方法。这两句是我直接翻译的手册上的,我不懂但我觉得很厉害。
from PyPDF2 import PdfReader, PdfWriter
reader = PdfReader("example.pdf")
writer = PdfWriter()
for page in reader.pages:
page.compress_content_streams() # This is CPU intensive!
writer.add_page(page)
with open("out.pdf", "wb") as f:
writer.write(f)from pypdf import PdfWriter
writer = PdfWriter(clone_from="example.pdf")
for page in writer.pages:
page.compress_content_streams() # This is CPU intensive!
with open("out.pdf", "wb") as f:
writer.write(f)3.14 增加 Java 代码
好家伙啊我直呼好家伙。但是这个功能和所用的 PDF 阅读器有关联,有的阅读器并不支持,Adobe 可以:https://opensource.adobe.com/dc-acrobat-sdk-docs/library/jsapiref/index.html,我使用的是 SumatraPDF,挺好用的但是似乎不支持这个功能,懒得装别的软件所以这里就不演示了。
3.15 PDF 部分截取
只需要 pdf 文件中的某一页或是某几页。这个功能其实在前面的代码里面都有,手册里面并没有作为专门的一节拿出来,因为是个比较常用的功能,所以我也整理一下:
from pypdf import PdfWriter, PdfReader
reader = PdfReader("你的PDF文件路径.pdf")
writer = PdfWriter()
writer.append(reader, pages=[0, 4]) # 第 1 页和第 5 页
with open("裁取的PDF文件1输出路径.pdf", "wb") as fp:
writer.write(fp)
start_page = 1
end_page = 5
writer = PdfWriter()
writer.append(reader, pages=[i for i in range(start_page-1, end_page)]) # 第 1 页到第 5 页
with open("裁取的PDF文件2输出路径.pdf", "wb") as fp:
writer.write(fp)如果用 PyPDF2 的话就是把 from pypdf import ... 改成 from PyPDF2 import ... 因为这些函数的名字都一样。
4. 总结
作为 python 的开源 pdf 处理库,pypdf 更好用,也是更受重视的主流和趋势吧。如果熟悉 PyPDF2 >2.0 版本的话,上手很简单,很多代码直接用就行,很多函数名都一样;如果是使用早期版本的 PyPDF2,那可以继续用的,需要注意 pip install PyPDF2==早期版本号,防止安装最新的版本导致代码报错;如果是刚接触想找一个不错的工具,那我确实推荐 pypdf。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









