






又有新的开源 MMDiT 架构图像生成模型可以使用了。Fal 开源了 AuraFlow v0.1图像生成模型,ComfyUI 和 Diffusers 都已经支持。

开源 AI 岌岌可危。随着社区对 AI 模型的兴趣在过去一年中飙升,新的开源基础模型的开发陷入停滞。甚至有人大胆宣布开源 AI 已死。但不要这么快下结论!
AuraFlow 模型系列的首个版本是迄今为止最大的完全开源的基于流的生成模型,能够进行文本到图像的生成。AuraFlow 再次证明了开源社区的韧性和不懈的决心。
Auraflow 非常擅长提示跟进。下面展示一些AuraFlow的生成效果。

提示 1:“一张身穿绿色连衣裙的美丽女人的照片。她旁边有三个独立的盒子。右边的盒子里装满了柠檬。中间的盒子里有两只小猫。左边的盒子里装满了粉色橡胶球。背景中有一盆盆栽,旁边是一架大钢琴。”

提示 2:“一只一半是橙色虎斑猫,一半是黑色猫,从中间分开。手里拿着一个马提尼酒杯,里面有一团毛线。他的左眼上戴着单片眼镜,戴着一顶蓝色高顶帽,新艺术风格
相关链接
项目地址:https://github.com/fal-ai/fal
Huggingface地址:https://huggingface.co/fal/AuraFlow
模型库:https://fal.ai/models/fal-ai/aura-flow
播客地址:https://huggingface.co/fal/AuraFlow?ref=blog.fal.ai
技术介绍

如何使用它?
如果您想尝试一些快速提示,请前往fal 的模型库开始尝试。
如果您想使用该模型构建一些很酷的 Comfy 工作流程,请获取最新版本的Comfy并从我们的HuggingFace 页面下载模型权重。
我们要向 ComfyUI 和 HuggingFace 🤗 扩散器 🧨 团队致以最诚挚的谢意,感谢他们在 Comfy 上以及diffusers第 0 天为 AuraFlow 提供原生支持!
技术细节
MFU as a first-class citizen
大多数层不需要 MMDiT 块:虽然 MMDiT 取得了良好的性能,但我们发现,删除许多层以仅使用单个 DiT 块是训练这些模型的更具可扩展性和计算效率的方法。通过在小规模代理中进行仔细搜索,我们删除了大多数 MMDiT 块并将其替换为大型 DiT 编码器块。这提高了 6.8B 规模的模型浮点利用率 15%。
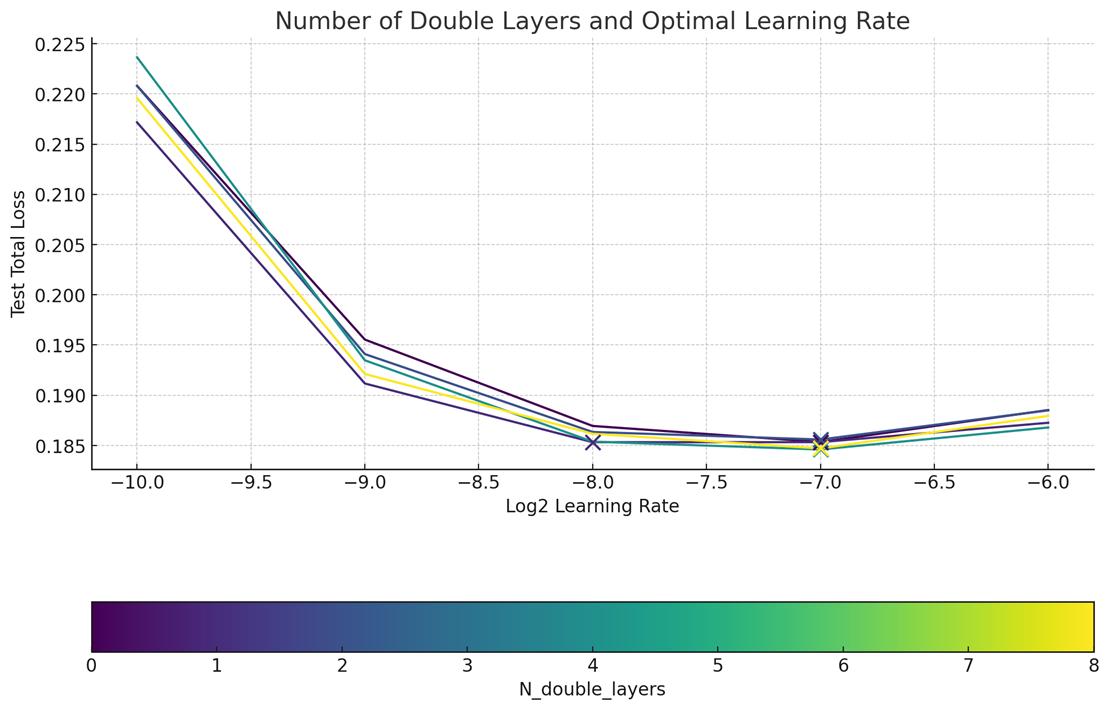
使用 torch.compile 改进训练:在 fal,我们已经是 Torch Dynamo + Inductor 的忠实粉丝,并在此工具(使用自定义 dynamo 后端)的基础上进行构建,以超快速度运行我们的推理工作负载(并有效利用底层硬件)。由于 PT2 的 torch.compile 能够处理前向和后向传递,AuraFlow 的训练通过其在每层前向方法上的原语得到了进一步优化,并且能够根据阶段将 MFU 额外提高 10% 至 15%。
解锁零样本学习率迁移
显然,我们不是 Meta,即使不扫描它们,我们也希望拥有非常好的超参数。幸运的是,我们注意到 MMDiT 架构也是零样本 LR 迁移,并且使用了最大更新参数化。与 SP 相比,muP 在大规模学习率的可预测性方面显然是赢家。
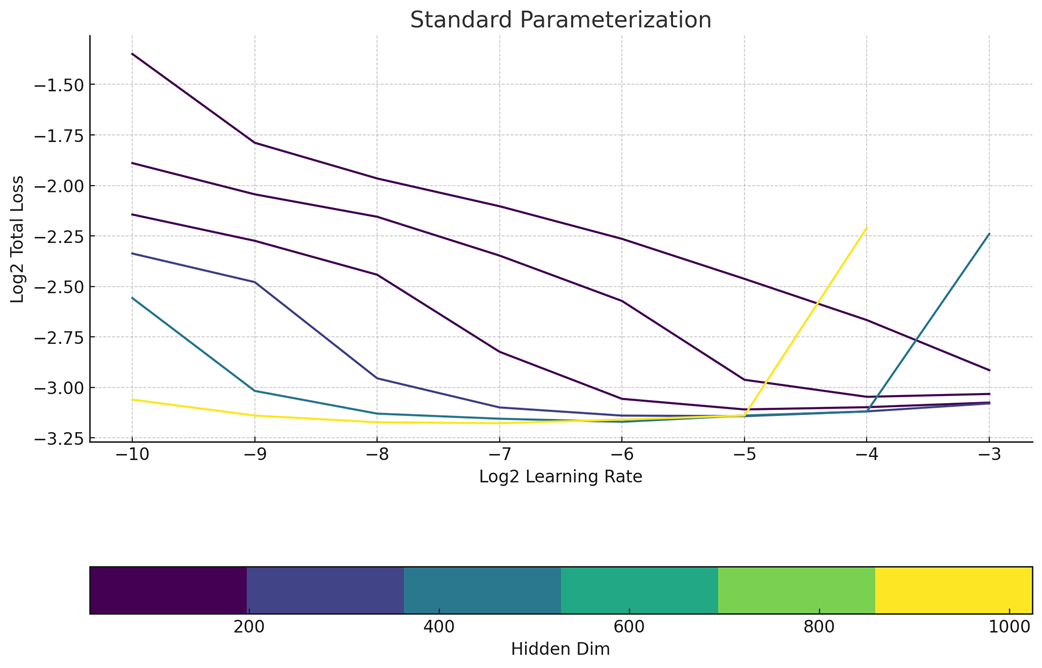
参数标准化
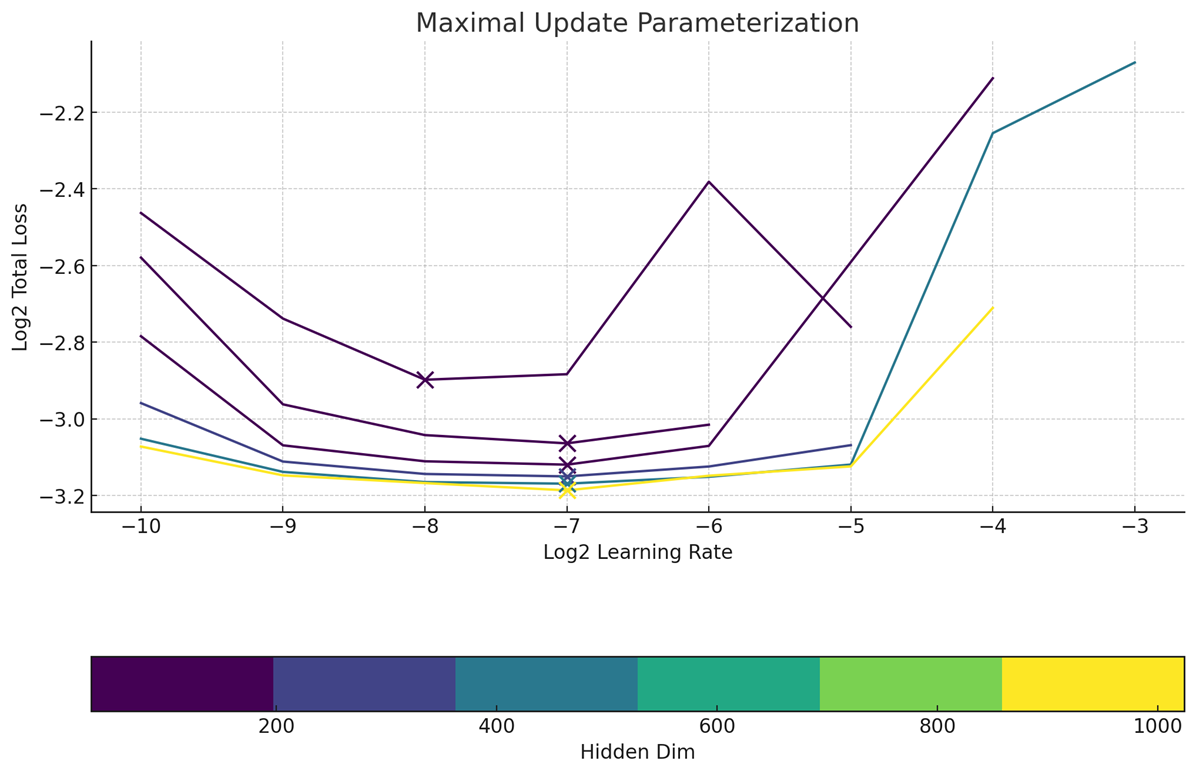
最大更新参数化
重新添加字幕所有内容
重新添加字幕是确保数据集中没有错误的文本条件的常用技巧。我们使用内部字幕和外部字幕数据集来训练这些模型,这显著提高了指令遵循的质量。我们极尽全力遵循 DALL·E 3 方法,并且没有使用替代文本的字幕。
更宽、更短、更好!
为了进一步研究最佳架构,我们有兴趣制作一个更胖的模型,即让架构整体利用可被 256 整除的最大 matmul。这导致我们在 muP 找到的最佳学习率下寻找最佳纵横比。根据这些发现,我们确信 20 ~ 100 的纵横比确实适合更大规模,这与自回归生成模型的缩放定律的发现相似。我们最终使用了 3072 / 36,导致模型大小为 6.8B 参数。
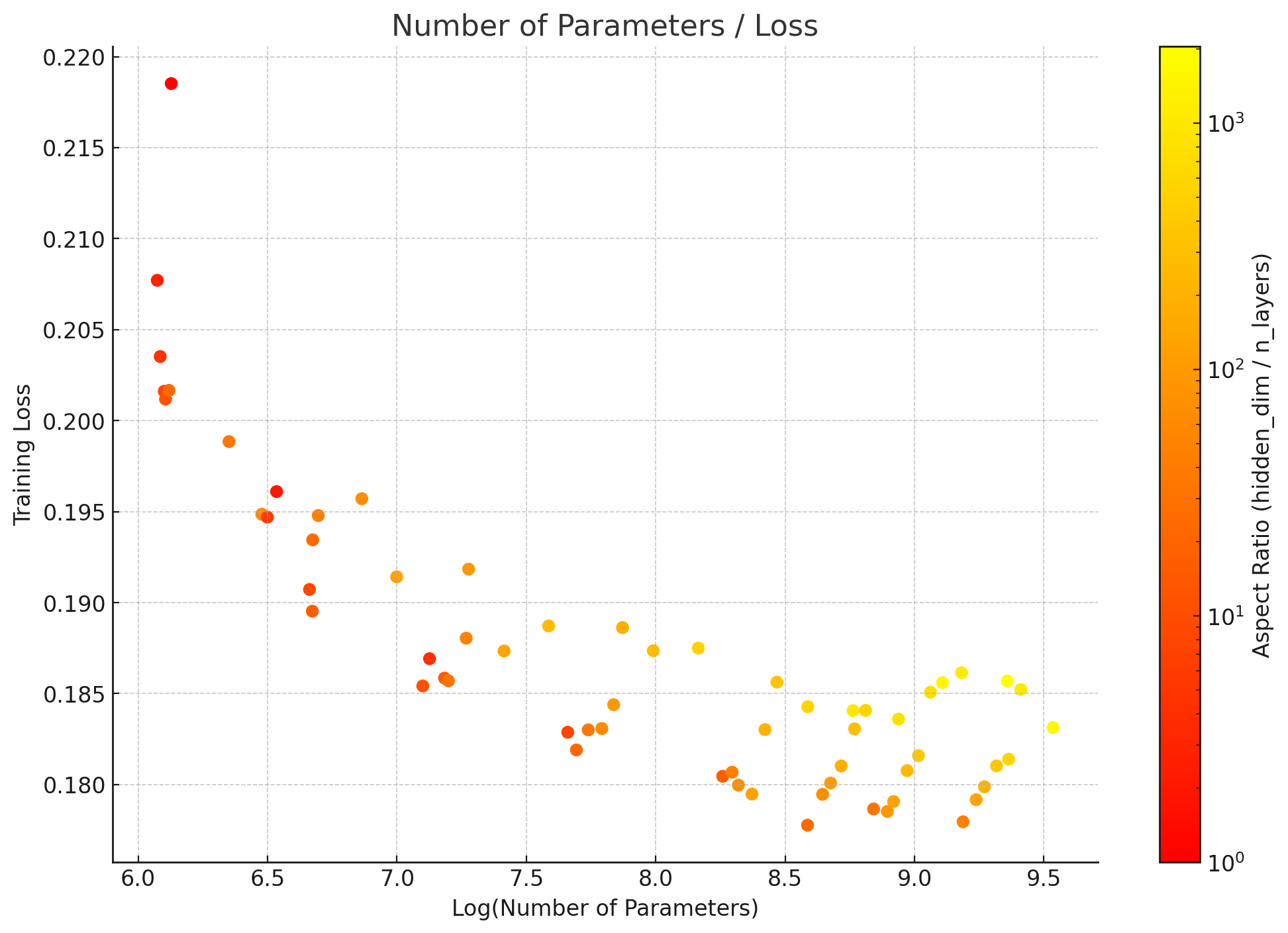
参数数量
最后,我们尽了最大努力来改进并有效地找到大规模训练的最佳配置。利用上述发现,我们能够在 4 周的计算时间内以尽可能大的设置从头开始训练文本到图像的模型,包括 256x256、512x512、1024x1024 预训练和长宽比微调。最终模型在预训练期间的 GenEval 得分为 0.63~0.67,在 1024x1024 预训练后同样达到 0.64。但使用类似于 DALL·E 3 的快速增强管道,我们能够达到 0.703!
多模态数据分布式训练的挑战
训练图像模型最严峻的现实之一是,与 LLM 不同,数据本身的形态可能非常难以处理。在 AuraFlow 的训练过程中,我们利用了处理分布式存储以及管理数千个 GPU 的专业知识。
其中一些专业知识可以直接从生产级推理/微调系统中转移,我们能够使用像JuiceFS这样的开源项目,而有些则是更新颖的挑战,例如如何在多个节点之间传输大量数据,同时利用本地 NVME 空间作为暂存区,以免减少 MFU。
下一步计划
我们还没有完成训练!此模型是初始版本,旨在启动一些社区参与。我们将继续训练模型并应用我们从第一次尝试中获得的经验。我们还注意到,较小的模型或 MoE 可能对计算能力有限的消费级 GPU 卡更有效,因此请密切关注模型的迷你版本,该版本仍然功能强大但运行速度要快得多。与此同时,我们鼓励社区尝试我们今天发布的内容。
我们的目标是使该模型成为其他创新工作可以在此基础上构建的标准主干。我们期待社区的贡献。















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









