






首次将状态空间模型引入到图像复原中,基于Mamba的图像复原基准模型,性能超越SwinIR
大佬近期使用状态空间模型Mamba来做图像复原的工作。
论文和代码都已开源,欢迎感兴趣的小伙伴关注
[论文链接]
https//arxiv.org/pdf/2402.15648.pdf
[代码链接]
https//github.com/csguoh/MambaIR
我们这个工作首次将状态空间模型引入到图像复原中。由于之前很少有相关的探索,因此为了更加深入理解,这里需要回答以下两个问题:
1. 为什么Mamba可以用来做图像复原?
首先我们来看一下状态空间模型的迭代表达式(这里直接把最终离散化后的结果给出了,详细推导可以参见Mamba的论文)
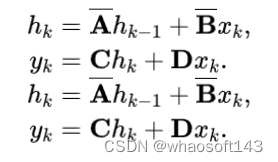
可以看到,状态空间模型采用了一种迭代的形式,首先从第0个时间步开始,按照上述公式进行迭代来得到之后时间步的预测。读到这里,大家可能会发现状态空间模型的表达式好像和RNN有点像啊。而从近几年的图像复原的模型中可以看到,很少有使用RNN来做图像复原主干的,因此我们很自然想到,使用Mamba(也是状态空间模型的一种)来做图像复原make sense吗?
实际上,上述迭代式是有特殊结构的,并在数学上可以化为卷积的形式,也就是说状态空间模型可以同时理解为RNN和CNN,而CNN对于图像复原则是很常见的模块,这也就为Mamba在图像复原中的应用奠定了基础。下面我们看一下将状态空间模型推导为CNN卷积形式的证明,更详细的证明可以看下Mamba的原始论文。

以上就是状态空间模型可以转化为卷积的证明,这也在理论上为Mamba在图像复原中的未来探索提供了支持。
当然在实际上我们的工作MambaIR的工作也是在此基础上进行了改进,包括
- 使用Mamba中的策略——由输入生成卷积权重(类似于动态卷积,所以表达能力还是很强的)
- 使用四个方向的扫描,让当前像素的输出实际上是来自上下左右四个方向邻域的一维卷积结果
2. 既然可以做,那么效果怎么样呢?
首先谈一下个人感受,我们提出的MambaIR是一个很简单的Baseline,并没有引入十分复杂的设计,对比同样简单的基于Transformer的图像复原基准模型SwinIR,我们的MambaIR是要比SwinIR明显要高的(见下图)。因此,不难想见,未来针对Mamba做特定设计将会进一步提升基于Mambda的图像复原模型的能力。
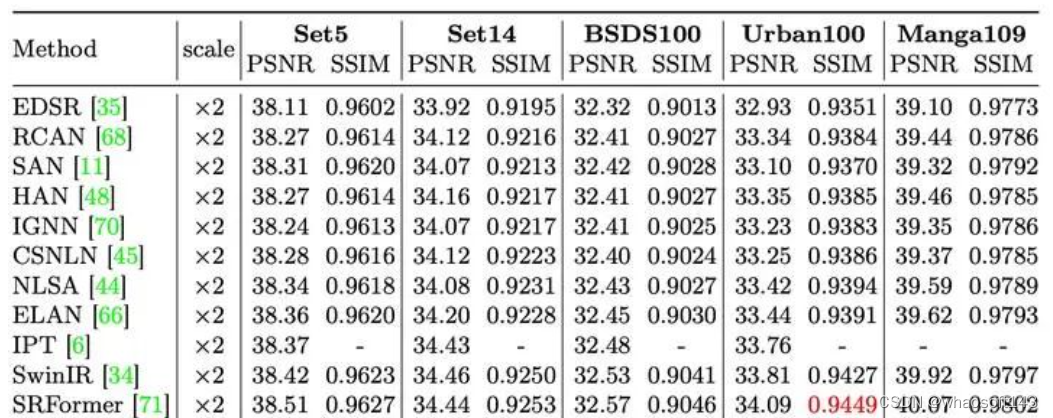
经典图像超分x2倍率实验结果
动机
Transformer模型已经在底层视觉领域取得了十分瞩目的成果,例如IPT,SwinIR等等。最近随着先进的状态空间模型Mamba的出现以及其在NLP中的喜人表现,使用Mamba来做各类视觉任务变得十分有趣。
对于图像复原任务来说,我们总结出Mamba相较于之前的CNN和Transformer具有如下优势:
- 对于CNN来说,CNN具有静态权重以及局部感受野,这大大限制了模型利用更多像素的能力,正如HAT指出的那样。而Mamba则具有全局的感受野,可以以整个图像作为token序列作为输入。
- 对于Transformer来说,虽然标准的注意力机制具有全局感受野,但是在图像复原任务中使用这一机制将会带来无法接受的计算代价,因此为了折中,目前的工作大多使用了SwinTR的机制,但是这同样限制了感受野同时window的边缘也容易产生伪影。
下面是MambaIR与基于CNN的方法(EDSR,RCAN)和基于Transformer的方法(SwinIR,HAT)在有效感受野上的对比结果,可以看到MambaIR具有正幅图像范围的感受野,从而可以更加充分地利用图像块重复先验。

有效感受野对比
方法
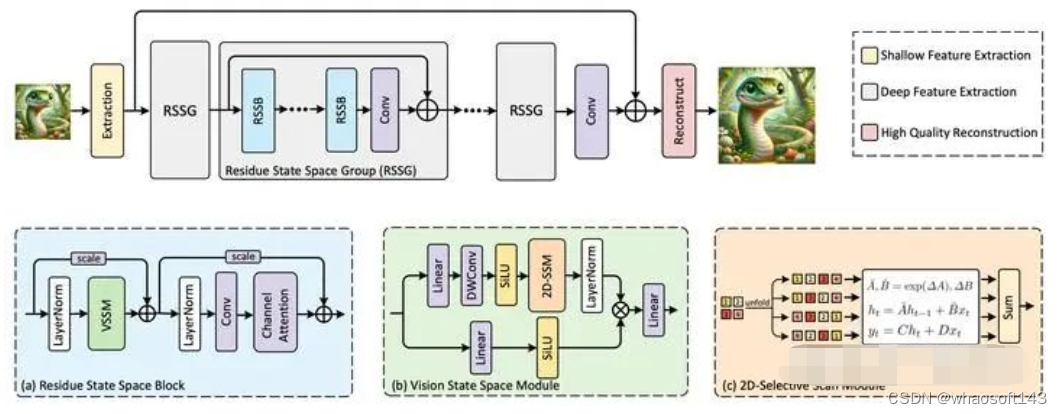
首先需要指出的是,我们MambaIR的主要目的是提出一个简单的baseline模型,并方便之后的进一步研究改进。因此在模型设计上,我们遵循了之前图像复原任务的大致流程,即浅层特征提取,深层特征提取,以及高质量图像重建。
这里简单介绍MambaIR的核心组建,残差状态空间模块(Residual State-Space Block,RSSB)
对于特征X,其首先经过LayerNorm以及视觉状态空间模块(VSSM)来建模空间维度上的远程依赖,并伴随着可学习的scale参数来调整来自残差连接中的权重:
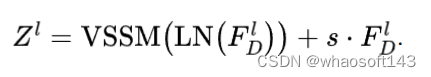
其中VSSM模块通过使用四个方向的扫描来将2D图像转化为1D输入序列,并使用前面的离散化的迭代公式进行建模。关于该模块的具体细节可以参考原论文。
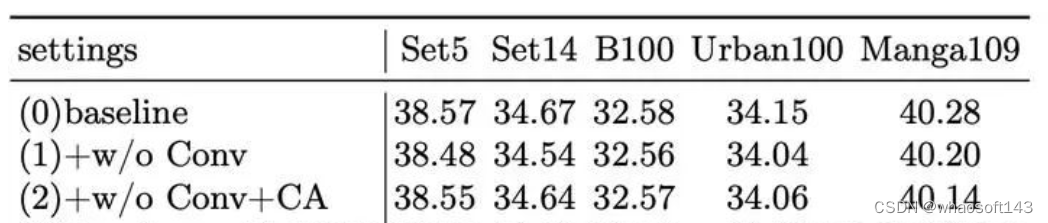
此外,在实验中我们同样也和原始的Mamba的作者那样,发现在Mamba后面加MLP甚至会带来性能的下降。为了进一步补充标准的Mamba的建模能力,我们进一步考虑了两个图像复原的特定先验:
- 局部邻域重复:我们使用卷积来补充邻域像素的相似性
- 通道交互:我们引入通道注意力来补充空间维度的交互
最终实验结果也发现我们引入的这两种先验比标准的Mamba性能更好,比简单地使用MLP的性能也更好。具体消融实验结果如下:
结语
尽管目前针对Mamba的各类任务模型已经在不断涌现,但是目前这一任务仍然存在着较大的改进空间。相信未来随着大家对Mamba认知的加深,可以有更多更好的工作出现。我们MambaIR的工作还在持续更新中,之后会包含更多的复原任务















 2081
2081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









