






学习目标:
- 从不同的角度更好地优化神经网络
-
- 熟悉临界点等与优化有关的常见的概念
- 网络优化失败的常见原因
- 常用的解决/优化方案
具体内容:
网络优化常见的问题?
损失函数Loss不再下降,但是收敛值不合理
- 深层网络反而不如浅层网络
- 一开始就训练不起来,无论怎样更新参数,loss降不下去
背后的原因?
-
- 更新到了临界点附近,临界点即梯度为0的点
- 临界点:局部极值点和鞍点。
- 怎么走出鞍点或者局部极小值点呢
解决方案?
mini-batch gradient descent, mini-BGD
自适应优化方向:动量法
自适应学习率
mini-BGD
mini-BGD:起作用的关键在于有多个Loss,一个Loss陷入临界点了,另一个Loss更新的时候会跳出。
不同BatchSize下的时间效率(一次更新or一个回合)对比?
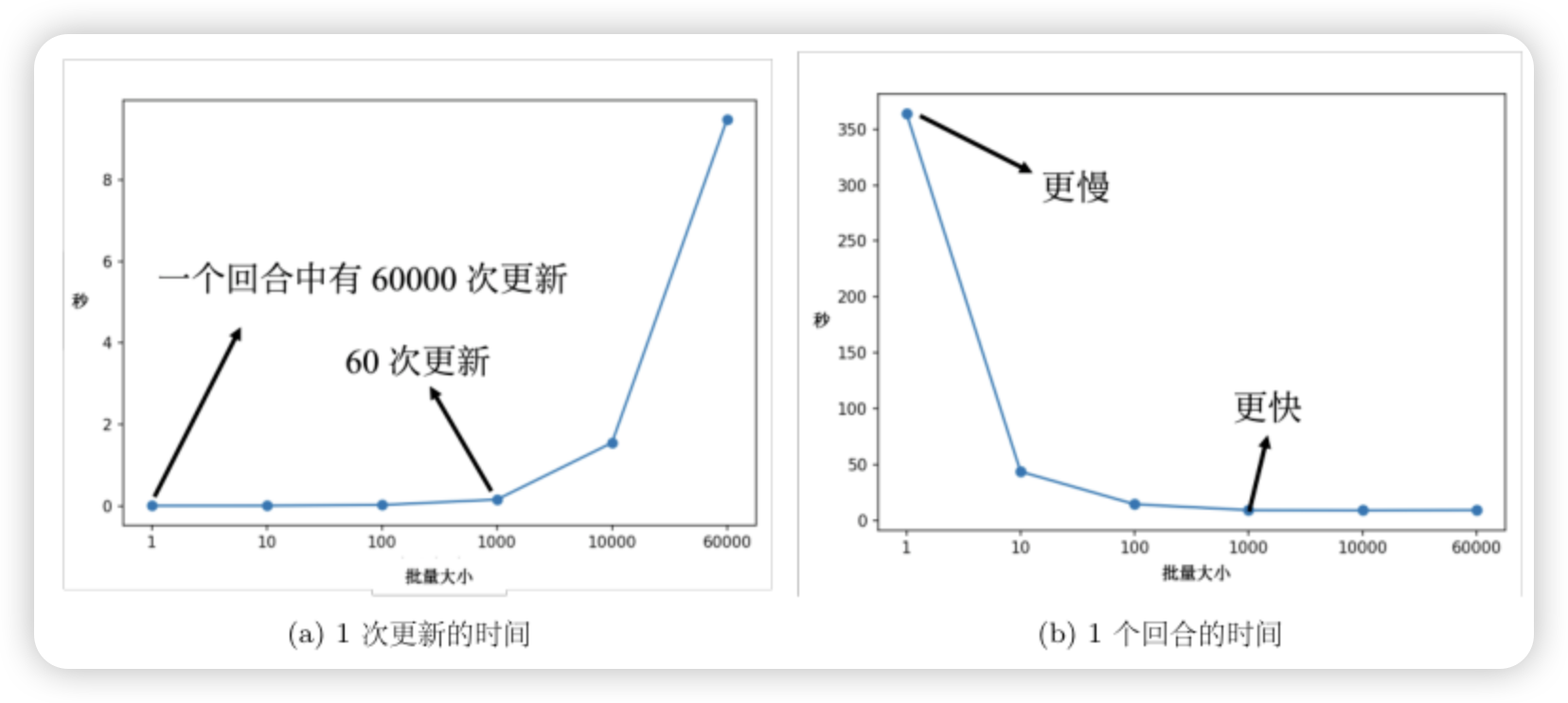
因此从效率上讲,一般不会采用 SGD。那么BGD 和 m-BGD该怎么选呢?以及如果选了m-BGD,BatchSize 怎么设定呢?
结论:

论据:
-
一定范围之后,batch_size 越大,准确率越低(both 训练集and测试集)。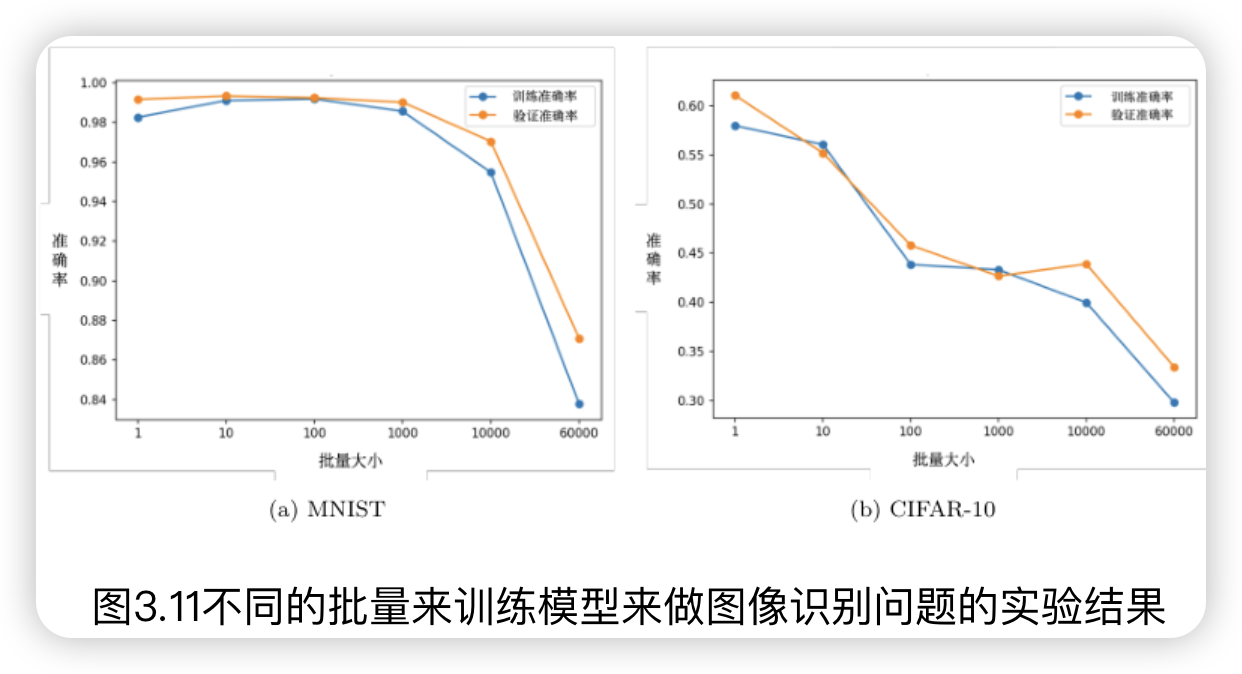
- 在论文“On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima"中,作者在不同数据集上训练了六个网络(包括全连接网络、不同的卷积神经网络),在很多不同的情况都观察到一样的结果。在小的批量,一个批量里面有256笔样本。在大的批量中,批量大小等于数据集样本数乘0.1。比如数据集有60000笔数据,则一个批量里面有6000笔数据。大的批量跟小的批量的训练准确率(accuracy)差不多,但就算是在训练的时候结果差不多,测试的时候,大的批量比小的批量差,代表过拟合。
- 解释:局部最小值有好最小值跟坏最小值之分,如果局部最小值在一个“峡谷”里面,它是坏的最小值;如果局部最小值在一个平原上,它是好的最小值。大的批量大小会让我们倾向于走到“峡谷”里面,而小的批量大小倾向于让我们走到“盆地”里面。小的批量有很多的损失,其更新方向比较随机,其每次更新的方向都不太一样。即使“峡谷”非常窄,它也可以跳出去,之后如果有一个非常宽的“盆地”,它才会停下来(鲁棒性好,不同Batch对应的不同L,也大多都收敛到这里,接近全局极小值;测试集也更容易有好的表现)
使用大的Batch训练出的结果一定差吗?有没有办法即使用了大批量保证了时间效率又能训练出一个不错的结果呢?
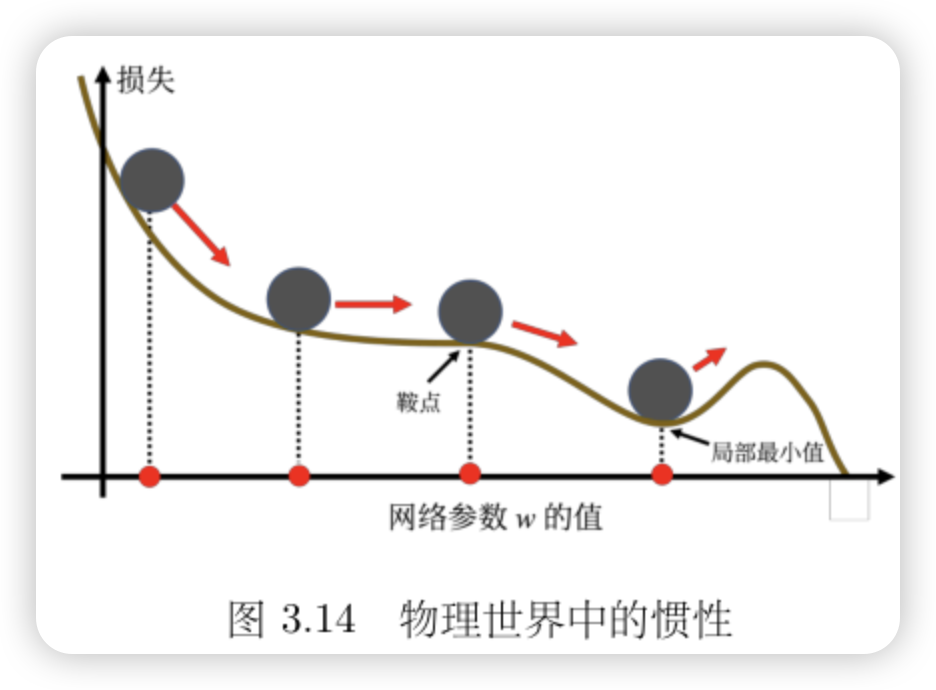
动量法
在物理的世界里面,一个球从高处滚下来的时候,如果动量够大,很可能会跳出鞍点或局部最小值点,如果将其应用到梯度下降中,这就是动量
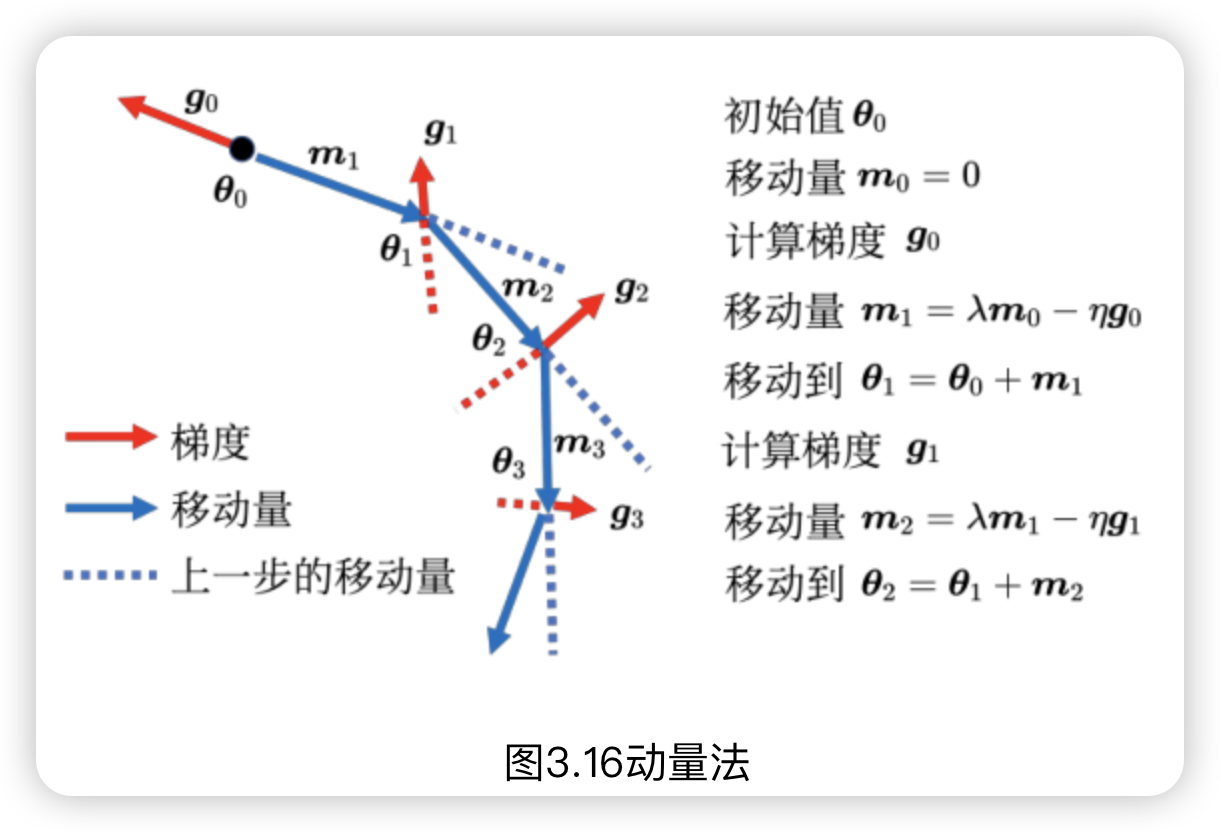
自适应学习率
很多时候,Loss降不下去,但是梯度仍然很大,是因为进入到了峡谷形态。如图
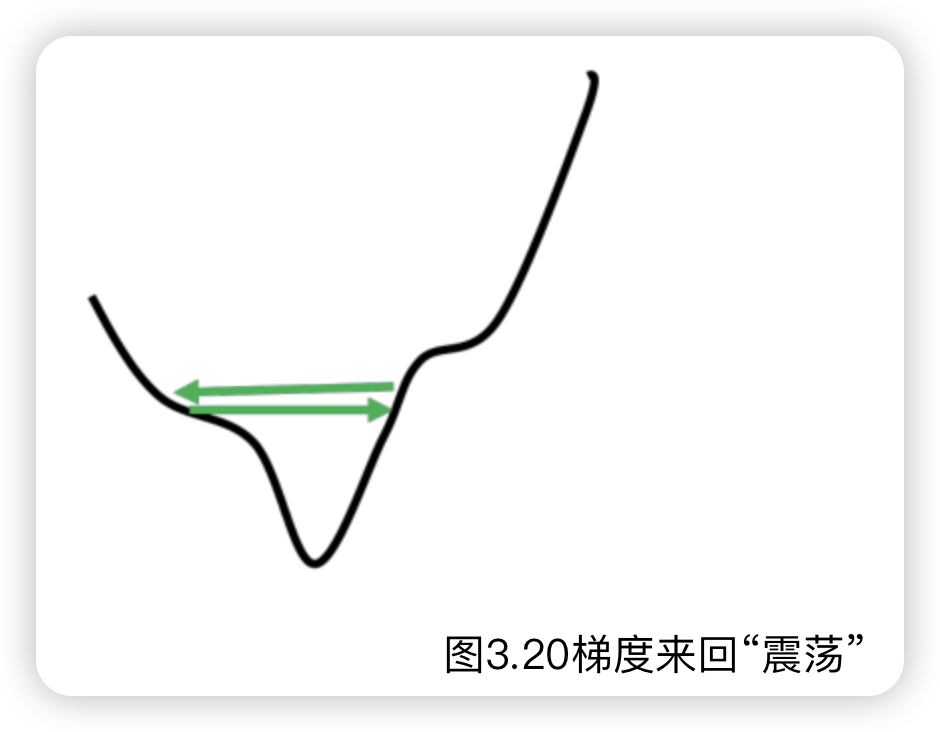
如果来到了比较陡峭的位置,希望更新的步长小一点;反过来,如果来到了峡谷中的平坦位置,希望更新的步长大一点。即:自适应的系数应该和梯度成反比。
AdaGrad
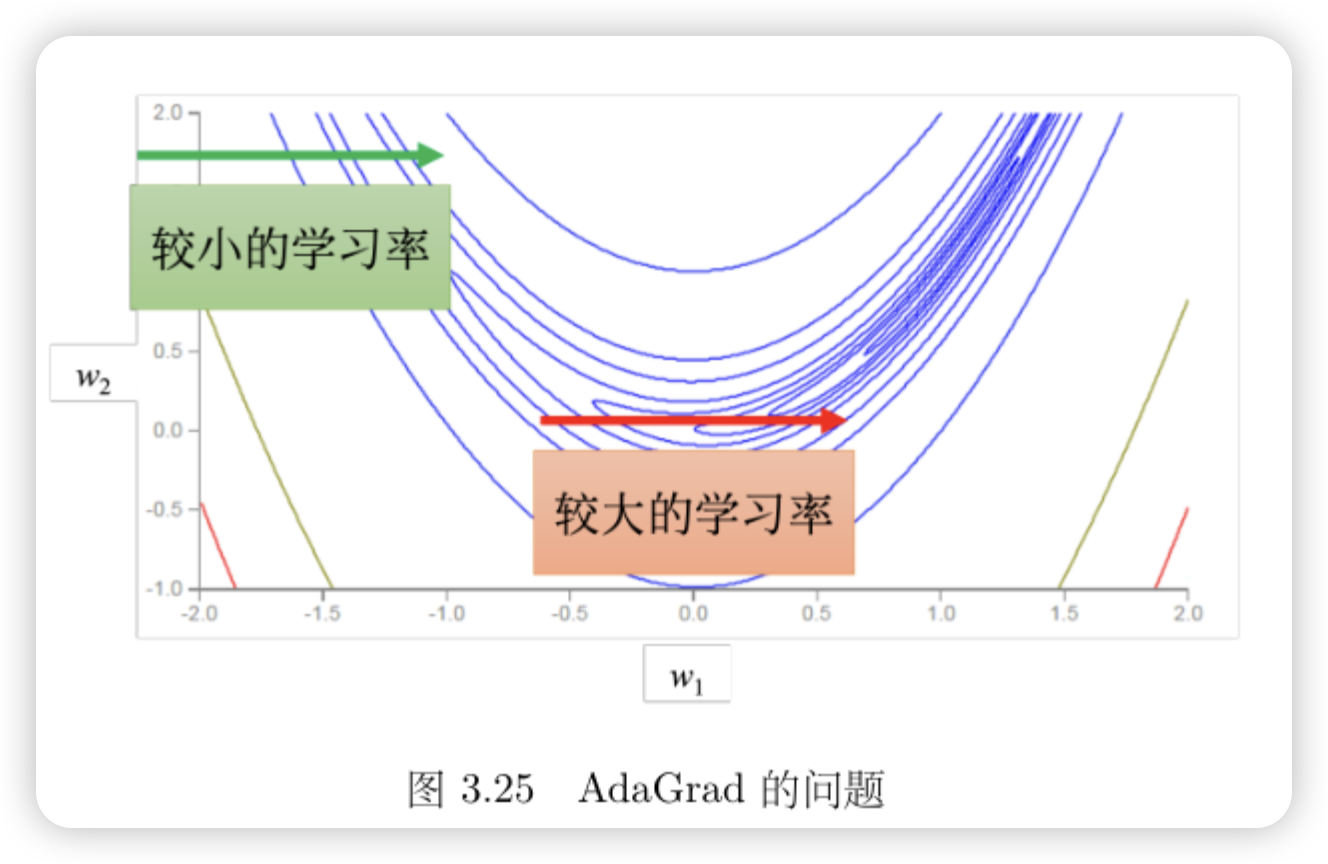
考虑不同参数需要不同的学习率


RMSProp
额外考虑同一个参数在不同时间,也需要不同的学习率

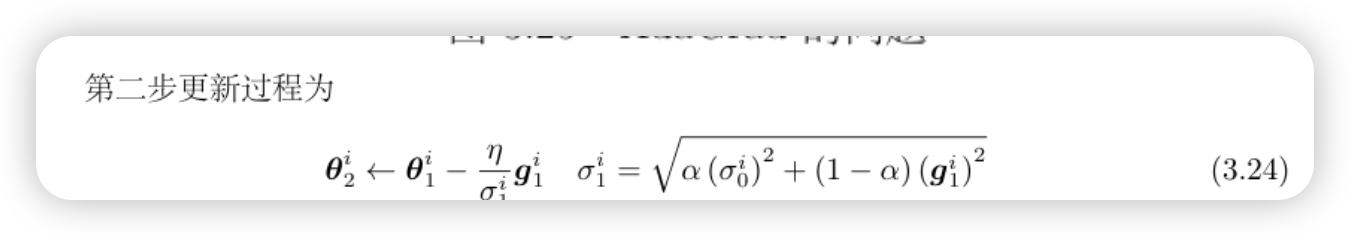
Adam
动量法 + RMSProp
学习率调度
为什么需要学习率调度?
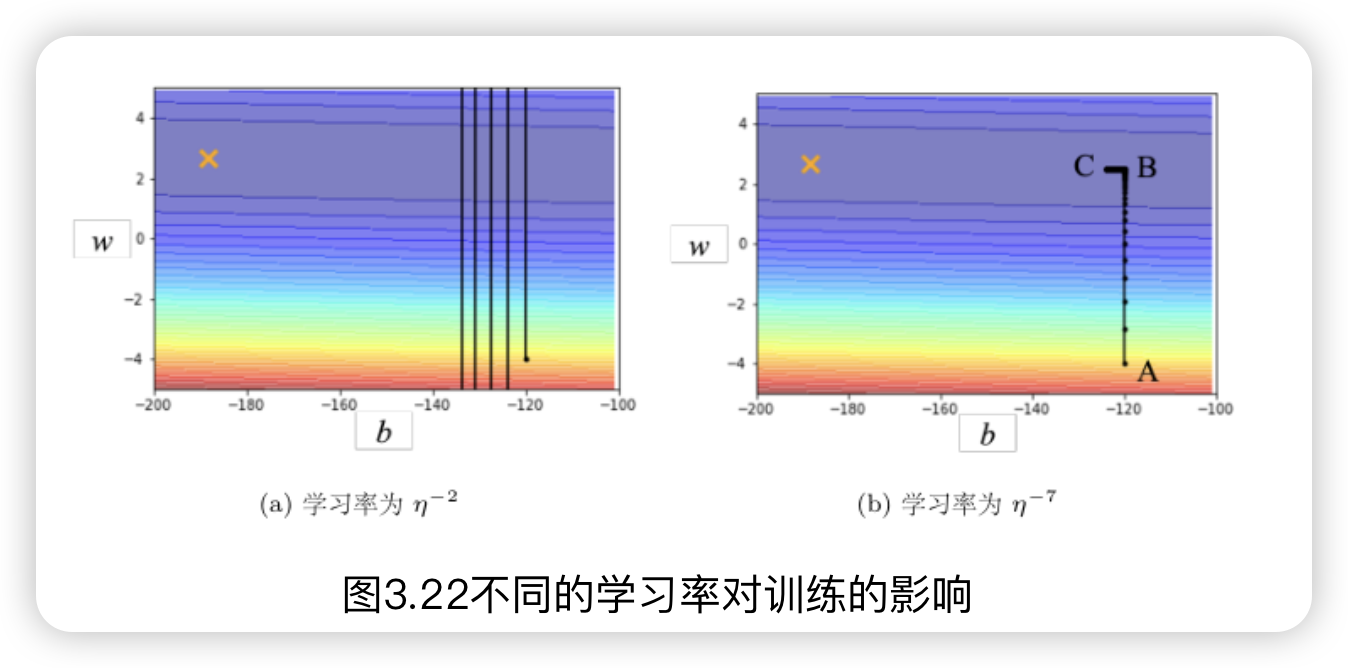
加快收敛速度:合适的学习率调度可以使模型更快地收敛到最优解。如果学习率过大,模型可能错过最低点;如果过小,收敛速度会很慢。但较小的学习率有更大的概率走到最低点(最优解),一般的训练策略是开始使用大的学习率然后随着模型的拟合不断调小学习率,使模型达到最优解
学习率调度的常用方案?
预热和学习率衰减















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









