






说明:以下内容引用黑马,如有侵权请联系删除
第一章 全文检索Lucene
检索:查询(以少查多)
1.1 基本概念
数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件。
结构化数据查询

结构化数据的查询:
- 数据库中数据存储有规律的,有行有列而且数据格式、数据长度都是固定的。
- 通过添加索引等手段,保证查询效率
- 针对模糊查询:如果其左侧有%,索引失效存在效率问题
- 对于复杂词汇,不能分词处理。
非结构化数据查询
(1)顺序扫描法(Serial Scanning)
所谓顺序扫描:依次查询每个文档中的所有内容,是否包含给定的词汇。如利用windows的搜索也可以搜索文件内容,效率极低。
(2)全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
倒排索引


正向:由诗名想到诗句
反向:由诗句想到诗名
倒排索引:将文档中的内容进行分词,形成词条。然后记录词条和数据的唯一表示(id)的对象关系,形成的产物即为倒排索引(词条和数据之间的关系)。
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大
1.2 全文检索Lucene
Lucene是apache 下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
1.3 全文检索的应用场景
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
1.4 Lucene的执行流程
Lucene : apache提供的全文检索引擎。
索引和搜索的流程图

1、左侧对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容–>采集文档–>创建文档–>分析文档–>索引文档
2、右侧表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面–>创建查询–>执行搜索,从索引库搜索–>渲染搜索结果

创建索引
我们以一个招聘网站的搜索为例,比如说智联招聘,在网站上输入关键字搜索显示的内容不是直接从数据库中来的,而是从索引库中获取的,网站的索引数据需要提前创建的。以下是创建的过程:
- 获得原始文档:就是从mysql数据库中通过sql语句查询需要创建索引的数据
- 创建文档对象,把查询的内容构建成lucene能识别的Document对象获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),这个域对应就是表中的列。注意:每个Document 可以有多个Field,不同的 Document 可以有不同的Field,同一个Document可以有相同的Field (域名和域值都相同)
每个文档都有一个唯一的编号,就是文档id。 - 分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。分好的词会组成索引库中最小的单元: term,一个term由域名和词组成 - 创建索引,对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
查询索引
查询索引也是搜索的过程。搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档
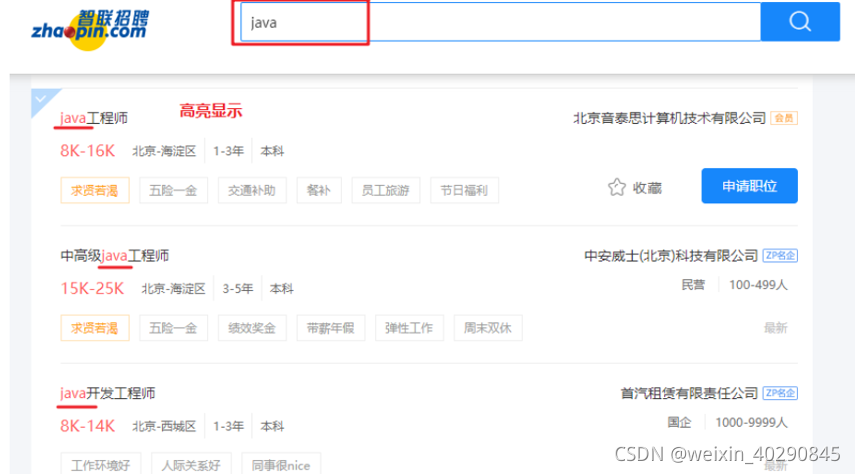
- 创建用户接口:用户输入关键字的地方
- 创建查询指定查询的域名和关键字
- 执行查询
- 渲染结果(结果内容显示到页面上关键字需要高亮)
第二章 Elasticsearch介绍和安装
2.1 简介
简介

- Elasticsearch是Elastic公司提供的一个基于Lucene的搜索服务器
- 是一个分布式,高扩展,高实时的搜索与数据分析引擎
- 基于RestFull的web调用接口,大大简化搜索开发流程
- Elasticearch是用java语言开发的,开源的目前极其流行的企业级搜索引擎
- Elastic官网: https://www.elastic.colcnl

与数据库对比
- MySQL有事务,而Elasticearch没有事务,所以删除的数据无法恢复
- Elasticearch没有外键的特性
- MySQL注重数据的一致性和持久,Elasticearch提供便捷,搞笑的检索查询

2.2 安装Elasticsearch
es服务器的版本:6.2.4 (7.x)
win10环境下
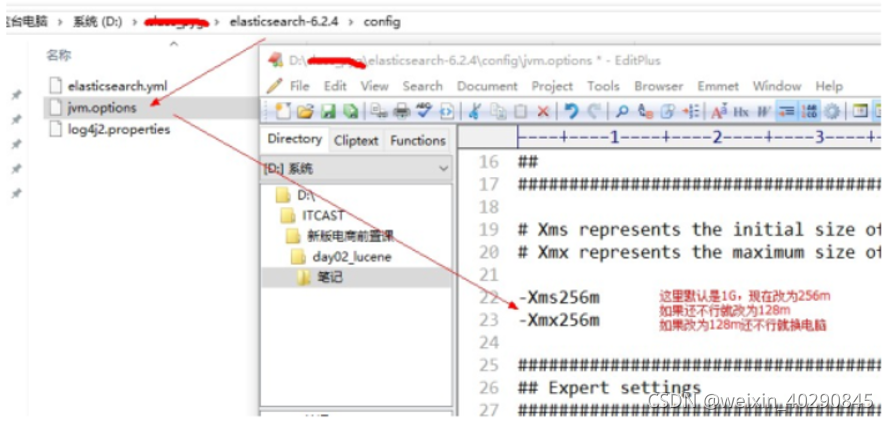
(3)修改内存占用大小
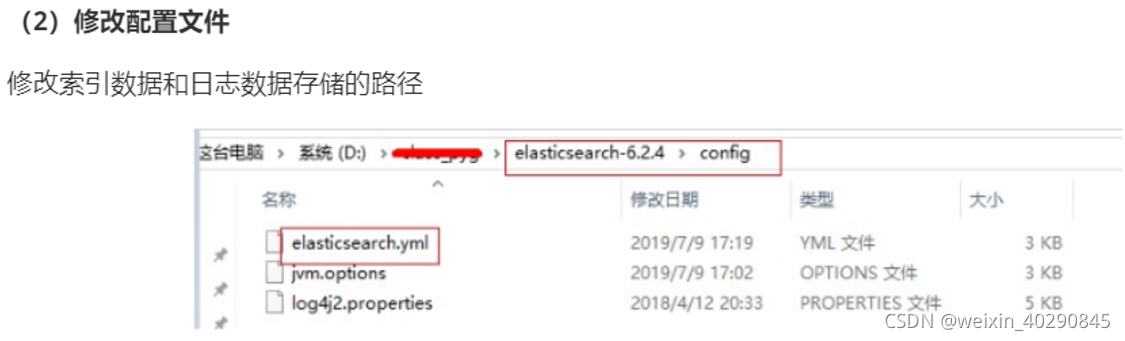
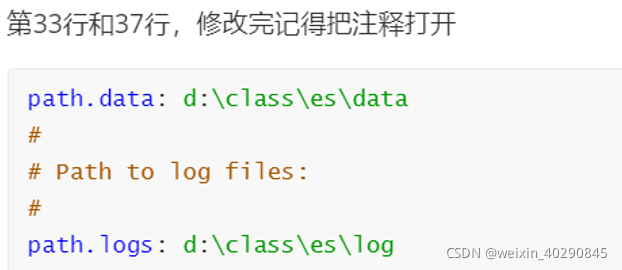
练习阶段为了防止内存占用过多导致的启动失败,推荐修改虚拟机内存。找到安装目录config/jvm.options文件如图修改
(5)测试访问
双击elasticsearch.bat启动之后,后台输入如下内容
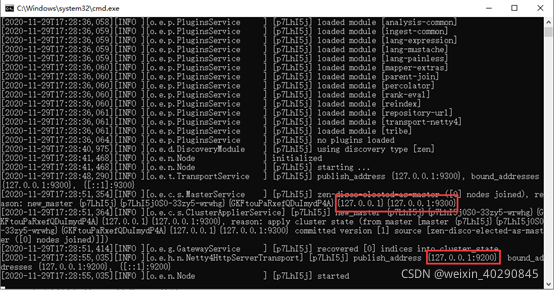
- 可以看到绑定了两个端口:
- 9300:集群节点间通讯接口,接收tcp协议
- 9200:客户端访问接口,接收Http协议
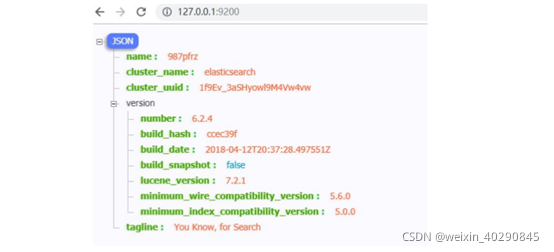
- 我们在浏览器中访问: http://127.0.0.1:9200
Linux环境下安装
(1)上传包到指定目录

(2)解压包到指定目录
tar -zxvf /package/elasticsearch-6.2.4.tar.gz -C /es/
(3)查看
(4)修改配置文件
进入到es安装目录下的config文件夹中,修改elasticsearch.yml 文件
#配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-es
#节点名称
node.name: node-1
#设置索引数据的存储路径
path.data: /es/data/
#设置日志的存储路径
path.logs: /es/log
#设置当前的ip地址,通过指定相同网段的其他节点会加入该集群中
network.host: 0.0.0.0
#设置对外服务的http端口
http.port: 9200
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
discovery.zen.ping.unicast.hosts: ["127.0.0.1","10.10.10.34:9200"]
network.host: 0.0.0.0
修改Elasticsearch的配置,使其支持外网访问。在浏览器中,访问http://xxxx:9200/(xxxx是运行elasticsearch的服务器的ip地址)即可。否则这可以在本机使用。
(5)ES root用户启动失败can not run elasticsearch as root
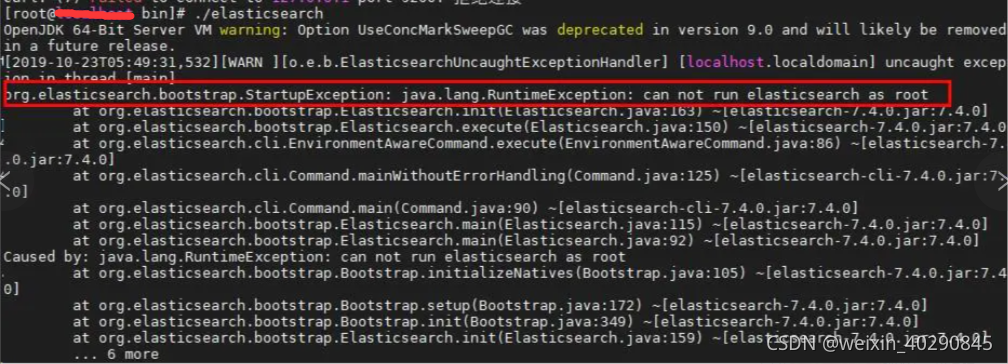
es 因为安全问题拒绝使用root用户启动
解决方案
- 添加用户组es,及用户es 密码password
- 给用户es:es添加指定目录拥有权限
groupadd es
useradd es -g es -p password # -g 指定组 -p 指定密码
chown -R es:es /es # -R : 处理指定目录下的所有文件
切换到用户,并执行es
su es
cd /es/elasticsearch-6.2.4/bin/
./elasticsearch
./elasticsearch -d # 后台方式启动
(6)启动报错

解决办法
vim /etc/security/limits.conf
添加如下:
* soft nofile 65536
* hard nofile 131072
es soft nproc 4096
es hard nproc 4096
2.3 安装kibana
什么是Kibana
- Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具;
- 利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
- 提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
win10安装
一路next
解压即可
(3)配置运行
进入安装目录下的config目录,修改kibana.yml文件:修改elasticsearch服务器的地址:
elasticsearch.url: "http://192.168.1.10:9200"
(4)运行

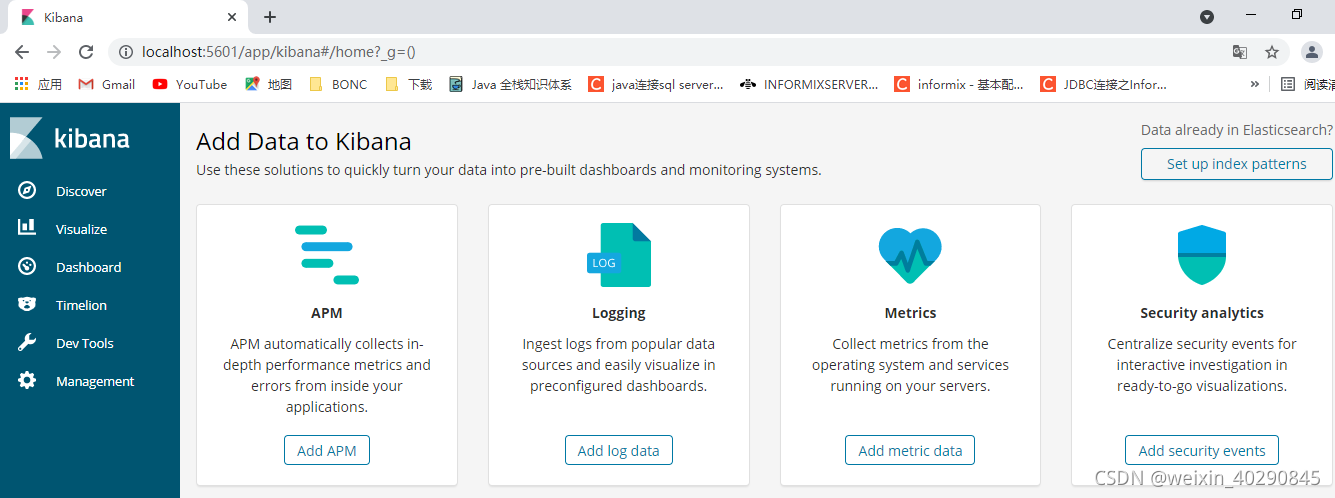
控制台
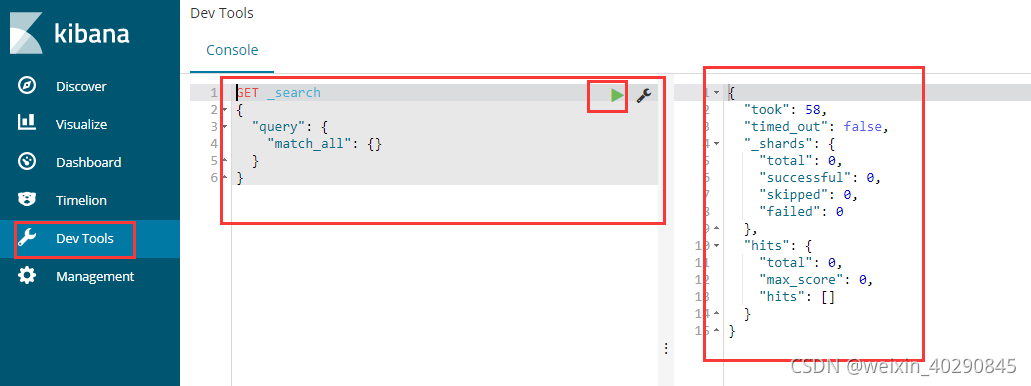
2.4安装ik分析器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为Elasticsearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致,最新版本:6.2.4
https:/lgithub.com/medcl/elasticsearch-analysis-ik
安装
(1)解压elasticsearch-analysis-ik-6.2.4.zip后,将解压后的文件夹拷贝到elasticsearch-6.2.4\plugins下,并重命名文件夹为ik

(2)重启es
(3)测试
在kibana控制台输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
第三章 使用kibana对索引库操作
3.1 基本概念

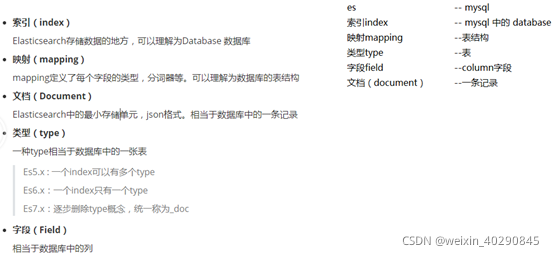
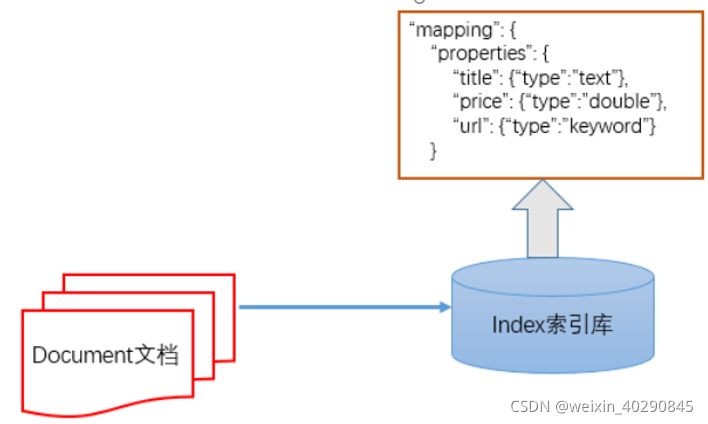















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











