







记录一下自己的学习过程。
有很多省份的数据,想要求全国的综合。这些数据都分别存在csv里。如下:
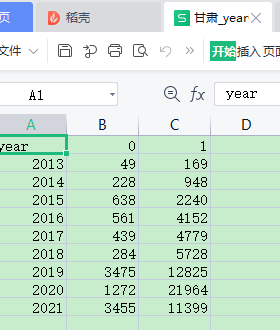
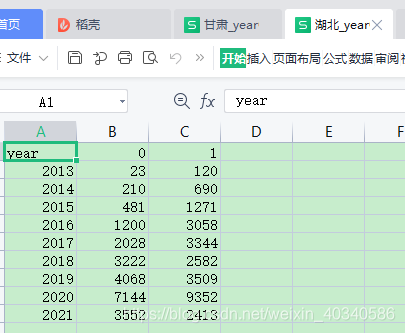
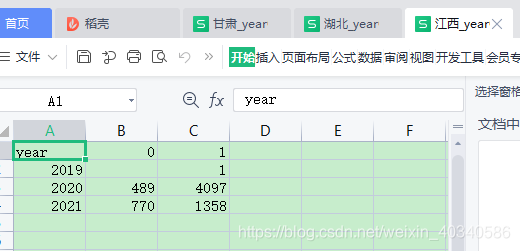
我希望把全部省份加起来, 算一个全国总和。这时候需要用到数据表对应值相加。
代码如下:
先读进来一个数据表,比如
df1 是湖北的。
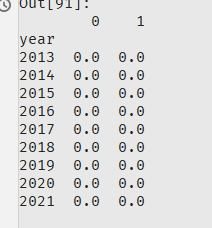
在df1 的基础上创建一个空表。
df_empty = pd.DataFrame(np.zeros(df1.shape), columns=df1.columns, index=df1.index)
这样df_empty是
然后写一个for循环,逐个加进来。
for i in range(len(result_list)):
print("\n************\n")
print(result_list[i])
print(prov_list[i])
dfi = pd.read_csv(os.path.join(result_data_dir, result_list[i]), index_col='year')
print(dfi)
dfi = dfi.fillna(0)
print(i)
df_empty = df_empty.add(dfi, fill_value = 0)
print(df_empty)中间有很多打印的内容,其实关键的是其中两句。
dfi = pd.read_csv(os.path.join(result_data_dir, result_list[i]), index_col='year') 这一句保证读进来的数据索引相同,列相同。
相加,
df_empty = df_empty.add(dfi, fill_value = 0)
这一句可以让数据表相加,相当于矩阵的点加。
得到最后结果如下
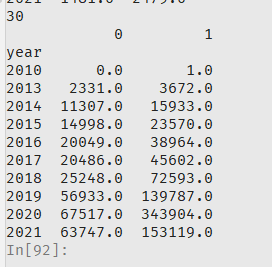
其中fill_value=0,不能省略,因为如果不加,那么add的时候,会把一些有缺失的格变成缺失,最后加起来会有很多缺失。
看样子原来没有的行,比如2010,会自动添加进去。总和数据表里多了2010这一行。

















 1787
1787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









