








目录
一、Spark框架概述
1、Spark简介
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面,Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。在处理大规模数据集时,速度是非常重要的。速度快就意味着我们可以进行交互式的数据操作,否则我们每次操作就需要等待数分钟甚至数小时。Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上进行的复杂计算,Spark 依然比 MapReduce 更加高效。

DataBricks官网: About Spark – Databricks

Apache官网:Apache Spark™ - Unified Engine for large-scale data analytics
2、发展
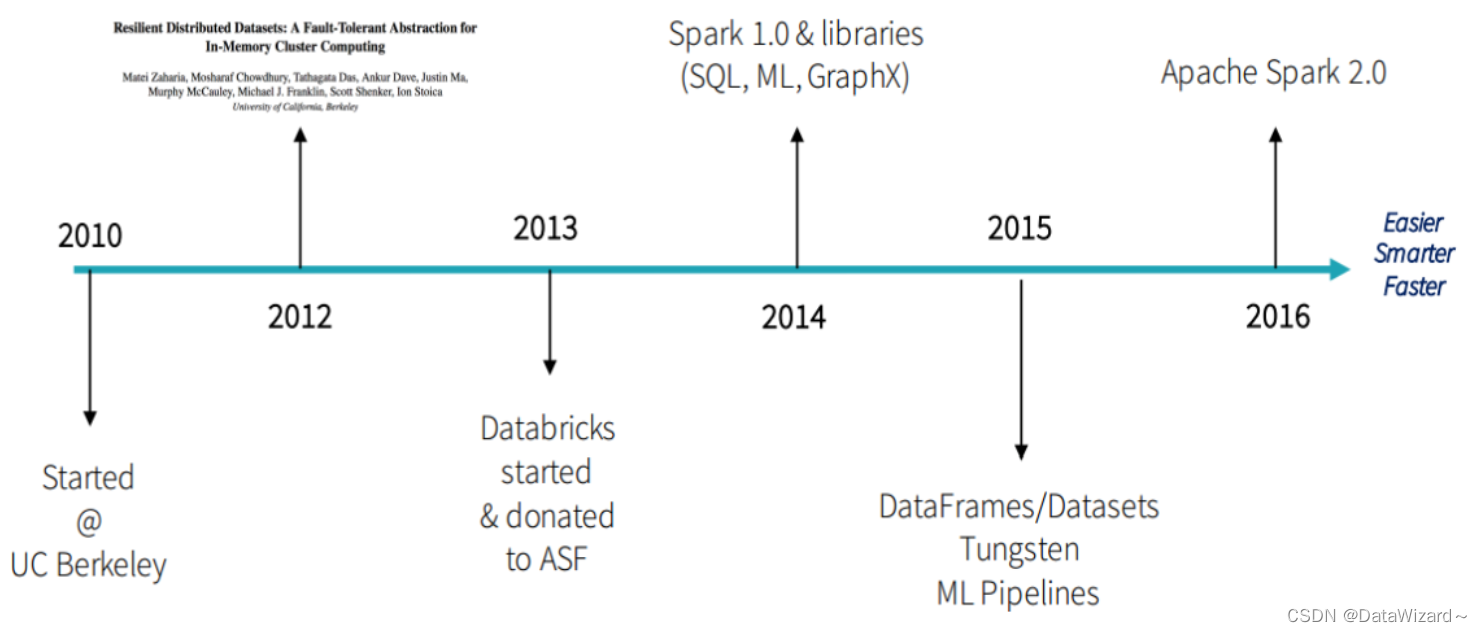
- 2009年Spark诞生于伯克利AMPLab,伯克利大学的研究性项目
- 2010年通过BSD 许可协议正式对外开源发布
- 2012年Spark第一篇论文发布,第一个正式版(Spark 0.6.0)发布
- 2013年Databricks公司成立并将Spark捐献给Apache软件基金会
- 2014年2月成为Apache顶级项目,同年5月发布Spark 1.0正式版本
- 2015年引入DataFrame大数据分析的设计概念
- 2016年引入DataSet更强大的数据分析设计概念并正式发布Spark2.0
- 2017年Structured streaming 发布,统一化实时与离线分布式计算平台
- 2018年Spark2.4.0发布,成为全球最大的开源项目
- 2019年11月Spark官方发布3.0预览版
- 2020年6月Spark发布3.0.0正式版
二、Spark功能及特点
1、定义
优先基于内存计算的同一化的数据分析引擎
2、功能及模块
- Spark Core:Spark最核心模块,可以基于多种语言实现代码类的离线开发
- Spark SQL: 类似于Hive,基于SQL进行开发,SQL会转换成SparkCore离线程序
- Spark Streaming:基于SparkCore之上构建了准实时的计算模块
- Spark MLlib:机器学习算法库,提供各种机器学习算法工具,可以基于SparkCore或者SparkSQL实现开发
- Spark Graphx:图计算库
3、适用场景
所有需要对数据进行分布式的查询、计算、机器学习都可以使用Spark来完成
4、开发语言
Python、SQL、Scala、Java、R【Spark源码是Scala语言开发的】
5、官方特点

- Batch/Streaming data:统一化离线计算和实时计算开发方式,支持多种开发语言
- SQL analytics:通用的SQL分析快速构建分析报表,运行速度快于大多数数仓计算引擎
- Data science at scale:大规模的数据科学引擎,支持PB级别的数据进行探索性数据分析,不需要使用采样
- Machine learning:可以支持在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到数千台机器的集群上
- 整体:功能全面、性能前列、开发接口多样化、学习成本和开发成本比较低
三、Spark的应用及使用
1、应用场景
- 离线场景:实现离线数据仓库中的数据清洗、数据分析等应用。
- 实时场景:实现实时数据处理,相对而言功能和性能不是特别完善,工作中建议使用Flink做实时计算。
2、开发语言
- 官方推荐用户使用SparkSQL
- 实际工作中:Python SQL Scala Java
3、运行模式
- 本地模式(Local)
- Local:不是分布式,只是在本地启动一个进程来运行所有任务,一般用于测试环境
- 集群模式(Cluster 四种)
- Standalone:spark自带的一个集群模式,类似于Hadoop自带了YARN
- Mesos:类似于YARN的工具,独立的一个工具,用的比较少
- YARN:将Spark程序提交给YARN运行,国内主要使用的模式
- K8s:基于容器集群构建Spark程序运行,有一些公司在使用
四、Spark的计算流程设计
1、设计流程
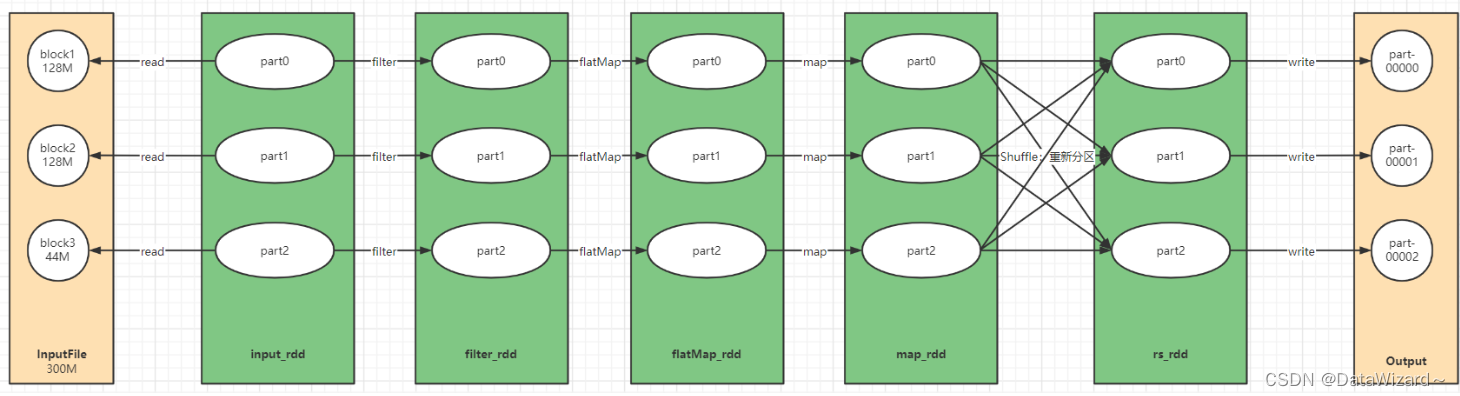
- 读取数据:将指定的数据源的数据封装到一个RDD对象中
- 处理数据:通过RDD调用算子(函数)进行处理,类似于对列表中的数据调用函数进行处理
- 保存结果:将每个Task计算的结果进行输出保存
2、理解RDD和python中的List区别
- List:存放多个元素的集合,但节点的
- RDD:存放多个元素的集合,分布式的
3、为什么Spark比MapReduce快
- Spark支持DAG,一个Spark程序中可以有多个Map和多个Reduce,多个Map之间的中间结果直接放在内存中
- Spark Shuffle更加智能化,可以根据数据量来自由选择Shuffle过程
- Spark中Task是线程级别的,进程只申请启动一次,所有新的Task任务都直接分到进程中运行















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









