







支付宝面试考察技术点
-
-
- 1. JDK基础
-
-
- 1.1 HashMap源码
- 1.2 线程池原理
- 1.3 [Java8新特性](https://developer.51cto.com/article/647804.html)
- 1.4 [锁机制](https://tech.meituan.com/2018/11/15/java-lock.html)(CAS/AQS/重量级 & 轻量级/偏向锁/独占锁/具体实现/ConcurrentHashMap)
- 1.5 [动态代理机制](https://javaguide.cn/java/basis/proxy/)
- 1.6 [NIO](https://javaguide.cn/java/basis/io/#aio-asynchronous-i-o)工作方式(IO模型 / Channel / Selector / Buffer / Epoll)
- 1.7 面向对象设计模式
- 1.8 [Fork/Join](https://www.twle.cn/c/yufei/javatm/javatm-basic-forkjoin.html)
-
- 2. JVM基础
- 3. 缓存相关
- 4. 消息相关
- 5. 数据库相关
- 6. 分布式技术
- 7. 应用框架相关
- 8.Web开发
-
-
- 8.1 WEB容器(Tomcat/[Netty](https://www.163.com/dy/article/FRNK1U3K0511X1MK.html))
- 8.2 [HTTP协议(1.1/2.0)](https://juejin.cn/post/6963931777962344455)
- 8.3 [WebSocket协议](http://www.noobyard.com/article/p-weguifxd-ru.html)
- 8.4 [TCP/UDP](https://javaguide.cn/cs-basics/network/other-network-questions/)
- 8.5 [Restful规范](https://javaguide.cn/system-design/basis/RESTfulAPI/#)
- 8.6 [登录认证(OAuth2/JWT)](https://javaguide.cn/system-design/security/basis-of-authority-certification/)
- 8.7 [权限设计](https://blog.51cto.com/u_13260163/3095454)
- 8.8 [RBAC模型](https://www.cnblogs.com/hoanfir/p/9088668.html)
-
- 9. 开发工具
- 10. 其他
-
1. JDK基础
1.1 HashMap源码
- JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的(“拉链法”解决冲突)。
- HashMap 通过key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这⾥的 n 指的是数组的⻓度),如果当前位置存在元素的话,就判断该元素与要存
⼊的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。 - 所谓扰动函数指的就是 HashMap 的 hash ⽅法。使⽤ hash ⽅法也就是扰动函数是为了防⽌⼀
些实现⽐较差的 hashCode() ⽅法 换句话说使⽤扰动函数之后可以减少碰撞。 - 所谓 拉链法 就是:将链表和数组相结合。也就是说创建⼀个链表数组,数组中每⼀格就是⼀
个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
- HashMap 通过key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这⾥的 n 指的是数组的⻓度),如果当前位置存在元素的话,就判断该元素与要存
- JDK1.8 以后在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。
- TreeMap、 TreeSet 以及 JDK1.8 之后的 HashMap 底层都⽤到了红⿊树。红⿊树就是为了解决⼆叉查找树的缺陷,因为⼆叉查找树在某些情况下会退化成⼀个线性结构。
- HashMap 的⻓度为什么是2的幂次⽅:为了能让 HashMap 存取⾼效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上⾯也讲到了过了, Hash 值的范围值-2147483648到2147483647,前后加起来⼤概40亿的映射空间,只要哈希函数映射得⽐较均匀松散,⼀般应⽤是很难出现碰撞的。但问题是⼀个40亿⻓度的数组,内存是放不下的。所以这个散列值是不能直接拿来⽤的。⽤之前还要先做对数组的⻓度取模运算,得到的余数才能⽤来要存放的位置也就是对应的数组下标。这个数组下标的计算⽅法是“ (n - 1) & hash ”。(n代表数组⻓度)。这也就解释了 HashMap 的⻓度为什么是2的幂次⽅。
1.2 线程池原理
- 池化技术的思想主要是为了减少每次获取资源的消耗,提⾼对资源的利⽤率。
- ThreadPoolExecutor 3 个最重要的参数:
- corePoolSize : 核⼼线程数线程数定义了最⼩可以同时运⾏的线程数量。
- maximumPoolSize : 当队列中存放的任务达到队列容量的时候,当前可以同时运⾏的线程数量变为最⼤线程数。
- workQueue : 当新任务来的时候会先判断当前运⾏的线程数量是否达到核⼼线程数,如果达到的话,新任务就会被存放在队列中。
- ThreadPoolExecutor 其他常⻅参数:
- keepAliveTime :当线程池中的线程数量⼤于 corePoolSize 的时候,如果这时没有新的任务提交,核⼼线程外的线程不会⽴即销毁,⽽是会等待,直到等待的时间超过了keepAliveTime 才会被回收销毁;
- unit : keepAliveTime 参数的时间单位。
- threadFactory :executor 创建新线程的时候会⽤到。
- handler :饱和策略。关于饱和策略下⾯单独介绍⼀下。
- 饱和策略:如果当前同时运⾏的线程数量达到最⼤线程数量并且队列也已经被放满了任务时, ThreadPoolTaskExecutor 定义⼀些策略:
- ThreadPoolExecutor.AbortPolicy :抛出 RejectedExecutionException 来拒绝新任务的处理。
- ThreadPoolExecutor.CallerRunsPolicy :调⽤执⾏⾃⼰的线程运⾏任务。您不会任务请求。但是这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应⽤程序可以承受此延迟并且你不能任务丢弃任何⼀个任务请求的话,你可以选择这个策略。
- ThreadPoolExecutor.DiscardPolicy : 不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy : 此策略将丢弃最早的未处理的任务请求。
-

- 解释:我们在代码中模拟了 10 个任务,我们配置的核⼼线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执⾏,剩下的 5 个任务会被放到等待队列中去。当前的 5 个任务之⾏完成后,才会之⾏剩下的 5 个任务。
1.3 Java8新特性
- Lambda 表达式 − Lambda 允许把函数作为一个方法的参数(函数作为参数传递到方法中)。
- 方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
- 新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
- Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
- Date Time API − 加强对日期与时间的处理。
- Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
- Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
1.4 锁机制(CAS/AQS/重量级 & 轻量级/偏向锁/独占锁/具体实现/ConcurrentHashMap)
- 锁的种类
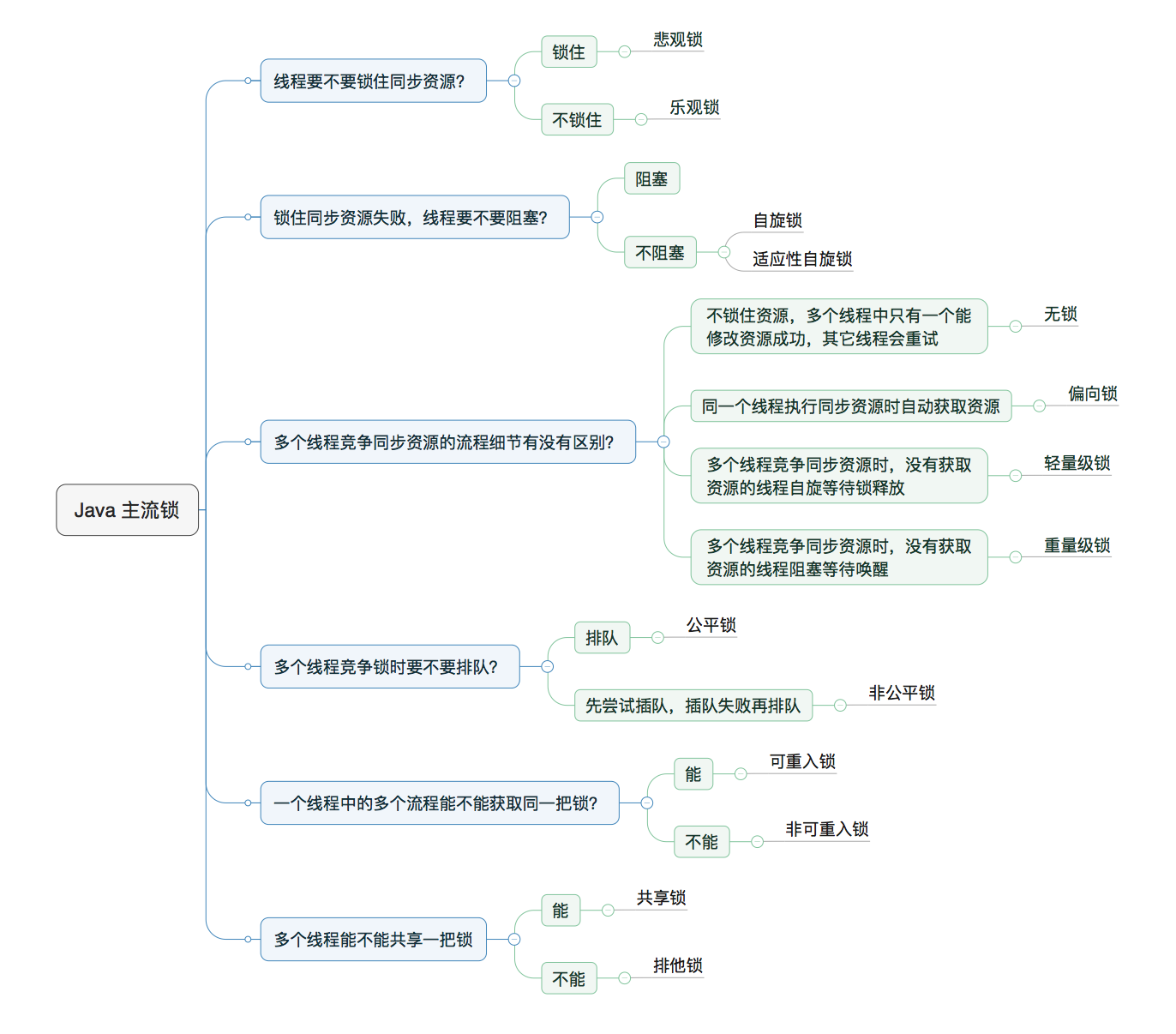
-
CAS:乐观锁的主要实现方式。
- CAS全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
-
AQS:抽象队列同步器AbstractQueuedSynchronizer。AQS 核⼼思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的⼯作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占⽤,那么就需要⼀套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是⽤ CLH 队列实现的,即将暂时获取不到锁的线程加⼊到队列中。
-
ConcurrentHashMap:是线程安全的HashMap。实现的思想是使用的分段加锁,使用分段加锁的作用当然就是可以有效提升并发量,可以对比一下所有操作都加锁的HashTable,就能明白分段加锁的好处了。
1.5 动态代理机制
1.6 NIO工作方式(IO模型 / Channel / Selector / Buffer / Epoll)
-
从应用程序的视角来看,应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
-
当应用程序发起 I/O 调用后,会经历两个步骤:
- 内核等待 I/O 设备准备好数据
- 内核将数据从内核空间拷贝到用户空间。
-
Java中常见的三种IO模型:
-
BIO(Blocking I/O):属于同步阻塞 IO 模型。在同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
-
NIO(Non-blocking/New I/O):属于 I/O 多路复用模型、同步非阻塞 IO 模型。
-
Java 中的 NIO 于 Java 1.4 中引入,对应
java.nio包,提供了Channel,Selector,Buffer等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。 -
-
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。但是,这种 IO 模型同样存在问题:**应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。**这个时候,I/O 多路复用模型 就上场了。
-
-
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间->用户空间)还是阻塞的。
目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,是目前几乎在所有的操作系统上都有支持
- select 调用 :内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
- epoll 调用 :linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
-
-
AIO(Asynchronous I/O):是异步 IO模型。AIO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
-
1.7 面向对象设计模式
- 面向对象思想的设计原则
- 单一职责原则
- 开闭原则
- 里氏替换原则
- 依赖注入原则
- 接口分离原则
- 迪米特原则
- 设计模式
- 设计模式按用途分类可分为
- 创建型模式:关注对象创建的过程;
- 结构型模式:关注类和对象如何组合在一起;
- 行为型模式:关注类与对象如何交互,如何分担职责。
- 设计模式按用途分类可分为
1.8 Fork/Join
-
Fork/Join是一种基于**“分治”**的算法:通过分解任务,并行执行,最后合并结果得到最终结果。
-
ForkJoinPool线程池可以把一个大任务分拆成小任务并行执行,任务类必须继承自RecursiveTask或RecursiveAction。 -
使用Fork/Join模式可以进行并行计算以提高效率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









