






哈希
1.先来了解一下Hash的基本思路:
设要存储对象的个数为num, 那么我们就用len个内存单元来存储它们(len>=num); 以每个对象ki的关键字为自变量,用一个函数h(ki)来映射出ki的内存地址,也就是ki的下标,将ki对象的元素内容全部存入这个地址中就行了。这个就是Hash的基本思路。
Hash为什么这么想呢?换言之,为什么要用一个函数来映射出它们的地址单元呢?
This is a good question.明白了这个问题,Hash不再是问题。下面我就通俗易懂地向你来解答一下这个问题。
现在我要存储4个元素 13 7 14 11
显然,我们可以用数组来存。也就是:a[1] = 13; a[2] = 7; a[3] = 14; a[4] = 11;
当然,我们也可以用Hash来存。下面给出一个简单的Hash存储:
先来确定那个函数。我们就用h(ki) = ki%5;(这个函数不用纠结,我们现在的目的是了解为什么要有这么一个函数)。
对于第一个元素 h(13) = 13%5 = 3; 也就是说13的下标为3;即Hash[3] = 13;
对于第二个元素 h(7) = 7 % 5 = 2; 也就是说7的下标为2; 即Hash[2] = 7;
同理,Hash[4] = 14; Hash[1] = 11;
好了,存现在是存好了。但是,这并没有体现出Hash的妙处,也没有回答刚才的问题。下面就来揭开它神秘的面纱吧。
现在我要你查找11这个元素是否存在。你会怎么做呢?当然,对于数组来说,那是相当的简单,一个for循环就可以了。
也就是说我们要找4次。
下面我们来用Hash找一下。
首先,我们将要找的元素11代入刚才的函数中来映射出它所在的地址单元。也就是h(11) = 11%5 = 1 了。下面我们来比较一下Hash[1]?=11, 这个问题就很简单了。也就是说我们就找了1次。这个就是Hash的妙处了。至此,刚才的问题也就得到了解答。至此,你也就彻底的明白了Hash了。
接下来讲hash冲突的解决:
http://blog.sina.com.cn/s/blog_6fd335bb0100v1ks.html
当关键字集合很大时,关键字值不同的元素可能会映象到哈希表的同一地址上,即 k1≠k2 ,但 H(k1)=H(k2),这种现象称为冲突,此时称k1和k2为同义词。实际中,冲突是不可避免的,只能通过改进哈希函数的性能来减少冲突。
综上所述,哈希法主要包括以下两方面的内容:
1)如何构造哈希函数
2)如何处理冲突。
2. 哈希函数的构造方法
构造哈希函数的原则是:①函数本身便于计算;②计算出来的地址分布均匀,即对任一关键字k,f(k) 对应不同地址的概率相等,目的是尽可能减少冲突。
下面介绍构造哈希函数常用的五种方法。
2.1. 数字分析法
如果事先知道关键字集合,并且每个关键字的位数比哈希表的地址码位数多时,可以从关键字中选出分布较均匀的若干位,构成哈希地址。例如,有80个记录,关键字为8位十进制整数d1d2d3…d7d8,如哈希表长取100,则哈希表的地址空间为:00~99。假设经过分析,各关键字中 d4和d7的取值分布较均匀,则哈希函数为:h(key)=h(d1d2d3…d7d8)=d4d7。例如,h(81346532)=43,h(81301367)=06。相反,假设经过分析,各关键字中 d1和d8的取值分布极不均匀, d1 都等于5,d8 都等于2,此时,如果哈希函数为:h(key)=h(d1d2d3…d7d8)=d1d8,则所有关键字的地址码都是52,显然不可取。
2.2. 平方取中法
当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
例:我们把英文字母在字母表中的位置序号作为该英文字母的内部编码。例如K的内部编码为11,E的内部编码为05,Y的内部编码为25,A的内部编码为01, B的内部编码为02。由此组成关键字“KEYA”的内部代码为11052501,同理我们可以得到关键字“KYAB”、“AKEY”、“BKEY”的内部编码。之后对关键字进行平方运算后,取出第7到第9位作为该关键字哈希地址,如图8.23所示。
| 关键字 | 内部编码 | 内部编码的平方值 | H(k)关键字的哈希地址 |
| KEYA | 11050201 | 122157778355001 | 778 |
| KYAB | 11250102 | 126564795010404 | 795 |
| AKEY | 01110525 | 001233265775625 | 265 |
| BKEY | 02110525 | 004454315775625 | 315 |
2.3. 分段叠加法
这种方法是按哈希表地址位数将关键字分成位数相等的几部分(最后一部分可以较短),然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。具体方法有折叠法与移位法。移位法是将分割后的每部分低位对齐相加,折叠法是从一端向另一端沿分割界来回折叠(奇数段为正序,偶数段为倒序),然后将各段相加。例如:key=12360324711202065,哈希表长度为1000,则应把关键字分成3位一段,在此舍去最低的两位65,分别进行移位叠加和折叠叠加,求得哈希地址为105和907,如图8.24所示。
1 2 3 1 2 3
6 0 3 3 0 6
2 4 7 2 4 7
1 1 2 2 1 1
+) 0 2 0 +) 0 2 0
———————— —————————
1 1 0 5 9 0 7
(a)移位叠加 (b) 折叠叠加
图8.24 由叠加法求哈希地址
2.4. 除留余数法
假设哈希表长为m,p为小于等于m的最大素数,则哈希函数为
h(k)=k % p ,其中%为模p取余运算。
例如,已知待散列元素为(18,75,60,43,54,90,46),表长m=10,p=7,则有
h(18)=18 % 7=4 h(75)=75 % 7=5 h(60)=60 % 7=4
h(43)=43 % 7=1 h(54)=54 % 7=5 h(90)=90 % 7=6
h(46)=46 % 7=4
此时冲突较多。为减少冲突,可取较大的m值和p值,如m=p=13,结果如下:
h(18)=18 % 13=5 h(75)=75 % 13=10 h(60)=60 % 13=8
h(43)=43 % 13=4 h(54)=54 % 13=2 h(90)=90 % 13=12
h(46)=46 % 13=7
此时没有冲突,如图8.25所示。
0 1 2 3 4 5 6 7 8 9 10 11 12
|
|
| 54 |
| 43 | 18 |
| 46 | 60 |
| 75 |
| 90 |
图8.25 除留余数法求哈希地址
2.5. 伪随机数法
采用一个伪随机函数做哈希函数,即h(key)=random(key)。
在实际应用中,应根据具体情况,灵活采用不同的方法,并用实际数据测试它的性能,以便做出正确判定。通常应考虑以下五个因素 :
l 计算哈希函数所需时间 (简单)。
l 关键字的长度。
l 哈希表大小。
l 关键字分布情况。
l 记录查找频率
3. 处理冲突的方法
通过构造性能良好的哈希函数,可以减少冲突,但一般不可能完全避免冲突,因此解决冲突是哈希法的另一个关键问题。创建哈希表和查找哈希表都会遇到冲突,两种情况下解决冲突的方法应该一致。下面以创建哈希表为例,说明解决冲突的方法。常用的解决冲突方法有以下四种:
3.1. 开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:
l 线性探测再散列
dii=1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
l 二次探测再散列
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
l 伪随机探测再散列
di=伪随机数序列。
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
例如,已知哈希表长度m=11,哈希函数为:H(key)= key % 11,则H(47)=3,H(26)=4,H(60)=5,假设下一个关键字为69,则H(69)=3,与47冲突。如果用线性探测再散列处理冲突,下一个哈希地址为H1=(3 + 1)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 + 2)% 11 = 5,还是冲突,继续找下一个哈希地址为H3=(3 + 3)% 11 = 6,此时不再冲突,将69填入5号单元,参图8.26 (a)。如果用二次探测再散列处理冲突,下一个哈希地址为H1=(3 + 12)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 - 12)% 11 = 2,此时不再冲突,将69填入2号单元,参图8.26 (b)。如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,……..,则下一个哈希地址为H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为H2=(3 + 5)% 11 = 8,此时不再冲突,将69填入8号单元,参图8.26 (c)。
0 1 2 3 4 5 6 7 8 9 10
|
|
|
| 47 | 26 | 60 | 69 |
|
|
|
|
(a) 用线性探测再散列处理冲突
0 1 2 3 4 5 6 7 8 9 10
|
|
| 69 | 47 | 26 | 60 |
|
|
|
|
|
(b) 用二次探测再散列处理冲突
0 1 2 3 4 5 6 7 8 9 10
|
|
|
| 47 | 26 | 60 |
|
| 69 |
|
|
(c) 用伪随机探测再散列处理冲突
图8.26开放地址法处理冲突
从上述例子可以看出,线性探测再散列容易产生“二次聚集”,即在处理同义词的冲突时又导致非同义词的冲突。例如,当表中i, i+1 ,i+2三个单元已满时,下一个哈希地址为i, 或i+1 ,或i+2,或i+3的元素,都将填入i+3这同一个单元,而这四个元素并非同义词。线性探测再散列的优点是:只要哈希表不满,就一定能找到一个不冲突的哈希地址,而二次探测再散列和伪随机探测再散列则不一定。
3.2. 再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
4.hash 操作
a.增加
my %hash; //定义
第一种写法:$hash{'author'}="Young"; #author 是关键字,Young 是value 与数组一样,hash作为整体时候是这样%hash 带标示符%,作为单个元素使用要使用$而不是%
第二种写法: my %food=('fruit',"apple",'drink',"Coco"); #类似数组初始化 注意这里使用的是( )不是{} {},用了它实际就是创建了一个引用,正确的就是(),圆括号否则会报 Reference found where even-sized list expected at hash.pl line 4.
第三种写法:my %fruit=(apple=>"fruit",banana=>'fruit'); # =>是perl运算符,用于hash
b.使用hash值
单个使用:$hash{'author'}; # $哈希名{$keyword}
全部使用:foreach $key (keys %food)
{
print print "$key=>$food{$key}\n"; #使用keys %food 遍历%food的每一个关键字
}
获取所有的key:my @key=keys %fruit;
获取所有的value: my @value=values %fruit;
3.hash 函数 exists 和delete
判断 某个关键字是否存在 exists $hash{'auther'}
删除某个关键字 delete %hash{$keyword}
删除整个hash %hash=();
实例
#!/usr/bin/perl -w
my %hash;
$hash{'author'}="Young";
my %food=('fruit',"apple",'drink',"Coco");
my %fruit=(apple=>"fruit",banana=>'fruit');
print "$hash{'author'}\n";
foreach $key (keys %food)
{
print "$key=>$food{$key}\n";
}
my @key=keys %fruit;
my @value=values %fruit;
print @key;
print @value;
print "\n";
print "auther is exists\n" if(exists $hash{'auther'});
delete $food{'drink'};
print "after delete some keyword print \%food\n";
while((my $key,my $value)=each%food)
{
print "$key=>$value\n";
}
|
结果:
/home/Young> perl hash.pl
Young
fruit=>apple
drink=>Coco
bananaapplefruitfruit
after delete some keyword print %food
fruit=>apple
哈希学习
一、背景介绍
1、首先介绍一下最近邻搜索:最近邻搜索问题,也叫相似性搜索,近似搜索,是从给定数据库中找到里查询点最近的点集的问题。

给定一个点集,以及一个查询点q,需要找到离q最近的点的集合;在大规模高维度空间的情况下,这个问题就变得非常难,而且大多数算法计算量极大,复杂度很高; 而且一般用近似的最邻近搜索代替;哈希就是解决上述这类问题的主要方法;
二、哈希学习的目的及分类
哈希学习的目的:通过机器学习机制将数据映射成简洁的二进制串的形式, 同时使得哈希码尽可能地保持原空间中的近邻关系, 即保相似性.(这一点很重要,如果失去了原来的相似性,那么哈希学习也就变得没有意义了)
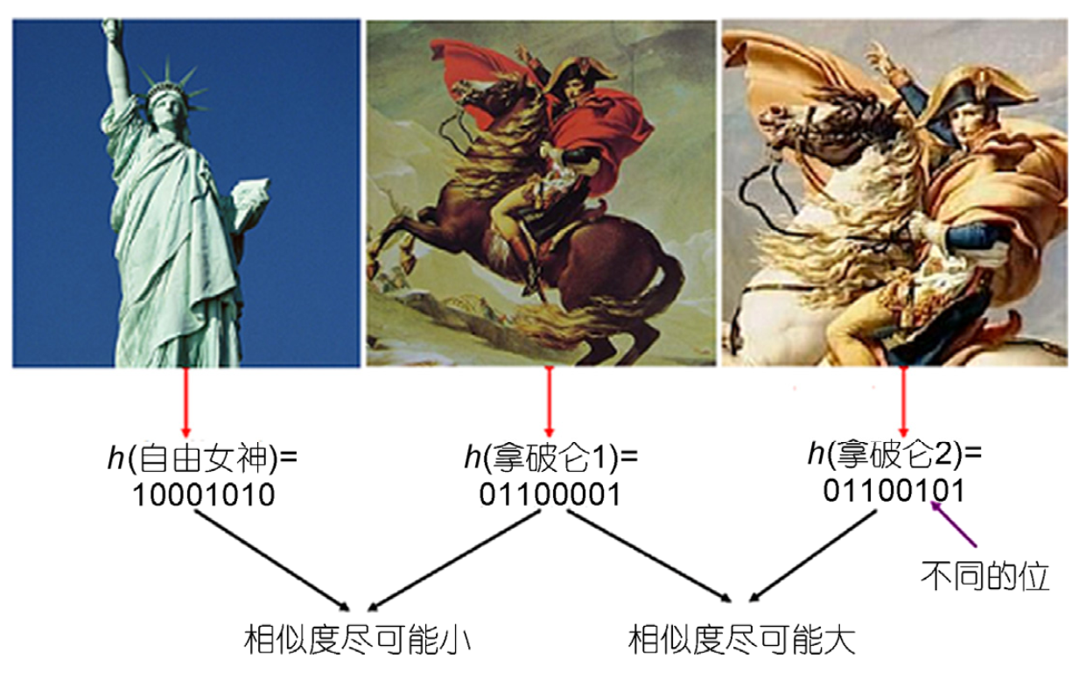
以下面这幅图为例,原始数据是三幅图像,其中后面这两幅相似度比较高,也就是说在原始空间中从语义层次的距离或者欧氏距离都比较近,映射为哈希码之后,距离也应该更近。
分类:关于哈希的方法主要分为两大类:1、第一种的代表是局部敏感哈希,这种方法主要是人工设计或者随机生成哈希函数,是一种数据独立的方法;
2、第二种是哈希学习的方法,希望从数据中自动学习出哈希函数,是一种数据依赖的方法;也是现在主流的方法;
显然第二种具有数据依赖性,是一种更有适应性的方法。
三、哈希学习的一般步骤
第一步,:先对原空间的样本进行降维, 得到1个低维空间的实数向量表示;
第二步:对得到的实数向量进行量化(即离散化)得到二进制哈希码;
对于第一步如何降维,我们这里不再做介绍,下面主要介绍一下量化的方法。
四、量化方法
目的:对于一个低维向量把它映射为一个二进制哈希码,并且尽可能的保持原来的相似性。
1、SBQ
介绍:对于给出向量的每一个维度的数值,我们设定一个阈值。然后根据这个维度数值的情况与阈值作比较,确定其映射的二进制数是2还是1。之后我们把每个维度映射出的二进制数串起来组成哈希码。
举例:
比如某一向量为[4,3,7,8],我们设定阈值为5,并且>=5为1,反之为0.
那么该向量对应的二进制哈希码为0011.
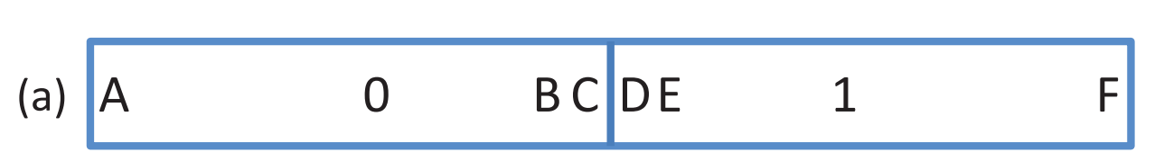
相似性的衡量方法:对于映射好的哈希码如何衡量他们之间的相似度呢?我们采用汉明距离来衡量(二进制对应位不同的个数,比如0011与0000的汉明距离是2)
2、HQ
跟SBQ比较类似,是将每一个维度划分为四个区域,使用三个阈值和两位二进制码来编码;

相似性的衡量方法:也是采用汉明距离来衡量。















 2012
2012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









