






概述
LL算法属于预测性算法。一种用于解析上下文无关文法的算法
第一个 L,是 Left-to-right,代表从左向右处理程序代码。第二个 L,是 Leftmost,意思是最左推导
LL(1)算法的作用是为了, 如何通过只向前看1个词法单元来唯一确定与当前句子匹配的产生式
它对于文法的要求是在1个向前看符号下无推导二义性
- 换句话说,指LL(1)算法在向前看一个符号的情况下,不会产生推导的二义性
- 这意味着在解析语法的过程中,LL(1)算法能够准确地预测应该采用哪个产生式,并且不会出现歧义或不确定的情况
采用 Leftmost 的方法,在推导过程中,句子的左边逐步都会被替换成终结符,只有右边的才可能包含非终结符
- 某产生式的最左侧是非终结符,就需要计算它的First集合
- 或者存在ε,继续往下解析,万一出现了语法错误,就需要进行回溯。如果这个时候引进Follow集合,就不需要往下判断,及时判断是否是语法错误
如果某一个推出空串的非终结符F的First集合中存在某终结符a,且a同时存在于Follow集合中,那么无法确定a到底来源于F本身还是F后继的内容,这就产生了向前看1符号的二义性
First集合
概述
First集合是在文法中用于描述一个非终结符号能够推导出的终结符号的集合
- 它表示的是在文法规则中,一个非终结符号在推导过程中可能出现的第一个终结符号
同时某些非终结符号有复数个左部相同的产生式子,所以需要进行提取左公因子,消除重复的产生式
并且使用左递归消除,消除无限递归问题
First简单例子
举个例子来说明,假设我们有以下简单文法:
A -> BCc | gDB
B -> bCDE | ε
C -> DaB | ca
D -> dD | ε
E -> gAf | c
FIRST集的求解:
- FIRST(A) = FIRST(BCc) ∪ FIRST(gDB) = {a, b, c, d, g}
- FIRST(B) = {b, ε}
- FIRST© = {a, c, d}
- FIRST(D) = {d, ε}
- FIRST(E) = {g, c}
左递归消除算法
提取左公因子
概述
数学中公因子含义相同,就是公共因子,而左公因子就是最左边的因子
例子说明
例子1
S -> aB1|aB2|aB3|aB4|...|aBn|y
可以看出前n项拥有一个公共的左公因子: a,所以可以把它提取出来
提取规则
S -> aS'|y
S' -> B1|B2|B3|...|Bn
例子2
statement : variableDeclare | functionDeclare | other;
variableDeclare : type Identifier ('=' expression)? ;
funcationDeclare : type Identifier '(' parameterList ')' block ;
可以看出 variableDeclare 和 funcationDeclare 拥有项目的 ‘type Identifier’
提取规则
statement: declarator | other;
declarator: declarePrefx (variableDeclarePostfix | functionDeclarePostfix);
variableDeclarePostfix: ('=' expression)?;
functionDeclarePostfix: '(' parameterList ')' block
Follow 集合
概述
Follow集合是指在一个上下文无关文法中,非终结符号A的Follow集合是所有可以紧跟在A后面的终结符的集合
- 简而言之,该非终结符号符号后面跟着的第一个终结符
Follow例子
A -> BCc | gDB
B -> bCDE | ε
C -> DaB | ca
D -> dD | ε
E -> gAf | c
Follow集合
- FOLLOW© = {c, d, g, #}
- 因为要找C后面的跟着的第一个终结符,所有应该直接看谁能产生C
- C的生成式: B -> bCDE | ε 、 A -> BCc | gDB
- FOLLOW(B) = {a, c, d, f, g, #}
- FOLLOW(D) = {a, b, c, g, f, #}
- FOLLOW(E) = {a, c, d, f, g, #}
LL(1) 算法案例
消除了左递归的语法
expression : assign ;
assign : equal | assign1 ;
assign1 : '=' equal assign1 | ε;
equal : rel equal1 ;
equal1 : ('==' | '!=') rel equal1 | ε ;
rel : add rel1 ;
rel1 : ('>=' | '>' | '<=' | '<') add rel1 | ε ;
add : mul add1 ;
add1 : ('+' | '-') mul add1 | ε ;
mul : pri mul1 ;
mul1 : ('*' | '/') pri mul1 | ε ;
pri : ID | INT_LITERAL | LPAREN expression RPAREN ;
First集合
计算First集合
/**
* @brief First, 顾名思义就是关于该符号的所有产生式右部第一个遇到的终结符
* 1. 计算First集合
* 2. 采用了不动点法
*
* 不动点法介绍
* 1. 多次遍历图中的节点,看看每次有没有计算出新的集合成员
* 2. 比如,第一遍计算的时候,当求First(pri)的时候,它所依赖的First(expression)中的成员可能不全
* 3. 等下一轮继续计算时,发现有新的集合成员,再加进来就好了,直到所有集合的成员都没有变动为止
*
* @param grammar 消除了左递归的语法树
* @return map<GrammarNode*, set<string>*> 返回First集合
*/
map<GrammarNode*, set<string>*> FirstFollowSet::caclFirstSets(GrammarNode* grammar)
{
map<GrammarNode*, set<string>*> firstSets;
firstSets.clear();
set<GrammarNode*> calculated;
calculated.clear();
bool stable = caclFirstSets(grammar, firstSets, calculated);
int i = 1;
std::cout << "fcaclFirstSets round: " << i++ << std::endl;
set<GrammarNode*> calculated1;
while (!stable) {
std::cout << "caclFirstSets round: " << i++ << std::endl;
stable = caclFirstSets(grammar, firstSets, calculated1);
}
return firstSets;
}
得到对应First集合
expression: ID INT_LITERAL LPAREN
assign: ID INT_LITERAL LPAREN
equal: ID INT_LITERAL LPAREN
assign1: ASSIGN EPSILON
_assign1_01: ASSIGN
rel: ID INT_LITERAL LPAREN
equal1: EPSILON EQUAL NOTEQUAL
_equal1_01: EQUAL NOTEQUAL
_equal1_01_11: EQUAL NOTEQUAL
add: ID INT_LITERAL LPAREN
rel1: EPSILON GE GT LE LT
_rel1_01: GE GT LE LT
_rel1_01_11: GE GT LE LT
mul: ID INT_LITERAL LPAREN
add1: ADD EPSILON SUB
_add1_01: ADD SUB
_add1_01_11: ADD SUB
pri: ID INT_LITERAL LPAREN
mul1: DIV EPSILON MUL
_mul1_01: DIV MUL
_mul1_01_11: DIV MUL
_pri_03: LPAREN
blockStatements: EPSILON ID IF INT INT_LITERAL LBRACE LPAREN
_blockStatements_02: ID IF INT INT_LITERAL LBRACE LPAREN
blockStatement: ID IF INT INT_LITERAL LBRACE LPAREN
variableDeclarator: INT
_variableDeclarator_13: ASSIGN EPSILON
_variableDeclarator_13_01: ASSIGN
statement: ID IF INT_LITERAL LBRACE LPAREN
expressionStatement: ID INT_LITERAL LPAREN
ifStatement: IF
block: LBRACE
Follow集合
计算Follow集合
/**
* @brief Follow,顾名思义,就是该符号后面跟着的第一个终结符
* 1. 求 follow 集合,都是从开始符号S开始推导
*
* 计算Follow集合
* 1. 对所有节点计算
*
* @param grammar 消除了左递归的语法树
* @param firstSets first集合
* @return map<GrammarNode*, set<string>*>
*/
map<GrammarNode*, set<string>*> FirstFollowSet::caclFollowSets(GrammarNode *grammar, map<GrammarNode*, set<string>*> firstSets)
{
map<GrammarNode*, set<string>*> followSets;
map<GrammarNode*, set<GrammarNode*>*> rightChildrenSets;
// 不动点法计算Follow集合
int i = 1;
std::cout << "follow set round: " << i++ << endl;
set<GrammarNode*> calculated;
bool stable = caclFollowSets(grammar, followSets, rightChildrenSets, firstSets, calculated);
set<GrammarNode*> calculated1;
while (!stable) {
std::cout << "follow set round:" << i++ << std::endl;
stable = caclFollowSets(grammar, followSets, rightChildrenSets, firstSets, calculated1);
}
// 为根节点最右边的边,也就是所有可能出现在程序末尾的非终结符,加上$,也就是整个Token串结束符号
set<string> *tempFollowSet = new set<string>();
tempFollowSet->insert("$");
set<GrammarNode*> add1;
addToRightChild(grammar, tempFollowSet, followSets, rightChildrenSets, add1);
// 给根节点加上$。根节点如果没有递归引用,不会出现在followSets中
set<string> *rootFollowSet = followSets[grammar];
if (rootFollowSet == nullptr) {
rootFollowSet = new set<string>();
followSets[grammar] = rootFollowSet;
}
rootFollowSet->insert("$");
return followSets;
}
得到对应的Follow集合
expression: RPAREN SEMI
assign: RPAREN SEMI
equal: ASSIGN EPSILON RPAREN SEMI
assign1: RPAREN SEMI
_assign1_01: RPAREN SEMI
rel: ASSIGN EPSILON EQUAL NOTEQUAL RPAREN SEMI
equal1: ASSIGN EPSILON RPAREN SEMI
_equal1_01: ASSIGN EPSILON RPAREN SEMI
_equal1_01_11: ID INT_LITERAL LPAREN
add: ASSIGN EPSILON EQUAL GE GT LE LT NOTEQUAL RPAREN SEMI
rel1: ASSIGN EPSILON EQUAL NOTEQUAL RPAREN SEMI
_rel1_01: ASSIGN EPSILON EQUAL NOTEQUAL RPAREN SEMI
_rel1_01_11: ID INT_LITERAL LPAREN
mul: ADD ASSIGN EPSILON EQUAL GE GT LE LT NOTEQUAL RPAREN SEMI SUB
add1: ASSIGN EPSILON EQUAL GE GT LE LT NOTEQUAL RPAREN SEMI
_add1_01: ASSIGN EPSILON EQUAL GE GT LE LT NOTEQUAL RPAREN SEMI
_add1_01_11: ID INT_LITERAL LPAREN
pri: ADD ASSIGN DIV EPSILON EQUAL GE GT LE LT MUL NOTEQUAL RPAREN SEMI SUB
mul1: ADD ASSIGN EPSILON EQUAL GE GT LE LT NOTEQUAL RPAREN SEMI SUB
_mul1_01: ADD ASSIGN EPSILON EQUAL GE GT LE LT NOTEQUAL RPAREN SEMI SUB
_mul1_01_11: ID INT_LITERAL LPAREN
_pri_03: ADD ASSIGN DIV EPSILON EQUAL GE GT LE LT MUL NOTEQUAL RPAREN SEMI SUB
blockStatements: $ RBRACE
_blockStatements_02: $ RBRACE
blockStatement: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE
variableDeclarator: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE
_variableDeclarator_13: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE
_variableDeclarator_13_01: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE
statement: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE SEMI
expressionStatement: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE SEMI
ifStatement: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE SEMI
block: $ EPSILON ID IF INT INT_LITERAL LBRACE LPAREN RBRACE SEMI
向前看1的二义性的问题
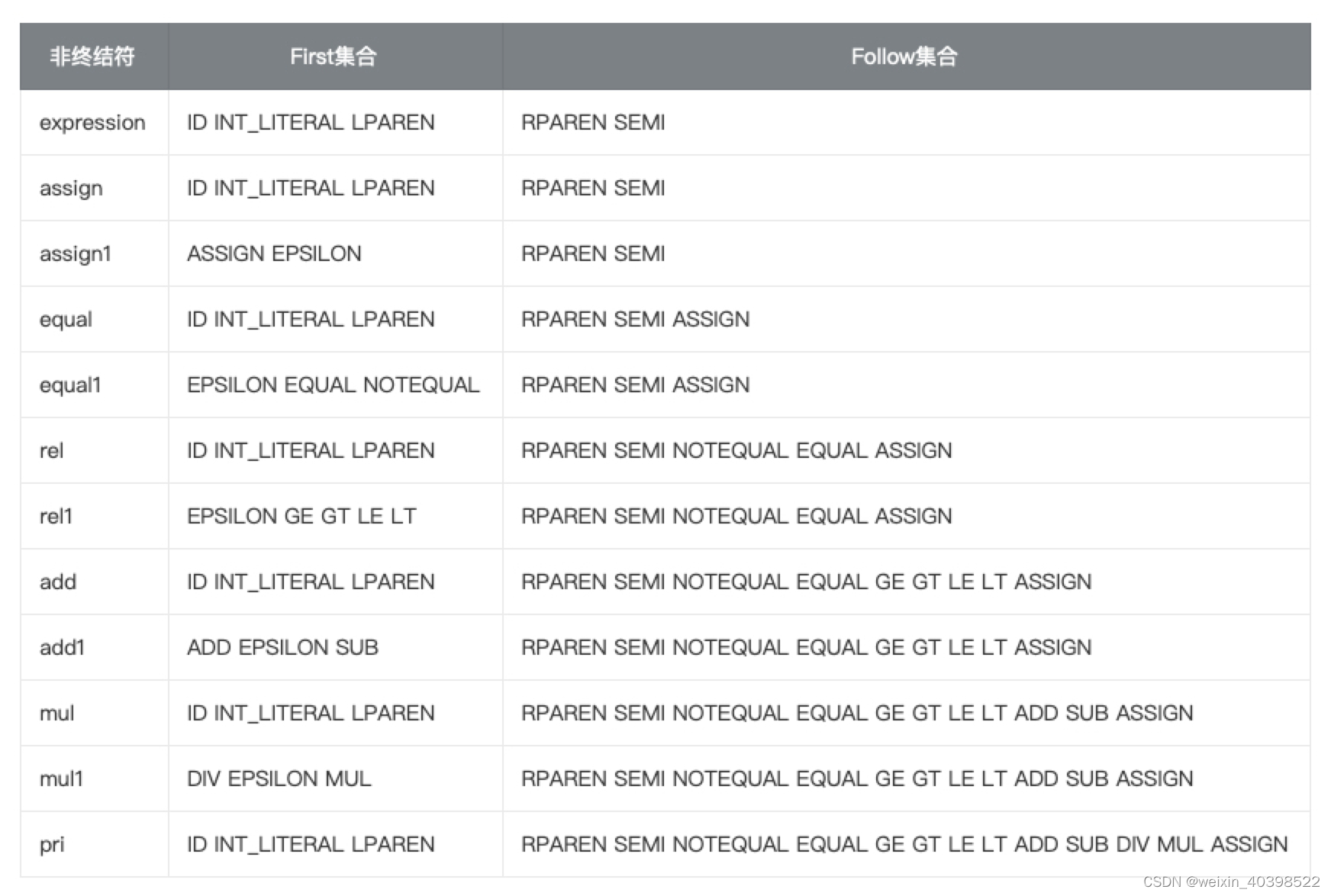
处理了左递归的语法, First 集合与 FOLLOW集合不存在相交问题。这样就避免了向前看1的二义性的问题
LL(1) 算法匹配
对 2+3*(4+5) 进行解析
string script1 = "2+3*(4+5)";
GrammarNode* grammar = SampleGrammar::statementGrammar();
LLParser::parse(script1, grammar);
/**
* @brief LL(1)算法匹配
* 1. 对于And类型的,要每个子节点依次全部匹配
* 1. 遍历And类型的的子节点,并进行递归下降分析
* 2. 对于Or类型的,通过预测,知道采用那个产生式
* 1. 预先预测一个token as t,并遍历该Or类型的子节点
* 2. 如果子节点是一个token,并于t做类型判断。如果相同就匹配成功
* 3. 如果该子节点下还有子节点,那么first集合中找出该子节点对应first集合,并于t进行类型判断,如果相同就匹配成功
* 4. 如果该子节点2,3步骤都匹配成功,那么该子节点的子节点进行递归下降分析
* 5. 如果最终没有匹配成功,那么就是产生了ε,就该查找该Or类型的follow集合
* 3. 如果是ε类型就是给节点设置成ε类型
* 4. 如果是字符串类型,预读一个Token。看看自身的类型跟语法要求的是否一致。并设置到当前节点中
* 5. 如果全部子节点返回的都是Epsilon, 自身也置为Epsilon
*
* @param grammar 消除了左递归的语法树
* @param tokenReader token串
* @param firstSets first集合
* @param followSets follow集合
* @return ASTNode*
*/
ASTNode* LLParser::match(GrammarNode* grammar, TokenReader *tokenReader,
map<GrammarNode*, set<string>*> firstSets,
map<GrammarNode*, set<string>*> followSets)
{
.....
}
最终结果
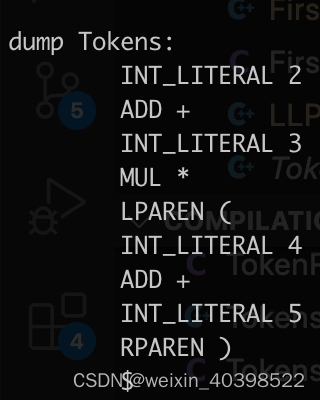
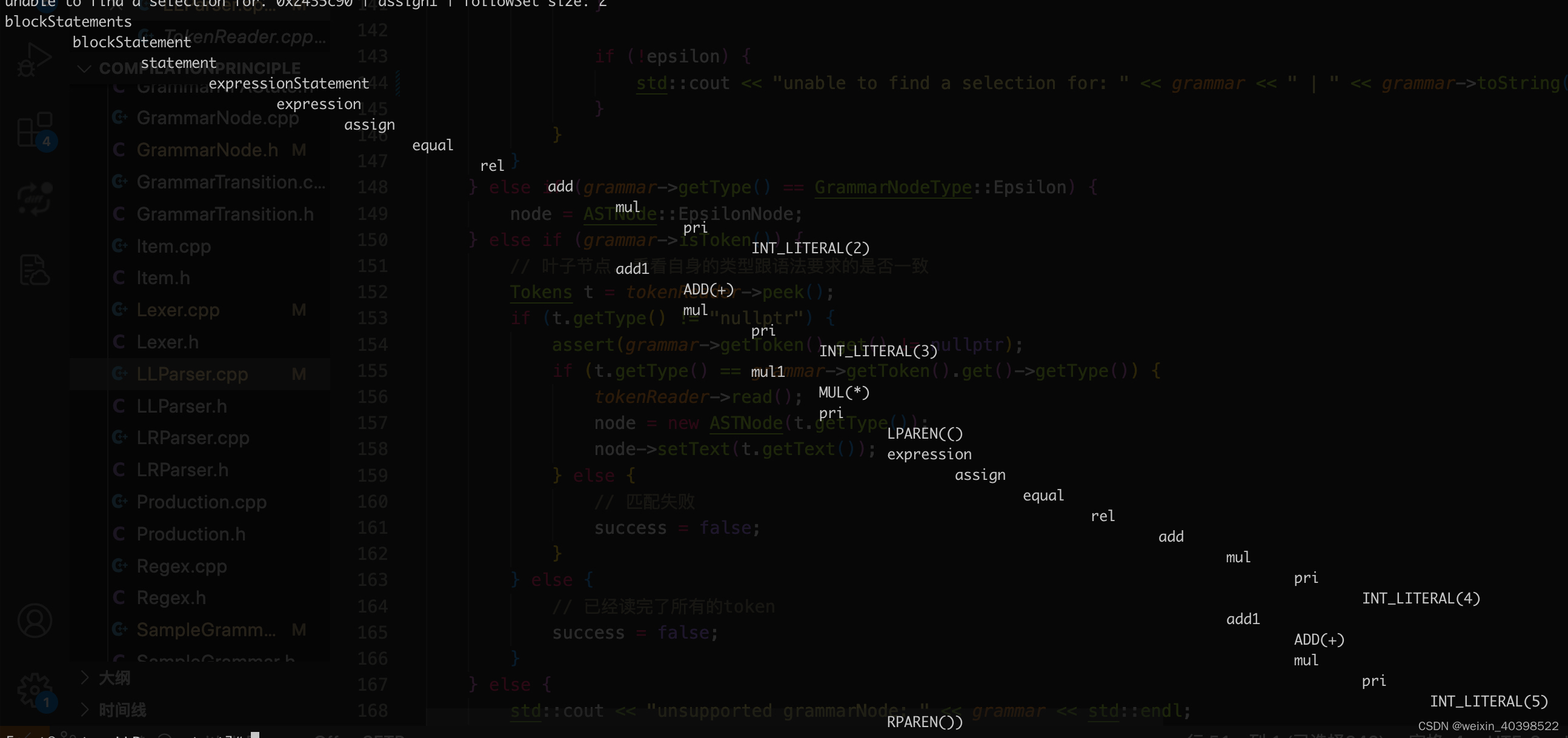
与语法树和token,生成对应的AST树















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









