






异构计算程序工作流程
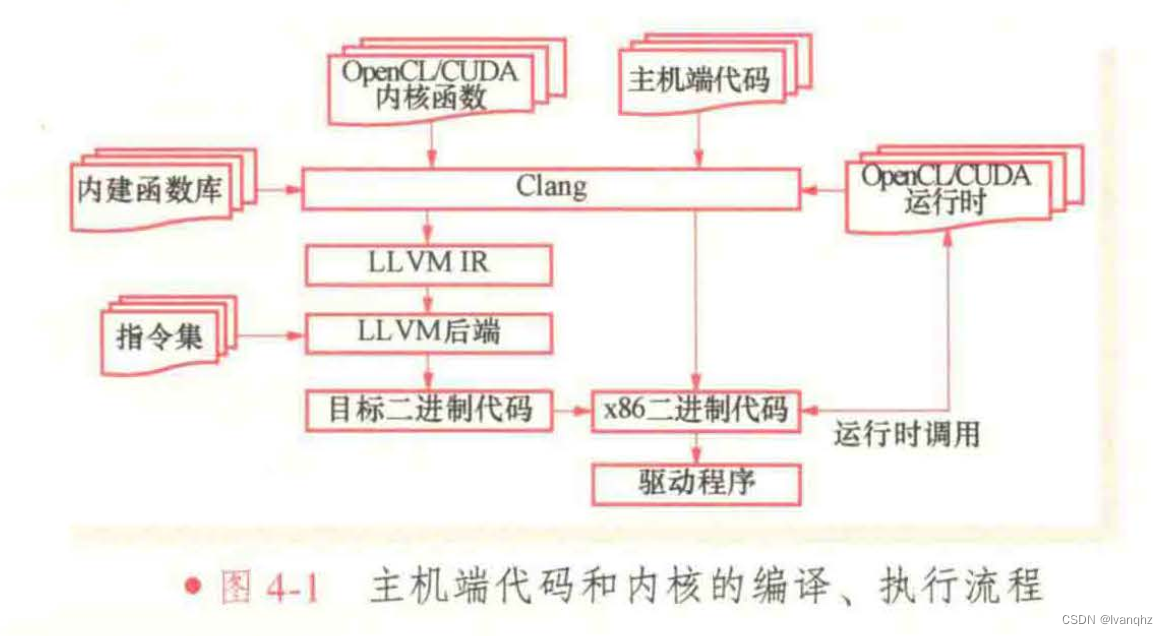
图4-1中的LLVM后端的主要功能是代码生成,其中包括若干指令生成分析转换pass,将LLVM IR 转换为特定目标架构的机器代码
LLVM 流水线结构
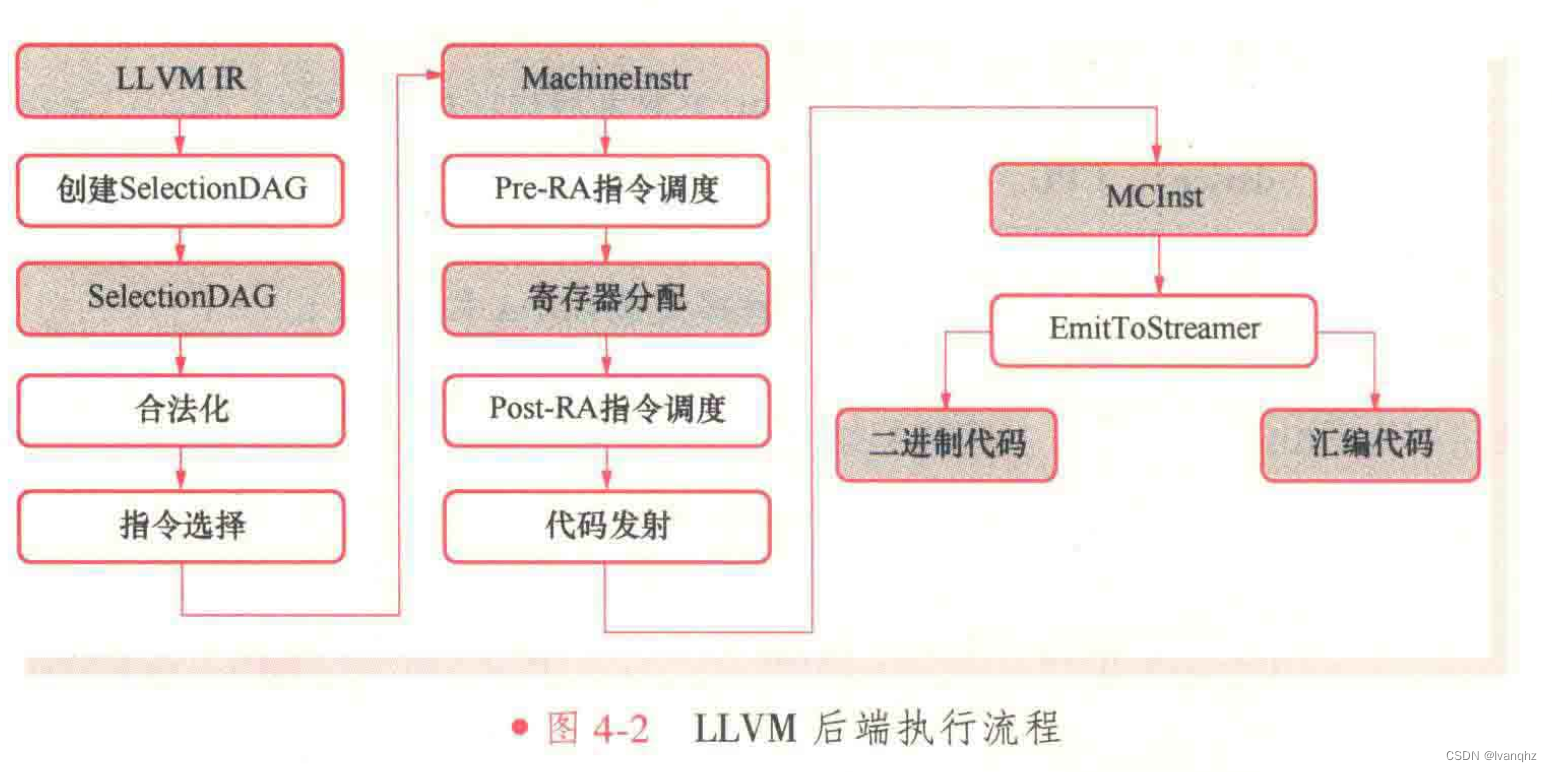
输入指令经过图4-2中的各个阶段,从最初的LLVM IR,逐步演化为SelectionDAG、MachineDAG、MachineInstr,最后由MCInst 输出可执行的二进制代码或汇编代码
这其中经过的各个阶段是不同的分析转换pass,主要包括指令选择(Instrunction Selection)、指令调度(Instrunction Scheduling), 寄存器分配(Register Allocation)、以及代码发射(Code Emission)
不同目标后端应根据实际需要,对不同pass做定制化。指令选择、指令调度和寄存器分配是后端流程中最重要的3个组成部分
LLVM 后端执行流程
SelectionDAG 的创建
首先,SelectionDAGBuilder 模块遍历LLVM IR中每一函数,以及函数中的每一个基本块,并将其中的指令转换成SDNode对象,整个基本块相应地转换为Selection DAG 对象。SelectDAG 对象的创建过程采用窥孔优化算法,DAG中每个节点的内容仍是LLVM IR指令
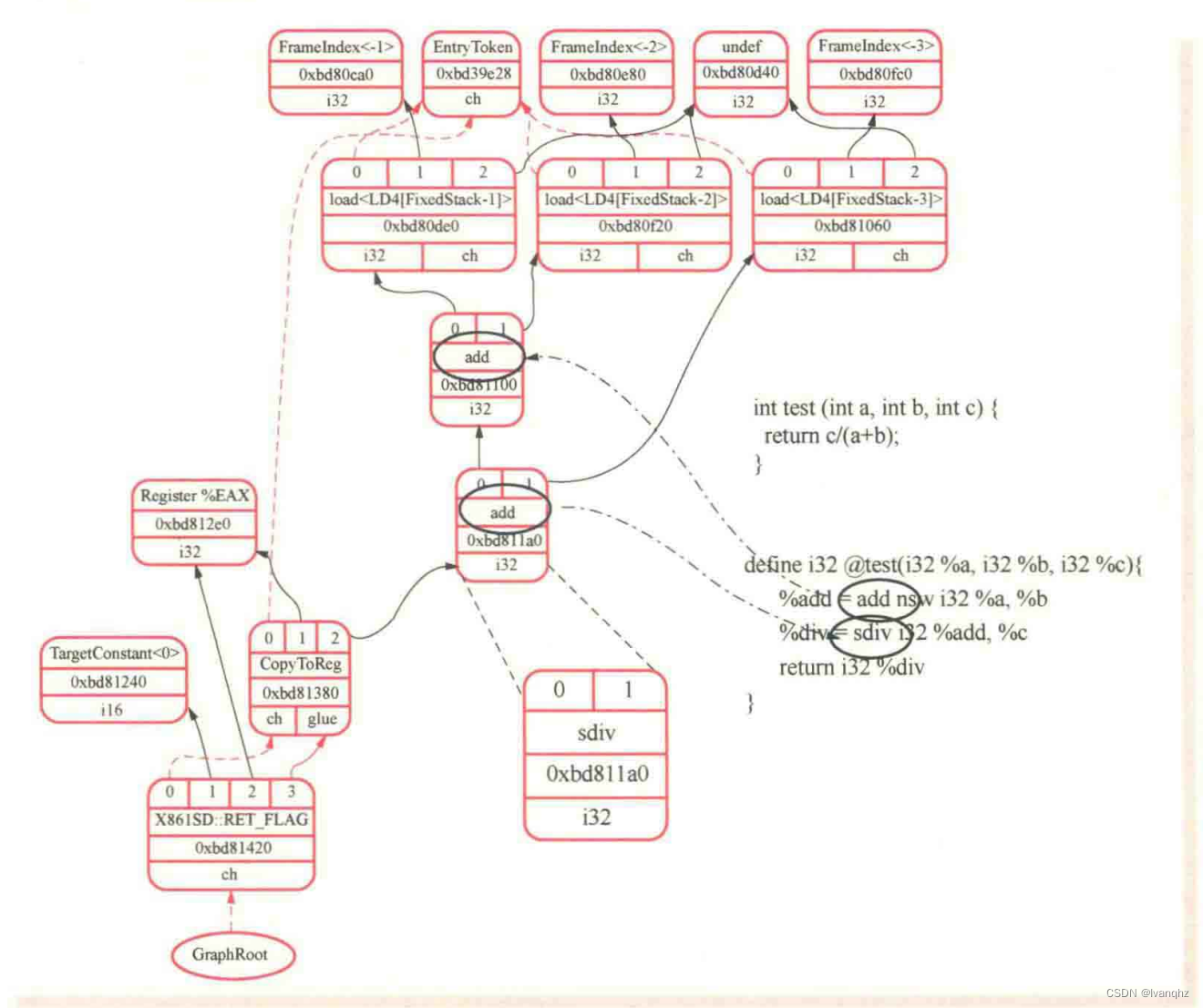
图4-3以一个C/C++语言实现的函数为例,显示了LLVM IR 与 SelectionDAG的对应关系
图4-3的LLVM IR 中只有一个基本块。当SelectionDAGBuilder模块检测到IR指令时,调用相应的visit()函数
例如,如果IR指令为sdiv操作,则调用visitSDIV() 函数,将两个操作数保存为SD-Vaule对象,并从DAG中获取SDNode节点,以ISD::SDIV作为操作符
- 在图4-3所示的sdiv节点中,操作数0为%add,操作数1为%c
用类似的方法处理完所有IR指令后,IR被转换为如图4-3所示的SelectionDAG。每个DAG表示一个基本块中的计算,不同的基本块与不同的DAG关联
DAG中的节点表示计算,节点之间的边可以有不同的含义。DAG中的每个SDNode节点会维护一个记录,其中保存了本节点对其他节点的各种依赖关系
这些依赖关系可能是数据依赖(本节点使用了其他节点定义的值),也可能是控制流依赖(本节点的指令必须在其他节点的指令执行后才能执行)
这种依赖关系通过SDValue对象表示,SDValue对象中封装了指向关联节点的指针和被影响结果的的序列号。也可以说,DAG中的操作顺序通过DAG边的使用-定值关系确定
例如,图4-3中的sdiv节点中有一条输出边连接到add节点,这意味着add节点定义了一个会被sdive中使用的值
因此,add操作必须在sdiv节点之前执行。SelectionDAG中的节点依赖关系可总结为如下三类
- 黑色箭头表述数据流依赖。数据流依赖表示当前节点依赖前一节点的结果。DAG中大部分节点依赖关系是数据流依赖
- 虚线彩色箭头表示非数据流链依赖。链依赖可以防止副作用节点,确定两个不相关指令的顺序。例如,如果加载和保存指令访问的是相同的内存位置,就必须确保它们的执行顺序与其在原程序中的顺序一致。图中的CopyToReg节点操作必须在RET_FLAG节点之前发生,因为它们之间是链依赖
- 彩色箭头表示粘合(glue)依赖。粘合依赖是用来防止两个指令调度后被分开,即它们中间不能插入其他指令
将IR转换为DAG很重要,因为可以让代码生成器使用基于树的模式匹配指令选择算法。此时的SelectionDAG与目标设备无关,但对于具体目标设备而言,DAG中有些指令可能不合法。因为不同目标设备支持的指令集不同,指令集中的指令IR指令可能没有对应关系
- 例如,x86不支持sdiv而是支持sdivrem
合法化
由SelectionDAGBuilder 模块输出的SelectionDAG 不是机器指令,不能做指令选择。在生成机器指令之前,DAG节点还要经过几个转换阶段,其中合法化(legalization)是最重要的阶段
执行合法化的原因是SelectionDAGBuilder 模块构造SDNode节点中的指令操作数类型和操作不一定能被目标平台支持。因此,SDNode节点的合法化及操作数类型的合法化和操作的合法化
目标平台一般不可能为IR中的所有操作提供指令支持。因此,操作合法化的目的是将这些平台不支持的操作三种方式转换成平台支持的操作
-
- 扩展(Expansion): 即用一组操作来模拟一个操作
-
- 提升(Promotion): 即将数据转换成更大的类型来支持操作
-
- 定制(Custom): 即通过目标平台相关的钩子程序(hook) 实现合法化
例如,LLVM IR 的sdiv只计算商,而x86除法指令计算得到商和余数,并分别保存在两个寄存器中。因为指令选择可区分sdivrem和sdiv,因此,当目标平台不支持sdiv时,需要在合法化阶段将sdiv扩展到sdivrem指令
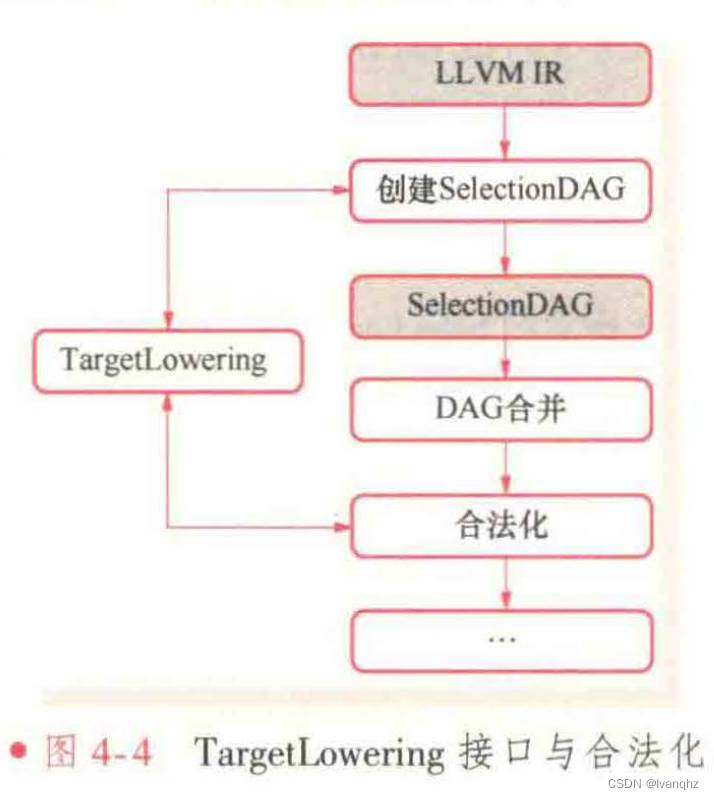
目标平台相关信息可通过TargetLowering接口传递给SelectionDAG,如图4-4所示
LLVM后端会实现该接口,并描述如何将LLVM IR指令用合法的SelectionDAG操作实现。例如,x86的TargetLowering构造合法函数通过Expand标志来标识需要扩展的节点
当SelectionDAGLegalize::LegalizeOp()方法检测到sdiv节点的Expand标志时,便可用sdivrem替换sdiv节点
与此类似,与目标平台相关的合并方法可识别节点组合模式,并决定是否合并某些节点组合以提高指令选择质量
类型合法化的目的是保证后续的指令选择处理的数据类型都合法。合法数据是目标平台原生支持的数据类型,目标平台的td文件中会为每一种数据类型定义关联的寄存器类如:
def FPRegs : RegisterClass<"SP", [f32], 32, (sequence "F%u", 0, 31)>
def DFPRegs : RegisterClass<"SP", [f64], 64, (add D0, D1, D2, D3, D4, D5, D6, D7, D8, D9)>
FPRegs 寄存器类定义了一组32个从F0~F31单精度浮点类型的寄存器,DFPRegs 寄存器类定义了一组16个从D0~D15双精度浮点类型的寄存器
如果平台的td文件的寄存器类没有定义相应的数据类型,则对平台来说,该数据类型就是非法数据类型。非法数据类型必须被删除,或者视非法数据类型不同,做相应处理
如果非法数据类型为标量,则可以将较小的非法类型转换为较大的合法类型。例如,平台只支持i32,那么i1/i8/i16都要提升到i32,使其合法化
或者将较大的非法类型拆分成多个小的合法类型。例如,如果目标平台只支持i32,那么加法的i64操作数就是非法类型。在这种情况下,可通过整数扩展(integer expansion),将i64操作数分解成两个i32操作数,并产生相应的节点,使其合法化
如果非法数据类型为矢量,则可以将大的非法矢量操作拆分成多个,可以被平台支持的,小的矢量。或者将非法矢量操作数标量化(scalarizing),即在不支持SIMD的平台上,将矢量拆分为多个标量进行运算
指令选择
SelectionDAG 对象经过合法化和其他优化处理,DAG中的节点被映射为目标指令,这个映射过程称为指令选择
指令选择是LLVM后端中的一个重要阶段。这个阶段的输入是经过合法化的SelectionDAG。从耗时方面来说,指令选择占用了后端编译总耗时的一半。指令选择通过节点模式匹配完成DAG到DAG的转换,将SelectionDAG 节点转换为目标指令节点,也就是将LLVM IR指令转换为机器指令,所以转换后的DAG又称为machineDAG,可以用来执行基本块中的运算
LLVM的指令是一种在TableGen辅助下实现的基于表的指令选择机制。目标平台的后端可以在SelectionDAGISel::Select()函数中通过定制代码处理某些指令
其他指令通过TableGen生成的匹配表(MatcherTable)和SelectCode()函数,由LLVM默认的指令选择过程完成ISD和平台ISD到机器指令节点的映射
- 例如,在x86后端中,经过合法化的sdivrem操作就是由定制代码做指令选择
- Select()函数的输入SDNode节点如果是sdivrem,会选择对应的x86指令IDIV32r,并生成一个MachineSD节点
MachineSD 节点是SDNOde的子集,其内容是平台机器指令,但仍然以DAG节点的是形式表手。以下三种类型指令表达可在同一个DAG中共存:一般LLVM ISD节点(如ISD::ADD)、平台相关ISD节点(如X86ISD::RET_FLAG)和平台指令(如X86::ADD32ri8)
指令调度
指令选择完成后得到以machineDAG格式表示的基本块,其内容虽然是机器指令,但仍然是以DAG形式存在
而CPU/GPU 不能执行DAG,只能执行指令的线性序列。因此,需要在machineDAG上进行指令调度,确定基本块中指令的执行顺序,将DAG节点线性化
指令调度分为寄存器分配前(pre-RA) 指令调度和寄存器分配后(post-RA) 指令调度。最简单的寄存器分配前指令调度是指将DAG中的节点按拓扑结构排序,在考虑指令级的并行性的同时,生成线性发射指令序列。经过该阶段后的指令转换为MachineInstr格式的3地址。此后,DAG表示形式不再使用,可以销毁
寄存器分配后指令调度处理MachineInstr格式的机器指令,并可以利用物理寄存器信息和硬件架构特性,根据性能指标需要,对指令顺序做调整
寄存器分配
经过指令阶段产生的代码是SSA形式的,代码中可以使用无限多的虚拟寄存器,而硬件平台的物理寄存器数量是有限的
如果物理寄存器数量不足以容纳所有虚拟寄存器,虚拟寄存器则会溢出(spill)到内存。因此,寄存器分配的目的是为虚拟寄存器分配物理寄存器,并优化寄存器分配过程,使虚拟寄存器的溢出代价最小化
虚拟寄存器到物理寄存器的映射有两种方式
- 直接映射和间接映射
直接映射利用TargetRegisterInfo 和 MachineOperand 类获取加载/保存指令插入位置,间接映射利用VirtRegMap类处理加载/保存指令
LLVM中的寄存器分配算法有四种
- 基本寄存器分配
- 快速寄存器分配
- PBQP 寄存器分配
- 贪厌寄存器分配
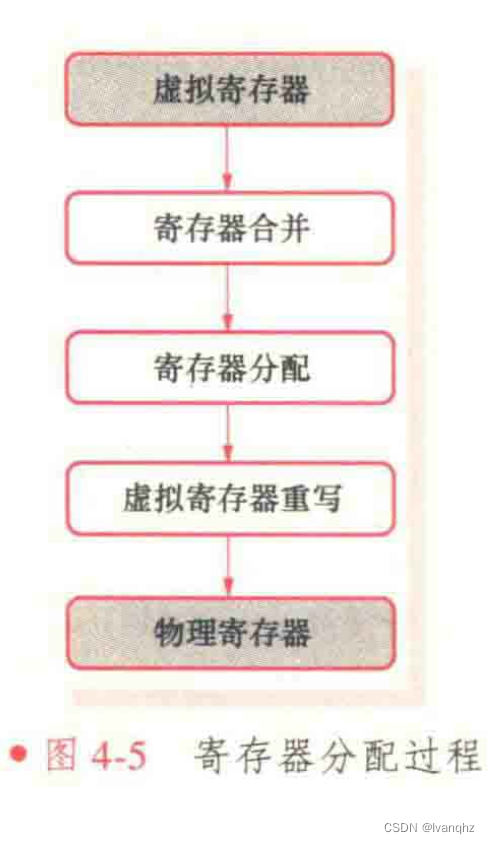
寄存器分配过程依赖其他分析pass的分析结果,其中最重要的是寄存器合并(register coalese) pass 和虚拟寄存器重写(virtual register rewrite) pass
由于二地址转换过程中生成复制指令,从而引入了新的虚拟寄存器,这对后续的物理寄存器分配带来了压力
复制指令连接的两个虚拟寄存器的值相同,因此,在某些情况下可以合并这些虚拟寄存器的生存期(interval),使源和目的寄存器共用一个物理寄存器,这样也可以减少一条复制指令,这个过程称为合并(coalesce)
生存期是程序的一对起点和终点。从起点开始,某个值被产生并在被某个临时位置持有,直到这个值在终点被使用和销毁。寄存器合并pass实现类是MaicheFunctionPass 类的子类,其目的主要是消除冗余的复制指令,实现代码<llvm_root>/llvm/lib/CodeGen/RegisterCoalescer.cpp
在寄存器合并时,joinAllIntervals()函数遍历复制操作列表,joinCopy()函数从复制机器指令中生成合并对(Coalescerpair), 并将复制合并
寄存器分配pass 为每个虚拟寄存器分配物理寄存器后,寄存器分配结果保存在虚拟机寄存器映射表VirtRegMap中,这实际是一张从虚拟机寄存器到物理寄存器的映射表
接下来,虚拟寄存器重写pass执行代码清除工作,并根据VirtRegMap中的映射关系,将MIR中的虚拟寄存器替换成指定的物理寄存器,同时删除相同寄存器之间的复制指令
代码发射
代码发射阶段借助机器代码框架(machine code framework) 或 LLVM JIT(just-in-time)机制,以MCInstr格式的指令取代MachineInstr 的 指令代码,并发射汇编或二进制代码。和MachineInstr格式相比,MCInst 格式携带的程序信息较少
在LLVM中有三种持续演进的JIT执行引擎实现: JIT 类、MCJIT类和ORCJIT类。目前的LLVM已经不再支持JIT类
MCJIT类是LLVM中JIT编译的一种新的实现方式,而ORCJIT类是MCJIT类的功能扩展。机器代码框架的作用是对函数和指令做底层处理
与其他后端模块相比,机器代码框架设计的目的是辅助产生基于LLVM的汇编器和反汇编器
例如,之前的NVPTX后弹没有提供集成的汇编器,编译过程只能进行到发射PTX代码为止。然后,以PTX代码为输入,依赖外部工具(PTXAS)完成其余的后端编译步骤
而机器代码框架提供了统一的指令表示,该框架可被汇编器、反汇编器、汇编打印和MCJIT共享。当编译器后端需要增加新的目标平台ISA支持时,只需要在机器代码框架中实现一次指令编码,而不需要对MCJIT做改动,因为机器代码框架中实现会被所有子系统共享
 @w=600
@w=600
在LLVM的几乎所有目标平台后端中,都有派生自AsmPrinter类的汇编代码打印模块。
例如,AMDGPU 后端的 AMDGPUAsmPrinter类。AsmPrinter类是MachineFunctionPass 类的子类,其作用是通过调用目标平台后端的MCInstLoweing接口,将MachineFunction函数转换为机器码标签构造
AsmPrinter 模块的代码发射功能由AsmPrinter::emitFunctionBody() 函数实现。该函数首先调用emitFunctionHeader()函数,发射当前MachineFunction函数的头,如函数中引用的常量、序言(prologue)数据等
然后,emitFunctionBody() 函数遍历MachineFunction函数中的所有基本块,以及基本块中的每一条机器指令,并将不同操作码(Opcode)的机器指令分发到不同的发射函数做后续处理
目标平台相关机器指令由emitInstruction()函数处理,目标平台后端实现的AsmPrinter子类应重写(override)该函数
- 例如,AMDGPU后端的重写函数为AMDGPUAsmPrinter::emitInstructioin()
目标平台后端的emitInstruction()函数以MachineInstr 机器指令为输入,通过调用MCInstLowering 接口的lower()函数,将MachineInstr机器指令降级为MCInst实例。
目标平台后弹提供MCInstLowering接口子类实现(如AMDGPU后端的AMDGPUMCInstLower)类,并由其中的定制代码产生MCInst实例
AsmPrinter::EmitToStreamer()函数通过MCStreamer实例对生成的MCInst指令流做进一步处理。
此时有两个选项:发射汇编或二进制代码。MCStreamer 类处理MCInst指令流时,通过MCAsmStreamer和MCObjectStramer两个子类,将MCInst指令流发射到选定的输出
MCASMStreamer子类将MCInst指令流转为汇编指令,MCObjectStreamer子类将MCInst指令流转为二进制指令
如果llc命令行选项指定的输出类型为汇编代码,则MCAsmStreamer::emitInstrunction()函数被调用,并通过目标平台后端提供MCInstPrinter子类(如AMDGPUInstPrinter) 实例,调用其printInst()函数,将汇编代码打印到文件中
如果llc命令行选项指定的输出类型为二进制代码,则MCObjectStreamer::emitInstrunction()函数被调用,并使用自定义backend提供的MCCodeEmitter子类(如AMDGPUMCCodeEmitter) 实例,调用其encodeInstrunction() 生成二进制代码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









