







前言
题目 **Label Contrastive Coding based Graph Neural Network for Graph Classification **
作者团队 Yuxiang Ren, Jiyang Bai,Jiawei Zhang
作者单位 佛罗里达州立大学
论文链接 https://arxiv.org/pdf/2101.05486.pdf
本文来自佛罗里达州立大学,作者使用实例间的细粒度类别信息,基于标签对比损失,设计了一种基于标签对比编码的图分类网络,实现了监督式的对比学习。
之前学习的基于对比学习的数据都是无标签的,这个数据是有标签的,监督式的对比学习。
本文的主要贡献如下:
(1)提出了一种基于标签对比编码的图神经网络(LCGNN),从而使用更具判别能力的信息强化监督式的 GNN。
(2)标签对比损失将对比学习扩展到了监督学习环境下,其中我们可以引入标签信息,从而保证类内的聚合性和类间的可分性。
(3)提出了动量更新图编码器和动态标签存储库来实现监督式的对比学习。
Abstract
在各种各样的应用领域中,图分类都是一个重要的研究课题。为了学习一个图分类模型,目前被最为广泛使用的监督式分量是使用输出层的表征和分类损失(例如,交叉熵损失加上 softmax 或 Margin loss)。事实上,实例之间的判别式信息粒度更细,这有利于图分类任务。为了更有效、更全面地利用标签信息,本文提出了一种新的基于标签对比编码的图神经网络(LCGNN)。LCGNN 仍然利用分类损失来保证类的可判别性。同时,LCGNN 利用自监督学习中提出的标签对比损失来促进实例级的类内聚合性和类间可分性。为了实现对比学习,LCGNN 引入了动态标签存储库和动量更新编码器。
1 Introduction
现实世界中许多领域的应用都表现出了图数据结构的良好特性,如社交网络[15]、金融平台[20]和生物信息学[5]。图分类的目的是识别数据集中图的类标签,这是众多应用中的一个重要问题。例如,在生物学中,蛋白质可以用图形表示,其中每个氨基酸残基是一个节点,残基之间的空间关系(距离、角度)是图形的边。对表示蛋白质的图形进行分类,有助于预测蛋白质接口[5]。
近年来,图神经网络(GNNs)在图分类任务中取得了出色的性能[29,33]。GNNS旨在将节点转换为低维特征,以保留图结构信息和属性[34]。当将GNNS应用于图分类时,标准的方法是为图中的所有节点生成特征,然后将所有这些节点特征汇总为整个图的表示,例如使用一个简单的求和或在节点特征集[31]上运行的神经网络。对于整个图的表示,通常使用监督组件来实现图分类的目的。最终输出层和分类损失(例如,交叉熵损失和softmax或边际损失)是许多现有gnn中最常用的监督组件[29,28,32,6]。这个监督组件关注类的可鉴别性,而忽略了实例级的鉴别表示。最近学习更强表示来服务于分类任务的一个趋势是用尽可能多的判别信息来强化模型[4]。明确地说,考虑了类内聚合性和类间可分性[14]的图表示在图分类任务中更有效。
受最近的自监督学习[3]和对比学习[7,18]的启发,对比损失[17]能够提取额外的鉴别信息来提高模型的性能。最近使用对比损失进行表示学习的研究[8,18,35]主要是在无监督学习的设置下进行的。这些对比学习模型将每个实例视为一个独立的类。同时,辨别这些实例是他们的学习目标[7]。在计算机视觉[26]领域中,一系列对比学习已被证明能够有效地学习更细粒度的实例级特征。因此,我们计划利用图分类任务上的对比学习来弥补监督组件忽略实例层的判别信息的不足。然而,在应用对比学习时,固有的较大的类内变化可能会给图分类任务[14]引入噪声。此外,现有的基于对比学习的GNNS(如GCC[18])分离了模型的训练前步骤和微调步骤。与端到端gnn相比,通过对比学习学习到的图表示很难直接用于图分类等下游应用任务。
为了解决图分类的问题,我们提出了基于标签对比编码的图神经网络(LCGNN),该网络利用标签对比损失来同时增强实例级的类内聚合性和类间可分性。与现有的使用单个正实例的对比学习不同,标签对比编码 导入标签信息,并将具有相同标签的实例视为多个正实例。通过这种方式,具有相同标签的实例可以拉得更近,而具有不同标签的实例将彼此推开。同时考虑了类内聚合性和类间可分性。标签对比编码可以看作是对编码器进行字典查找任务[7]的训练。为了构建一个广泛且一致的字典,我们提出了一个动态标签存储库和一个动量更新的图形编码器。同时,LCGNN还使用了Classification Loss来保证分类的可分辨性。LCGNN可以利用标签信息从实例级和类级更有效和全面地允许用更少的标签数据来实现比较性能,可以认为本质上是一种标签增强。我们验证性能在8个基准图数据集上,LCGNN对图分类任务的影响。LCGNN在7个图数据集中实现了SOTA性能。是什么更重要的是,当使用较少的训练数据时,LCGNN的表现优于基线方法,从而更全面地验证了其对标签信息的学习能力。
The contributions of our work are summarized as follows:
我们提出了一种新的基于标签对比编码的图神经网络(LCGNN),使有监督的图神经网络具有更多的鉴别信息。
标签对比损失将对比学习扩展到监督设置,在监督设置中可以导入标签信息,以保证类内的聚合性和类间的可分性。
提出了动量更新的图编码器和动态标签记忆库来支持我们的监督对比学习。
我们在8个基准图数据集上进行了广泛的实验。LCGNN不仅在多个数据集上实现了SOTA性能,而且可以用较少的标记训练数据提供可比较的结果。
2 Related Works
几种不同的技术被提出来解决图的分类问题。一个重要的类别是基于graph kernel的方法,它学习一个graph kernel来衡量图之间的相似性,以区别划分图标签[25]。The Weisfeiler-Lehman subtree kernel (WL) [21],Multiscale Laplacian graph kernels (MLG) [13], and Graphlets kernel(GK) 都是具有代表性的图核。另一个关键类别是基于深度学习的方法。Deep Graph Kernel (DGK) [30], Anonymous Walk Embeddings (AWE), and Graph2vec 都采用了深度学习框架进行提取图分类任务中的图特征。随着图神经网络(GNNS)的兴起,通过学习图的表示,许多GNNS也被用于图的分类任务,下面将对此进行介绍。
Graph Neural Network图神经网络
图神经网络通过递归的邻域聚合方案[29]学习低维图表示。导出的图表示可以用于各种下游任务,如图分类和top-k相似度搜索。根据学习方法,目前能够服务于图分类的GNN可以分为端到端模型和训练前模型。端到端模型通常在监督或半监督设置下,以优化分类丢失或互信息为目标,主要包括GIN[29]、CapsGNN[28]、DGCNN[32]和InfoGraph[23]。预先训练的gnn使用特定的训练前任务[9]来学习无监督设置下的图的一般表示。为了执行图分类任务,将使用一部分标签数据对模型[18]进行微调。
Contrastive Learning 对比学习
对比学习已被广泛用于无监督学习,通过训练编码器,可以捕获数据的相似性。对比损失通常是一个计分函数,它增加单个匹配实例的分数,减少多个不匹配实例的分数。在图领域,DGI是第一个利用对比学习思想的GNN模型,其中节点和图表示之间的互信息被定义为对比度量。HDGI将该机制扩展到异构图。InfoGraph在半监督图级表示学习中执行对比学习。当面对监督学习的任务,如图分类时,我们还需要利用对比学习的优势来捕获相似性。GCC利用对比学习预训练模型,通过微调来服务于下游的图分类任务。与它们相比,我们的方法是一个端到端模型,并执行标签对比编码,以鼓励实例级的类内聚合性和类间可分性
3 Proposed Method
在本节中,我们介绍了基于标签对比编码的图神经网络(LCGNN)。在介绍LCGNN之前,我们先对图分类做一个初步的介绍。
3.1 Preliminaries
图分类的目标是根据图的结构信息和节点内容预测图的类标签。在形式上,我们这样表示:
给定一组标记图 G L = { ( G 1 , y 1 ) , ( G 2 , y 2 ) , … } \mathbb{G}_{L}=\left\{\left(\mathcal{G}_{1}, y_{1}\right),\left(\mathcal{G}_{2}, y_{2}\right), \ldots\right\} GL={(G1,y1),(G2,y2),…}和 y i y_{i} yi是 G i G_{i} Gi对应的标签。
任务是学习一个分类函数 f f f: G ⟶ Y \mathcal{G} \longrightarrow \mathbb{Y} G⟶Y对未知图 G U G_{U} GU进行预测。
3.2 LCGNN Architecture Overview
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MLf8upu2-1656589160300)(https://secure2.wostatic.cn/static/4TJGcWY8SSKqTFFSWw44bS/image.png)]](https://img-blog.csdnimg.cn/6ceb62c865564236ac0840325ac76208.png)
Fg1.LCGNN的高层结构。LCGNN使用混合损失训练图编码器**** f q f_{q} fq和图分类器。Label Contrastive Loss标签对比损失 和Classification Loss分类损失构成混合损失。LCGNN中使用的分类损失是交叉熵损失。标签对比损失由字典查找任务计算。query是输入图miniBatch的每个图,字典是一个可以不断更新已知标签图表示的存储库。存储库中的图表示由动量更新的图编码器 f k f_k fk来更新。经过训练,学习到的图编码器 f q f_{q} fq和图分类器可以用于图分类任务。
我们提出的LCGNN的学习过程如图1所示。通常,对于输入的图,我们需要通过高性能的图编码器来提取潜在的特征,以服务于图的分类。为了配合提出的混合损失(Label contrast loss & classification Loss), LCGNN包含两个图编码器 f k f_{k} fk和 f q f_{q} fq,分别用于编码输入key graph和query graph。Label contrast Loss标签对比损失 通过保持中间判别表示,鼓励实例级的类内聚合性和类间可分性,而分类丢失则确保类级的可分性。一种包含关键图表示和相应标签的动态存储库用于标签对比损耗计算。图分类器以图编码器fq的表示作为输入来预测图标签。下面我们将详细阐述每个组件以及LCGNN的学习过程。
Label contrast Loss标签对比损失:对比学习 需要定义正负样本 也就是让正样本相近的更相近,负样本更原理
Classification Loss 分类丢失则确保类级的可分性 - 这个类是指的大类,狗猫等
3.3 Label Contrastive Coding
已有的对比学习已被证明是一种成功的方法去训练编码器,可以捕获图形数据背后的通用结构信息。在图分类任务中,与通用的结构模式相比,我们主要关注与分类相关的结构模式。因此,我们提出的标签对比编码学习去区分具有不同类标签的实例,而不是将每个实例视为自身的一个不同类,并与其他不同的类进行对比。
常见的对比学习loss:
对比学习可以被认为是通过字典查找任务从而完成编码器学习。我们可以这样描述对比学习。给定一个编码query q q q和一个包含m个编码keys {k1, k2,…, km},则只有一个正样本 k + k+ k+(通常与q来自同一个实例)。当 q q q与正样本 k + k+ k+相似,而与负键q(字典中所有其他键)不同时,这种对比学习的损失较低。
一个广泛使用的对比损失是InfoNCE :
L = − log exp ( q ⋅ k + / τ ) ∑ i = 1 m exp ( q ⋅ k i / τ ) \mathcal{L}=-\log \frac{\exp \left(\mathbf{q} \cdot \mathbf{k}_{+} / \tau\right)}{\sum_{i=1}^{m} \exp \left(\mathbf{q} \cdot \mathbf{k}_{i} / \tau\right)} L=−log∑i=1mexp(q⋅ki/τ)exp(q⋅k+/τ)
这里,τ是温度超参数[26]。本质上,InfoNCE的损失是一种分类损失,目的是将q从m = 1类分类到与k+相同的类。
但是我们已知标签,肯定不能直接使用这个loss
但是,在面对图分类任务时,类标签已经确定,我们希望在训练数据中导入已知的标签信息,以辅助对比学习服务于图分类任务。这样,我们设计了标签对比编码
Define similar and dissimilar 在图分类任务中,我们寻求将具有相同标签的实例拉得更近,而具有不同标签的实例将彼此推开。因此,在标签对比编码中,我们将具有相同标签的两个实例视为相似对 正样本,而将由不同标签实例组成的一对实例视为不同对 负样本。
这里看出和Moco的区别,Moco是选取一个正样本,来自其本身通过不同的数据增强方法,其余看作负样本。而本文是把具有相同的实例看作 正样本 不同标签实例看作负样本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tCsB5Lto-1656589160303)(https://secure2.wostatic.cn/static/qqDWWTaP7aENdX9vEe2Tx2/image.png)]](https://img-blog.csdnimg.cn/1fb403eb032845febf6b56a3525d6f24.png)
Fig. 2.Label Contrastive Loss.query图Gq和key图Gk分别用fq和fk编码为低维表示q和k。 k 1 k_1 k1和 k 2 k_2 k2与q相同的标签记为正样本。由于标签不同,K3和k4是负样本。标签对比损失 促使模型区分相似的一对(Gq, Gk1)和(Gq, Gk2)和不同的实例对(正样本对),如(Gq, Gk3)。
Label contrative loss 仍然从字典查找的角度来看,给定一个有标签的编码query(q, y)和一个由m个有标签编码 k e y s ( k 1 , y 1 ) , ( k 2 , y 2 ) , … , ( k m , y m ) 的 字 典 , 标 签 对 比 编 码 中 的 正 样 本 keys{{(k_{1}, y_{1}), (k_{2}, y_{2}),…,(k_{m}, y_{m})} }的字典,标签对比编码中的正样本 keys(k1,y1),(k2,y2),…,(km,ym)的字典,标签对比编码中的正样本k+ 是 是 是y_{i} = y 的 键 的键 的键k_i 。 标 签 对 比 编 码 在 字 典 中 查 找 q u e r y q 匹 配 的 正 键 。标签对比编码在字典中查找query q匹配的正键 。标签对比编码在字典中查找queryq匹配的正键k_i 。 对 于 编 码 后 的 。对于编码后的 。对于编码后的query (q, y) , 其 标 签 对 比 损 失 ,其标签对比损失 ,其标签对比损失\mathcal{L}_{L C}$计算为
L L C ( q , y ) = − log ∑ i = 1 m 1 y i = y ⋅ exp ( q ⋅ k i / τ ) ∑ i = 1 m exp ( q ⋅ k i / τ ) \mathcal{L}_{L C}(\mathbf{q}, y)=-\log \frac{\sum_{i=1}^{m} \mathbb{1}_{y_{i}=y} \cdot \exp \left(\mathbf{q} \cdot \mathbf{k}_{i} / \tau\right)}{\sum_{i=1}^{m} \exp \left(\mathbf{q} \cdot \mathbf{k}_{i} / \tau\right)} LLC(q,y)=−log∑i=1mexp(q⋅ki/τ)∑i=1m1yi=y⋅exp(q⋅ki/τ)
这里,语句 1 statement ∈ { 0 , 1 } \mathbb{1}_{\text {statement }} \in\{0,1\} 1statement ∈{0,1}是一个二进制指示符,如果语句为真,则返回1。我们举例说明图2中的标签对比损失以供参考。在LCGNN中,key 的图表示存储在动态存储库中。为了简单起见,我们没有在图2中显示。我们接下来会介绍动态存储库及其更新过程。
The dynamic memory bank在标签对比编码中,m大小的字典是必要的。我们使用dynamic memory bank作为字典。为了充分利用标签信息,存储库的大小等于有标签的图集 G L G_{L} GL的大小,即 m = ∣ G L ∣ m = |G_L| m=∣GL∣。Memory bank 存储库既包含编码的低维key的图表示,也包含相应的标签,即 { ( k 1 , y 1 ) , ( k 2 , y 2 ) , … , ( k ∣ G L ∣ , y ∣ G L ∣ ) } \left\{\left(\mathbf{k}_{1}, y_{1}\right),\left(\mathbf{k}_{2}, y_{2}\right), \ldots,\left(\mathbf{k}_{\left|\mathbb{G}_{L}\right|}, y_{\left|\mathbb{G}_{L}\right|}\right)\right\} {(k1,y1),(k2,y2),…,(k∣GL∣,y∣GL∣)}.基于MoCo中的结论,在训练过程中图形编码器 f k f_k fk编码器进化时,应尽可能保持key的图表示的一致性。因此,在每个训练时期,新编码的key图会动态地替换存储库中的旧密钥图。
3.4 Graph Encoder Design
对于给定的图 G q G_q Gq和 G k G_k Gk, LCGNN采用两个图编码器 f q f_q fq和 f k f_k fk将其编码为低维表示。
q = f q ( G q ) k = f k ( G k ) \begin{aligned} \mathbf{q} &=f_{q}\left(\mathcal{G}^{q}\right) \\ \mathbf{k} &=f_{k}\left(\mathcal{G}^{k}\right) \end{aligned} qk=fq(Gq)=fk(Gk)
LCGNN中, f q f_q fq和 f k f_k fk具有相同的结构。图神经网络已经证明了它对图结构数据的强大编码能力。许多潜在的图神经网络可以作为LCGNN中的图编码器。
LCGNN中考虑了两种编码器。第一种是图同构网络Graph Isomorphism Network(GIN)[29]。GIN使用多层感知器(MLPs)来构思聚合方案,并将节点表示更新为
h v k = MLP ( k ) ( ( 1 + ϵ ( k ) ) + ∑ u ∈ N ( v ) h u ( k − 1 ) ) h_ {v}^{k}=\operatorname{MLP}^{(k)}\left(\left(1+\epsilon^{(k)}\right)+\sum_{u \in \mathcal{N}(v)} h_{u}^{(k-1)}\right) hvk=MLP(k)⎝⎛(1+ϵ(k))+u∈N(v)∑hu(k−1)⎠⎞
式中, ϵ \epsilon ϵ为可学习参数或固定标量,k表示第k层。在给定各个节点的表示情况下,由GIN提出了读取函数生成整个图g的表示g,用于图分类
任务
g = ∥ k = 1 K ( SUM ( { h v k ∣ v ∈ G } ) ) \boldsymbol{g}=\|_{k=1}^{K}\left(\operatorname{SUM}\left(\left\{h_{v}^{k} \mid v \in \mathcal{G}\right\}\right)\right) g=∥k=1K(SUM({hvk∣v∈G}))
这里,k是连接运算符。
我们考虑的第二个编码器是带结构学习的层次图池化(HGP-SL)[33]。HGP-SL将图池化和结构化学习整合到一个统一的模块中,以生成图的分层表示。HGP-SL提出了一种图池操作,识别信息节点子集,形成一个新的但更小的图。关于基于曼哈顿距离的池化操作的详细信息可以引用到[33]。对于图G, HGPSL多次重复图的卷积和池化操作,在不同的层中实现多个子图:H1, H2,…,HK。HGP-SL使用mean-pooling和max-pooling的连接来聚合子图中的所有节点表示,如下所示
r k = R ( H k ) = σ ( 1 n k ∑ p = 1 n k H k ( p , : ) ∥ max q = 1 d H k ( : , 1 ) ) \mathbf{r}^{k}=\mathcal{R}\left(\mathbf{H}^{k}\right)=\sigma\left(\frac{1}{n^{k}} \sum_{p=1}^{n^{k}} \mathbf{H}^{k}(p,:) \| \max _{q=1}^{d} \mathbf{H}^{k}(:, 1)\right) rk=R(Hk)=σ⎝⎛nk1p=1∑nkHk(p,:)∥q=1maxdHk(:,1)⎠⎞
式中σ为非线性激活函数。Nk为第k层子图的节点数。为了实现整个图g的最终表示g,利用另一个读出函数将不同层的子图进行组合
g = SUM ( r k ∣ k = 1 , 2 , … , K ) \boldsymbol{g}=\operatorname{SUM}\left(\mathbf{r}^{k} \mid k=1,2, \ldots, K\right) g=SUM(rk∣k=1,2,…,K)
在实验部分,我们将展示在LCGNN中使用GIN和HGP-SL作为图编码器的性能以及分析。
3.5 LCGNN Learning
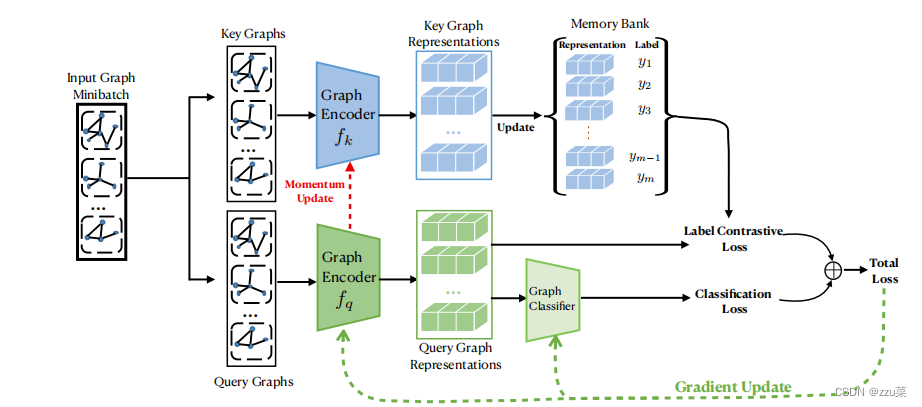
图1提供了训练过程说明。在训练过程中,LCGNN的输入是一批标记好的图 G b ⊂ G L \mathbb{G}_{b} \subset \mathbb{G}_{L} Gb⊂GL。 对于每个小批迭代,key图集合和query图集合相同为 G b \mathbb{G}_{b} Gb.图编码器 f q f_q fq和 f k f_k fk初始化参数相同 ( θ q = θ k ) (θq = θk) (θq=θk).The memory bank’s size is equal to the size of the set of labeled graphs ∗ ∗ G L ∗ ∗ ** \mathbb{G}_{L}** ∗∗GL∗∗.带有 y i y_i yi标签的标记图 G i G_i Gi被分配一个随机表示来初始化存储库。将key图集合用 f k f_k fk编码器编码为低维key图表示 K \mathbb{K} K,从而替换存储库中相应的表示。query图集合由fq编码,以query图表示 Q \mathbb{Q} Q,而 Q \mathbb{Q} Q也是图分类器的输入。在LCGNN中,逻辑回归层作为图分类器。根据图分类器的输出,可以计算出分类损失
L C l a = − 1 ∣ Q ∣ ∑ q i ∈ Q ∑ j ∈ Y 1 q i , j log ( p q i , j ) \mathcal{L}_{C l a}=-\frac{1}{|\mathbb{Q}|} \sum_{\mathbf{q}_{i} \in \mathbb{Q}} \sum_{j \in \mathbb{Y}} \mathbb{1}_{\mathbf{q}_{i}, j} \log \left(p_{\mathbf{q}_{i}, j}\right) LCla=−∣Q∣1qi∈Q∑j∈Y∑1qi,jlog(pqi,j)
其中是1一个二进制指示符(0或1),表示标签j是否是编码查询图 q i q_i qi的正确分类。( p q i p_{q_i} pqi, j j j)为预测概率
Q和memory bank一起工作,实现前面所述的标签对比编码。根据公式2,小批量Gb的标签对比损失为:
L L C = − 1 ∣ Q ∣ ∑ q i ∈ Q L L C ( q i , y q i ) \mathcal{L}_{L C}=-\frac{1}{|\mathbb{Q}|} \sum_{\mathbf{q}_{i} \in \mathbb{Q}} \mathcal{L}_{L C}\left(\mathbf{q}_{i}, y_{\mathbf{q}_{i}}\right) LLC=−∣Q∣1qi∈Q∑LLC(qi,yqi)
为了更有效、更全面地利用标签信息对模型进行训练,我们结合标签对比损失(label contrast loss)和分类损失(Classification loss),尽量减少以下混合损失:
L total = L C l a + β L L C \mathcal{L}_{\text {total }}=\mathcal{L}_{C l a}+\beta \mathcal{L}_{L C} Ltotal =LCla+βLLC
这里,超参数β控制标签对比损失和分类损失之间的相对权重。 L total \mathcal{L}_{\text {total }} Ltotal 背后的动机是
L L C \mathcal{L}_{L C } LLC鼓励实例级的类内聚合性和类间可分离性,
而 L C l a \mathcal{L}_{C l a} LCla确保类的可区分性。
图编码器fq和图分类器可以根据损耗Ltotal进行端到端的反向传播更新。fk的参数θk采用基于动量的修正9机制,而不是反向传播方式。具体来说,动量更新过程为
θ k ⟵ α θ k + ( 1 − α ) θ q \theta_{k} \longleftarrow \alpha \theta_{k}+(1-\alpha) \theta_{q} θk⟵αθk+(1−α)θq
其中α[0,1)为控制fk演化速度的动量权重。我们使用这种基于动量的更新机制,不仅可以减少反向传播的开销,而且可以在编码器不断改进的情况下,保持存储库中关键图表示的一致性。
在完成模型训练后,学习到的图编码器fq和图分类器可以用于对未标记的图GU进行图分类任务。














 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









