







✨ 1: Qwen2
Qwen2 是一种多语言预训练和指令调优的语言模型,支持128K上下文长度并在多项基准测试中表现优异。

Qwen2(全称“Qwen Qwen”,简称Qwen)是一个先进的大语言模型家族,在其前身Qwen1.5的基础上进行了重大提升和改进。Qwen2系列包含五种规模的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。这些模型不仅在中文和英文数据上进行了训练,还新增了27种其他语言的数据,从而显著提升了其多语言处理能力。
Qwen2在多个基准测试中表现出色,不仅在通用任务上具有强大的性能,在编程和数学方面的表现也得到了显著提高。此外,Qwen2-7B-Instruct和Qwen2-72B-Instruct模型支持长达128K tokens的上下文长度,进一步扩展了模型的应用场景。
Qwen2凭借其多语言和多任务处理能力,在各类自然语言处理、代码生成和数学计算等领域展现出广泛的应用前景。
地址:https://github.com/QwenLM/Qwen2
✨ 2: V-Express
V-Express人像照片生成视频的模型,逐步训练以生成高质量的肖像视频。
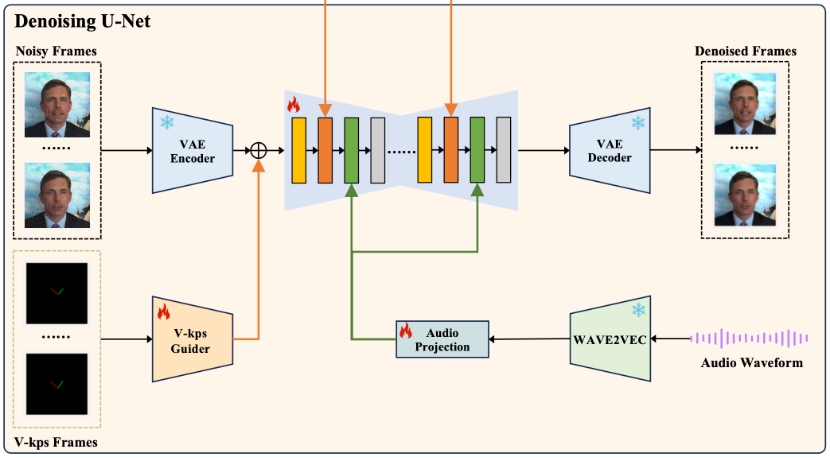
V-Express 是腾讯开源的一种用于人像视频生成的条件Dropout渐进训练方法,能够在生成视频时平衡多种控制信号。随着单张图像生成视频的应用越来越普遍,生成模型常被用来增强各种控制信号。然而,控制信号的强弱存在很大差异,比如文本、音频、图像参考、姿态、深度图等。我们在研究中发现,音频信号常常被更强的信号(如姿态和原始图像)干扰,导致生成的效果不理想。为了解决这一问题,我们提出了V-Express方法,通过一系列渐进的Dropout操作平衡不同的控制信号,使得较弱信号也能有效控制生成过程,从而兼顾姿态、输入图像和音频的生成能力。
通过这种方式,V-Express 可用于生成高质量的说话人像视频,广泛应用于视频创作、虚拟主播以及其他娱乐和研究领域。
地址:https://github.com/tencent-ailab/V-Express
✨ 3: 快手版Sora「可灵」
快手版Sora「可灵」开放测试,生成超长1080p视频,模拟真实物理与复杂运动。

快手版Sora「可灵」是一款全新的国产视频生成大模型,已开放测试应用。该模型基于类似Sora的技术路线,并结合多项自研技术能生成包括复杂运动在内的长达2分钟、分辨率高达1080p的视频。与实验室演示不同,可灵已在快影APP中正式上线、开放邀测,且提供720P视频生成及即将开放的竖版视频生成能力。
可灵大模型能准确模拟物理世界特性和复杂运动,并具备强大的概念组合和想象力。技术方面,采用类Sora的DiT结构,并在隐空间编/解码、时序建模等模块进行了独特优化。此外,通过构建高质量数据筛选方案,提高模型运算效率和训练效果,支持多种控制信息输入。
快手不仅将可灵应用于文生视频,还推出了基于该模型的“AI舞王”等应用。未来,还将上线图生视频功能。作为短视频领域的头部厂商,快手致力于将大模型技术应用于实际场景,通过快影APP让用户体验AI视频创作的能力。
地址:https://kling.kuaishou.com/
✨ 4: fairseq
fairseq是一个用于训练自定义翻译、摘要和语言模型等序列模型的工具包。
Fairseq是一个由Facebook开发的序列建模工具包,旨在帮助研究人员和开发者训练自定义模型,用于翻译、摘要生成、语言建模以及其他文本生成任务。它实现了多种序列建模方法,包括卷积神经网络(CNN)、轻量和动态卷积模型、长短期记忆网络(LSTM)和自注意力变换器(Transformer)等。
Fairseq除了一些预训练模型外,还提供详细的文档和示例,帮助用户快速上手。
地址:https://github.com/facebookresearch/fairseq
✨ 5: GLM-4
GLM-4是智谱AI推出的最新多语言、多模态预训练模型系列,性能卓越,支持多种高级功能。
GLM-4 系列是智谱 AI 推出的最新一代预训练模型,包含多个版本和模型类型,其中 GLM-4-9B 和 GLM-4-9B-Chat 是其中的关键开源版本。这些模型在多个方面(如语义、数学、推理、代码以及知识)都表现出色,并且超越了 Llama-3-8B。
- 高性能:在多项数据集评测中,无论是 GLM-4-9B 还是 GLM-4-9B-Chat,都表现出卓越的性能。
- 多轮对话:支持多轮对话,具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理等功能。
- 多语言支持:支持26种语言,包括日语、韩语和德语等。
- 多模态能力:GLM-4V-9B 具备视觉理解能力,可以处理高分辨率图像,并在感知推理、文字识别、图表理解等任务上表现优异。
使用 GLM-4 系列模型,可以快速部署高性能的多功能 AI 应用,覆盖从自然语言处理、编程辅助到多模态理解的各种需求。
地址:https://github.com/THUDM/GLM-4
更多AI工具,参考国内AiBard123,Github-AiBard123 公众号:每日AI新工具



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











