






自然语言处理问题中,一般以词作为基本单元,例如我们想要分析 “我去过华盛顿州” 这句话的情感,一般的做法是先将这句话进行分词,变成 我,去过,华盛顿州,由于神经网络无法处理词,所以我们需要将这些词通过某些办法映射成词向量。词向量是用来表示词的向量,也可被认为是词的特征向量。把词映射为实数域向量的技术也叫词嵌入(word embedding)
为何不采用 one-hot 向量
假设词典中不同词的数量为N ,每个词可以和从 0 到 N-1 的连续整数一一对应。假设一个词的相应整数表示为 i ,为了得到该词的 one-hot 向量表示,我们创建一个全 0 的长为 N 的向量,并将其第 i 为设位 1
然而,使用 one-hot 词向量并不是一个好选择。一个主要的原因是,one-hot 词向量无法表达不同词之间的相似度,例如,任何一对词的 one-hot 向量的余弦相似度都为 0
 word2vec
word2vec
2013 年,Google 团队发表了 word2vec 工具。word2vec 工具主要包含两个模型:跳字模型(skip-gram)和连续词模型(continuous bag of words,简称 CBOW),以及两种高效训练的方法:负采样(negative sampling)和层序 softmax(hierarchical softmax)。值得一提的是,word2vec 词向量可以较好地表达不同词之间的相似度和类比关系
跳字模型
在跳字模型中,我们用一个词来预测它在文本序列周围的词。例如,给定文本序列 “the”,“man”,“hit”,“his”,“son”。设背景窗口大小为 2, 跳字模型所关心的是,给定 “hit”,生成它邻近词 “the”,“man”.“his”,“son” 的概率(在这个例子中,“hit” 叫中心词,“the”,“man”,“his”,“son” 叫背景词),即P( “the”,“man”.“his”,“son” |“hit”)
假设在给定中心词的情况下,背景词的生成是相互独立的,那么上式可以改写成:
P(“the”|“hit”) * P(“man”|“hit”) * P(“his”|“hit”) * P(“son”|“hit”)
我们来描述一下跳字模型。假设词典大小为 V,我们将词典中的每个词与 0 到 V-1 的整数一一对应:词典索引集 { 0,1,2,…|V-1| }。一个词在该词典中所对应的整数称为词的索引,给定一个长度为T的文本序列, t 时刻的词为 w t w_t wt 。当时间窗口大小为 m 时,跳字模型需要最大化给定任一中心词生成背景词的概率:
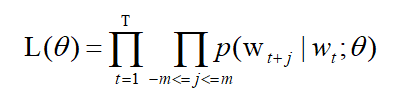
取对数和相反数方便计算得到:
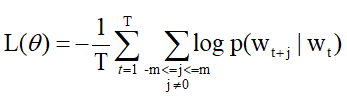
我们可以用 v 代表中心词的词向量, u 代表背景词的词向量。换言之,对于词典中一个索引为 i 的词,它本身有两个向量 v i v_i vi和 u i u_i ui进行表示,在计算的过程中,根据其所处的角色不同,选择不同的词向量。词典中所有词的这两种向量正是跳字模型所需要学习的参数。为了将模型参数植入损失函数,我们需要使用模型参数表达损失函数中的中心词生成背景词的概率。假设中心词的概率是相互独立的。给定中心词 w c w_c wc在词典中的索引为c ,背景词 w o w_o wo在词典中的索引为 o ,损失函数中中心词生成背景词的概率可以使用 softmax 函数进行定义:
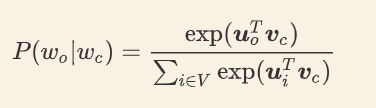
**我理一下,说白了,**中心词会生成一个对应的词向量,背景词和噪声词也会生成各自对应的词向量,我们的目标就是让中心词生成的词向量与背景词生成的词向量尽可能接近,同时要与噪声词生成的词向量尽可能疏远。
可以看一下skip gram的整个流程:
















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









