







1、2013年,Word2vec模型,Google公司
无监督模型,与语境无关
2、2014年,GloVe模型,Stanford
GLoVe:Global Vectors for Word Representation
无监督模型,与语境无关
3、2018年3月,ELMo模型,AllenNLP/NAACL
ELMo:embedding from language model
与语境有关
参考信息:
2018年,AllenNLP的Matthew E. Peters等人在论文《Deep contextualized word representations》中首次提出了ELMo模型
论文地址:https://www.aclweb.org/anthology/N18-1202/
这篇论文来自华盛顿大学的工作,该论文同时被ICLR和NAACL接受,最后是发表在NAACL会议上,并获得了最佳论文。
4、2018年,Flair,Zalando Research团队
Flair是由Zalando Research开发的一个简单的自然语言处理(NLP)库。 Flair的框架直接构建在PyTorch上

Flair简介
Flair的GitHub主页:https://github.com/flairNLP/flair
5、2018年6月11日,GPT,openAI
GPT:Generative Pre-Training,生成式预训练
论文:Improving Language Understanding by Generative Pre-Training,地址https://openai.com/blog/language-unsupervised/
包含1.17亿个参数
6、2018年10月,Bert,Google
BERT :Bidirectional Encoder Representations from Transformers)
2018年的10月11日,Google AI的Jacob Devlin和他的合作者在arxiv上放上了他们的文章,名为《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
论文地址:https://arxiv.org/abs/1810.04805
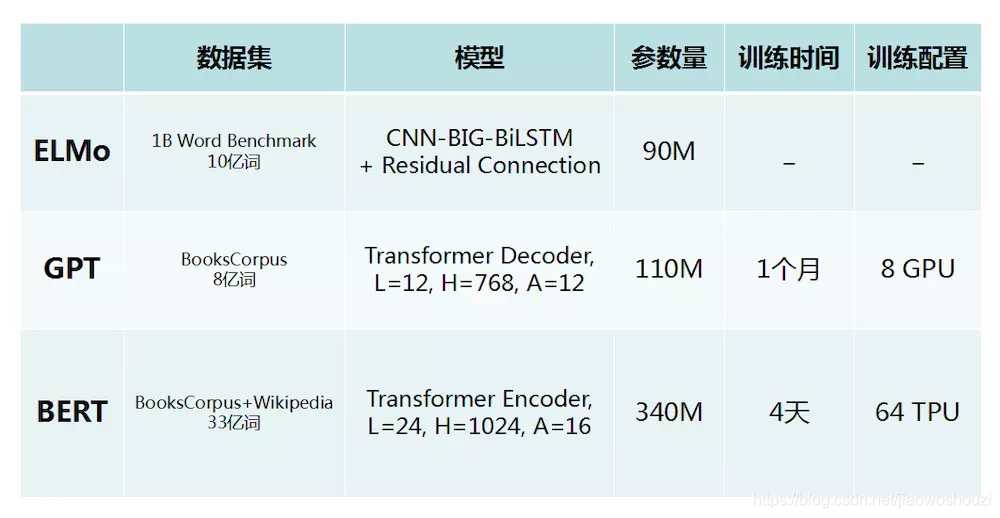
模型对比
7、2019年2月15日,GPT-2,openAI
包含15 亿参数
6、2020年5月28日,GPT-3,openAI
包含1750 亿参数量,是GPT-2的116倍
使用的最大数据集在处理前容量达到了 45TB
论文Language Models are Few-Shot Learners,地址:https://arxiv.org/abs/2005.14165
8,2020年,Switch Transformers,微软
论文Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,地址:https://arxiv.org/abs/2101.03961
包含16000亿参数,是GPT-3的9倍
















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











