







Clickhouse由俄罗斯yandex公司开发。专为在线数据分析而设计。Yandex是俄罗斯搜索引擎公司。官方提供的文档表名,ClickHouse 日处理记录数“十亿级”。
1.特性
- 采用列式存储。
- 向量化执行查询
- 数据压缩
- 基于磁盘的存储,大部分列式存储数据库为了追求速度,会将数据直接写入内存,按时内存的空间往往很小。
- CPU 利用率高,在计算时会使用机器上的所有 CPU 资源。
- 支持分片,并且同一个计算任务会在不同分片上并行执行,计算完成后会将结果汇总。
- 支持SQL,SQL 几乎成了大数据的标准工具,使用门槛较低。
- 支持联表查询。
- 支持实时更新。
- 自动多副本同步。
- 支持索引。
- 分布式存储查询
2.性能
根据官方提供的数据,性能表现大致如下:
- 低延迟:对于数据量(几千行,列不是很多)不是很大的短查询,如果数据已经被载入缓存,且使用主键,延迟在50MS左右。
- 并发量:虽然 ClickHouse 是一种在线分析型数据库,也可支持一定的并发。当单个查询比较短时,官方建议 100 Queries / second。
- 写入速度:在使用 MergeTree 引擎的情况下,写入速度大概是 50 - 200 M / s,如果按照 1 K 一条记录来算,大约每秒可写入 50000 ~ 200000 条记录每秒。如果每条记录比较小的话写入速度会更快。
3.引擎
Clickhouse 提供了丰富的存储引擎,存储引擎的类型决定了数据如何存放、如何做备份、如何被检索、是否使用索引。不同的存储引擎在数据写入/检索方面做平衡,以满足不同业务需求。
Clickhouse 提供了十多种引擎,两种最重要的引擎:MergeTree,Distributed。
MergeTree 是 ClickHouse 中最先进的引擎,并由 MergeTree 衍生出了一系列的引擎,统称 MergeTree 系引擎。
特性
- 支持主键索和日期索引。
- 可以提供实时的数据更新。
- MergeTree 是 ClickHouse 数据库提供的最理想的引擎。MergeTree 类型的表必须有一个 Date 类型列。因为默认情况下数据是按时间进行分区存放的。
分区
- MergeTree 默认分区是以月为单位,同一个月的数据永远都不会被合并。
- 同一个分区的数据会被切割到不同的文件夹中。
- 当有新数据写入时,数据会被写入新的文件夹中,后台会有线程定时对这些文件夹进行合并。
- 每个文件夹中包含当前文件夹范围内的数据,数据按照主码排序,并且每个文件夹中有一个针对该文件夹中数据的索引文件。
分区新特性:
- 在老版本的ClickHouse 中只支持按月分区。
- 在 1.1.54310 版之后,支持用户自定义分区。 可以通过 system.parts表查看表的分区情况。
索引
- 每个数据分区的子文件夹都有一个独立索引。
- 当 where 子句中在索引列及 Date列上做了“等于、不等于、>=、<=、>、<、IN、bool 判断”操作,索引就会起作用。
- Like 操作不会使用索引如下面的 SQL将不会用到索引。
- SELECT count()FROM table WHERE CounterID = 34 OR URL LIKE’%upyachka%'。
- 对于日期索引,查询仅仅在包含这些数据的分区上执行。
- 查询时最好指定主键,因为在一个子分区中,数据按照主码存储。所以,当定位到某天的数据文件夹时,如果这一天数据量很大,查询不带主键就会导致大量的数据扫描。
- Distributed 引擎并不存储真实数据,而是来做分布式写入和查询,与其他引擎配合使用。 比如:Distributed + MergeTree。 DIstributed引擎中会存储DIstributed表,类似物化视图和federated表,只会存储表结构不会存储实际的数据。
4.底层文件存储
column_name.mrk:每个列都有一个mrk文件
column_name.bin:每个列都有一个bin文件,里边存储了压缩后的真实数据
primary.idx:主键文件,存储了主键值
主键自身是”稀疏的”。它不定位到每个行 ,但是仅是一些数据范围。 对于每个N-th行, 一个单独的primary.idx 文件有主键的值, N 被称为 index_granularity(通常情况下, N = 8192). 每8192⾏行行,抽取一行数据形成稀疏索引.每一部分按照主键顺序存储数据 (数据通过主键 tuple 来排序). 所有的表的列都在各自的column.bin文件中保存.mrk是针对每个列的,对每个列来说,都有一个mrk,记录的这个列的偏移量。
5. 不足之处
- 没有完整的事务支持
- 缺少少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据
- 标准SQL的更新、删除操作是同步的,即客户端要等服务端反回执行结果(通常是int值);而Clickhouse的update、delete是通过异步方式实现的,当执行update语句时,服务端立即反回,但是实际上此时数据还没变,而是排队等着。
6.使用案例
TIDB的HTAP【HTAP=OLTP+OLAP】
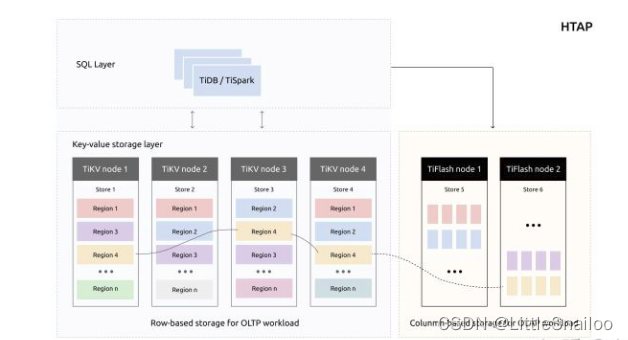
1)采用raft协议进行列存和行存数据的同步
2)采用新的列存引擎Delta tree
3)支持事务和mvcc















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









