







hadoop版本:2.7.7
配置
进入hadoop-2.7.7/etc/hadoop文件夹修改hadoop-env.sh文件、core-site.xml文件、hdfs-site.xml文件、mapred-site.xml文件(原本是一个临时文件需要复制一份)、yarn-site.xml文件
// hadoop-env.sh
//修改jdk的位置和pid文件的位置
export JAVA_HOME=/usr/local/jdk1.8.0_201
export HADOOP_PID_DIR=/home/hadoop_files
<!-- core-site.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定hdfs 的nameservices 名称为mycluster,与hdfs-site.xml 的HA 配置相同 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1:9000</value>
</property>
<!-- 指定缓存文件存储的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_files/hadoop_tmp/hadoop/data/tmp</value>
</property>
<!-- 配置hdfs 文件被永久删除前保留的时间(单位:分钟),默认值为0表明垃圾回收站功能关闭-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!-- 指定zookeeper地址,配置HA时需要 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>cluster1:2181,cluster2:2181,cluster3:2181</value>
</property>
</configuration>
<!-- hdfs-site.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop_files/hadoop_data/hadoop/namenode</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop_files/hadoop_data/hadoop/datanode</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>cluster1:50090</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
<!--mapred-site.xml-->
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce计算框架使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定MapReduce计算框架使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定jobhistory server的http地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cluster1:19888</value>
</property>
</configuration>
<!--yarn-site.xml-->
<?xml version="1.0"?>
<!-- Site specific YARN configuration properties -->
<!-- NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置Web Application Proxy 安全代理(防止yarn 被攻击) -->
<property>
<name>yarn.web-proxy.address</name>
<value>cluster2:8888</value>
</property>
<!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志删除时间为7天,-1为禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 修改日志目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/home/hadoop_files/hadoop_logs/yarn</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cluster1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>cluster1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>cluster1:8031</value>
</property>
</configuration>
修改slaves文件
vi slaves
删除“localhost”并添加下列信息
cluster1
cluster2
cluster3
创建配置文件中涉及的目录(在所有节点上),并修改文件权限
[root@cluster1 local]# mkdir -p /home/hadoop_files/hadoop_data/hadoop/namenode
[root@cluster1 local]# mkdir -p /home/hadoop_files/hadoop_data/hadoop/datanode
[root@cluster1 local]# mkdir -p /home/hadoop_files/hadoop_tmp/hadoop/data/tmp
[root@cluster1 local]# mkdir -p /home/hadoop_files/hadoop_logs/yarn
[root@cluster1 local]# chown -R hadoop:hadoop /home/hadoop_files/
[root@cluster1 local]# chown -R hadoop:hadoop /usr/local/hadoop-2.7.7/
将cluster1的hadoop目录分发到集群的其他节点
[root@cluster1 local]# scp -r /usr/local/hadoop-2.7.7/ cluster2:/usr/local/
[root@cluster1 local]# scp -r /usr/local/hadoop-2.7.7/ cluster3:/usr/local/
在其他节点上创建上述文件夹并修改权限
在所有节点上修改/etc/profile文件,添加hadoop的环境变量,完事后使用“source /etc/profile”命令使环境生效
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
格式化
1.首先启动集群的zookeeper服务,可以在从机上使用ntpdate cluster1命令(root权限)同步一下时间。
2.切换到hadoop用户,在每台机器上依次使用zkServer.sh start命令启动zookeeper服务。
3.在所有节点上启动journalnode,命令为hadoop-daemon.sh start journalnode,使用jps可以看到journalNode进程。
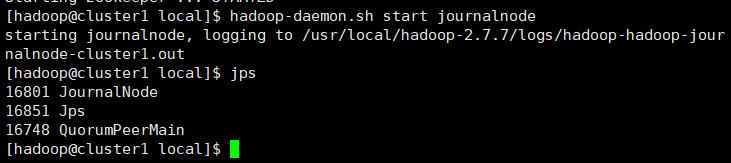
4.在cluster1上执行命令hdfs namenode -format格式化HDFS,注意只需要格式化一次,多次格式化会造成pid改变,到时候需要删掉相关目录文件,再重新格式化。
5.格式化完毕之后,一次关闭所有节点上的journalnode进程,命令为hadoop-daemon.sh stop journalnode.
HDFS启动和关闭
1.启动:在cluster1上执行start-dfs.sh,启动后使用jps命令可以在cluster1上看到Namenode、DataNode、SecondaryNameNode进程;在cluster2和cluster3上看到DataNode进程。

2.关闭:在cluster1上执行stop-dfs.sh
YARN启动和关闭
1.启动:yarn服务启动必须保证HDFS启动,在cluster1上执行start-yarn.sh。启动后使用jps命令可以在cluster1上看到NodeManager、ResourceManager进程,在cluster2和cluster3上看到NodeManager进程。

2.关闭:在cluster1上执行stop-yarn.sh
Web测试
1.启动HDFS后,在浏览器中访问172.31.42.166:50070,可以看到HDFS的web界面

点击Datanodes选项卡,可以看到集群中节点的情况。

2.启动YARN后,可以用浏览器访问172.31.42.166:8088,查看YARN的web界面

点击Nodes选项卡可以看到YARN的节点

命令行功能测试
1.在cluster1上的主目录新建一个测试文件
$ cd ~/
vi testfile
// 输入
hello
hadoop
// 保存退出
2.查看HDFS根目录的文件
$ hdfs dfs -ls /
// 此时为空
3.在HDFS 的根目录创建test目录,并查看是否创建成功
$ hdfs dfs -mkdir /test

4.上传testfile文件到HDFS的根目录下的test目录中
$ hdfs dfs -put testfile /test
5.在cluster2上查看HDFS的根目录和文件
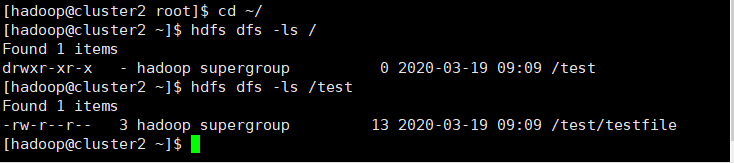
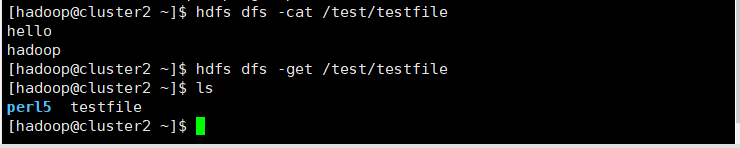
6.在cluster2上将HDFS中的文件下载到本地















 5083
5083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









