







文章内容
- 框架介绍
- 搭建环境
2.1-2.10 基本设置
2.11 本地运行模式
2.12 伪分布式模式
2.13 完全分布式运行模式
1.框架介绍
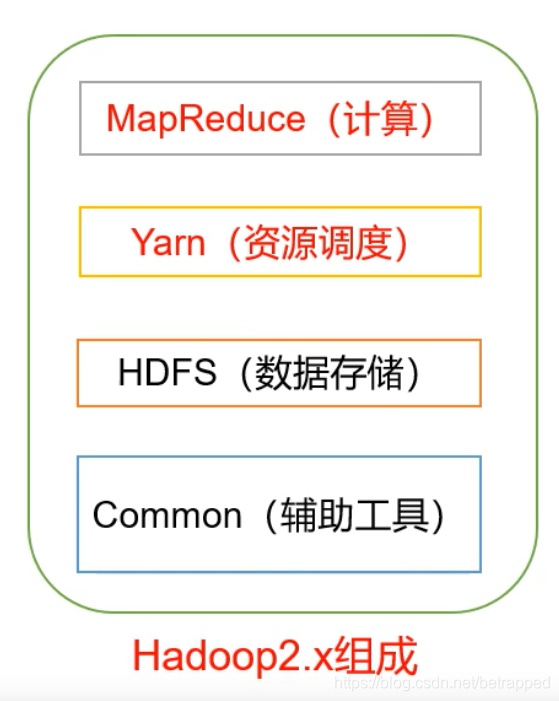
1.1 HDFS
- NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性,以及每个文件的块列表和块所在的DataNode等。等于就是一个目录,
- DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode:用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS远数据的快照。类似于NameNode的副本。
1.2 YARN框架
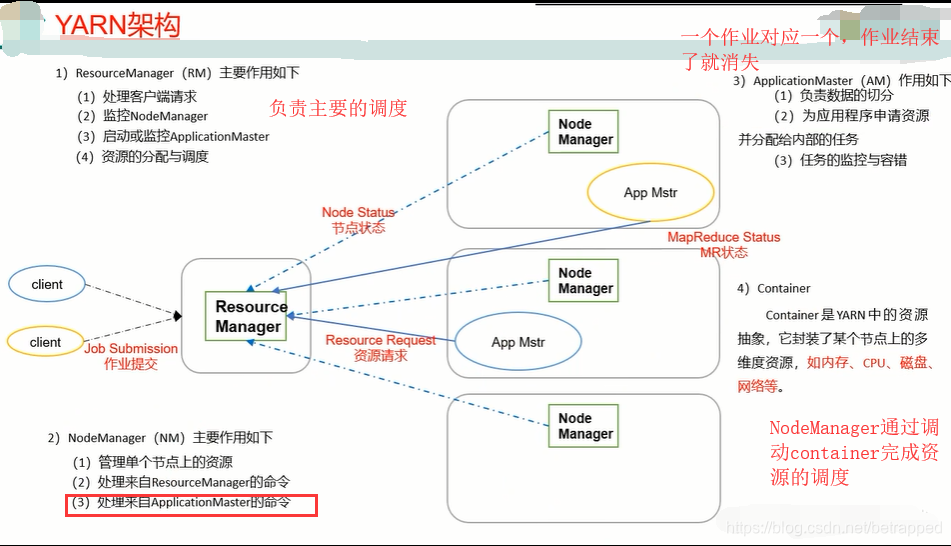
ApplicationMaster和Container是非常驻的,有任务才出现,没任务就消失。而NM和RM都是常驻的。
1.3 MapReduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
大数据的技术生态系统
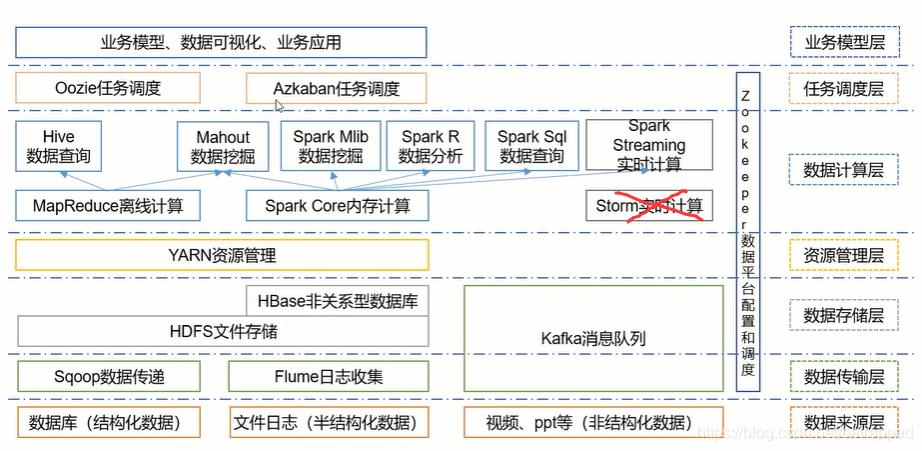
2.搭建环境
2.1 关闭防火墙
systemctl stop firewalld.service #关闭
systemctl disable firewalld.service #禁止开机自启
2.2 创建一个新用户并设置密码
useradd us
passwd us
2.3 在opt文件下创建两个文件夹module和software,并且修改他们的权限
mkdir /opt/software /opt/module #创建文件夹
chown us:us /opt/software /opt/module #修改使用权限
2.4 把创建的的用户增加到sudoers
vim /etc/sudoers
在root的下一行输入
us ALL=(ALL) NOPASSWD:ALL
:wq! #强制保存

下面测试一下是否设置成功
su us #切换到新用户
sudo ls #不报错即为成功
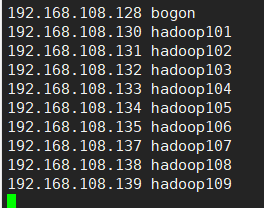
2.5 修改host
vim /etc/hosts
增加下面的内容(根据自己的ip)
2.6 改静态ip
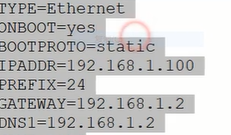
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改以下几项(根据自己的ip和网卡)
2.7 修改主机名
hostnamectl set-hostname xxx #修改主机名为XXX
hostnamectl #查看主机名
重启
2.8 克隆虚拟机
从快照从克隆
然后从修改静态ip开始重新设置一遍(每次克隆一个新的虚拟机都要从这里开始进行配置)
按照上面host的修改来进行配对
注意设置的时候命令前加上sudo
2.9 修改网卡脚本文件(这步不做也不影响)
2.10 下载安装java和Hadoop
java jdk下载
Hadoop
下载后使用XFTP或者什么方式传到LInux的/opt/software文件夹中去
先查看一下虚拟机中是否有安装java,如果有就卸载:
rpm -qa |grep java | xargs sudo rpm -e --nodeps
解压
tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/module
tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/
在module下面可以看到这两个就说明安装成功了

接下来配置Java的环境变量
sudo vim /etc/profile
在末尾输入:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_221 #export代表设置为全局变量
export PATH=$PATH:$JAVA_HOME/bin
:wq
source /etc/profile
查看是否写入成功:
echo $JAVA_HOME #出现jdk的地址说明成功
查看java是否配置完成:
java -version
配置Hadoop的环境变量
一致的流程
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
查看是否配置成功:
hadoop version #注意没有-
hadoop的jar包都存在hadoop的share文件夹下面
lib中有native文件夹,存放本地库,所以hadoop需要编译
注:下面的本地运行模式(2.11)和伪分布式模式(2.12)在实际开发中是没什么用的的,写上只为了学习和练手,可直接看2.13完全分布式运行模式
2.11 本地运行模式
即资源存储和资源调度都在本地运行,基本是用于测试debug
cd /opt/module/hadoop-2.7.7/
vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_221 #具体位置如下图

测试一下
bin/hadoop
设置本地模式
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output 'dfs[a-z.]+' #执行准备好的范例程序,输出文件夹要是一个不存在的文件夹
$ cat output/* #查看结果
出现下图就说明,本地环境已经被打通了

一个wordcount案例
mkdir wcinput
cd wcinput
vim wc.input
#随便写入一些单词
cd../
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput wcoutput
cat wcoutput/* #查看结果

2.12 伪分布式
只有一个节点的分布式,实际开发中也没有什么用
配置HDFS
vim etc/hadoop/core-site.xml
<configuration>
#指定HDFS中的NameNode地址
<property>
<name>fs.defaultFS</name> #修改默认的filesystem,原本是本地系统
<value>hdfs://hadoop101:9000</value>
</property>
#指定hadoop运行时产生文件的存储目录
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.7/data/tmp</value>
</property>
</configuration>
vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> #指定hdfs副本的数量为1,单一节点至多存储一个副本
</property>
</configuration>
#第一次需要初始化,后面就不需要了
bin/hdfs namenode -format

看到这句话说明格式化成功
启动
hadoop-daemon.sh start namenode #停止就把start改成stop
hadoop-daemon.sh start datanode
jps #查看
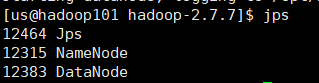
基本上就算成功了,可以到hadoop101:50070查看一下
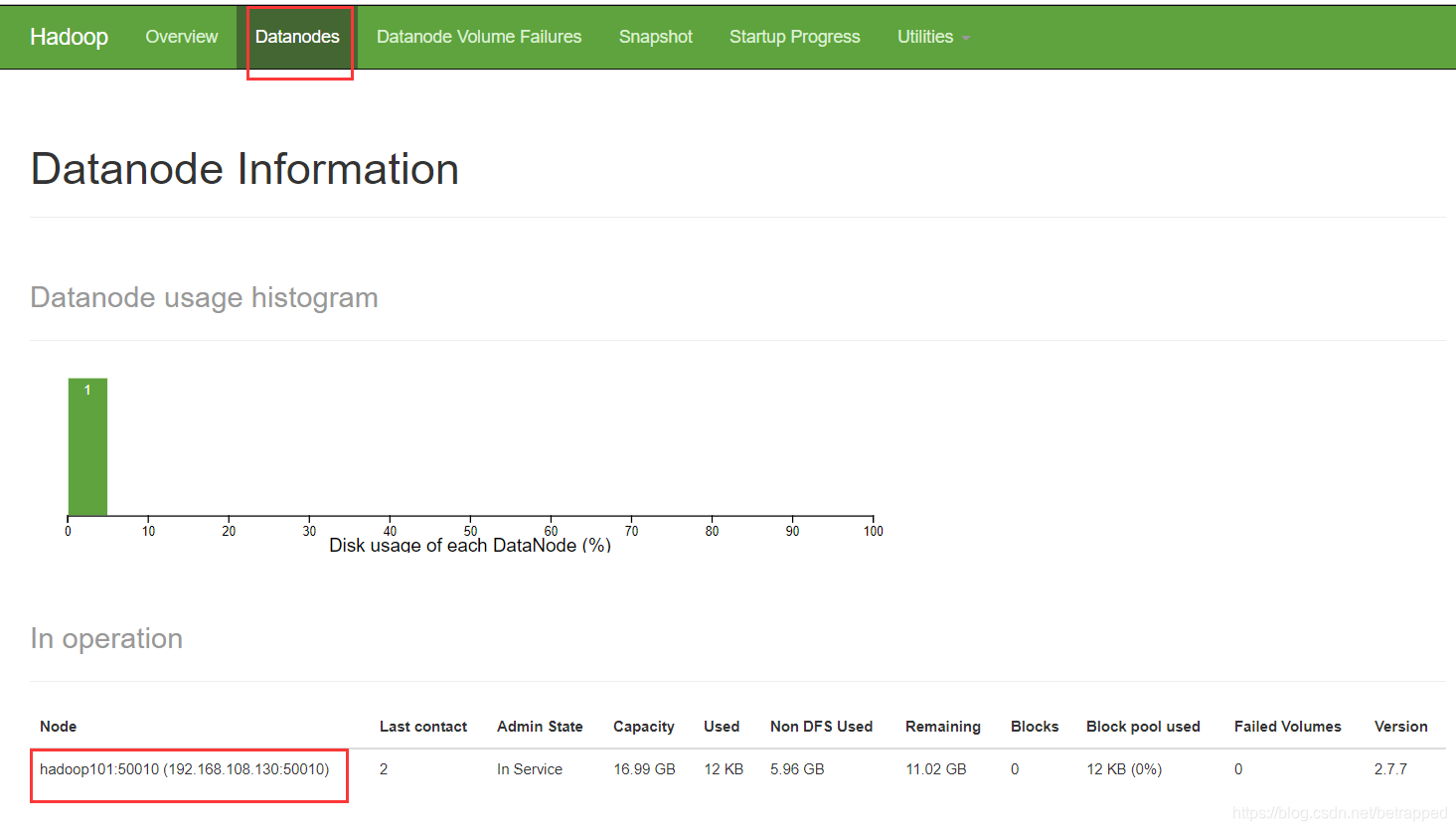
9000是hadoopIPC端口,50070才是一个http端口
如果反复格式化,就会导致datanode消失。因为datanode会记录上一个namenode所代表的clusterID,而新格式化后的nameNode会有一个新的代表的clusterID,所以DataNode就无法匹配,就自我shutdown了。
解决,把data数据删掉就可:
cd data/tmp/dfs/
rm data/ -rf
然后再重新启动一下DataNode就可以了。
配置yarn
vim etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_221 #具体位置如下图

vim etc/hadoop/yarn-site.xml
#增加下面代码
<configuration>
#Reducer获取数据方式
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
#指定Yarn的ResourceManager的地址
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
</configuration>
vim etc/hadoop/mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_221
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml #重命名一下
vim etc/hadoop/mapred-site.xml
#指定MR运行在yarn上,也就是切换默认的资源调度器
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
启动
$ yarn-daemon.sh start resourcemanager
$ yarn-daemon.sh start nodemanager
$ jps
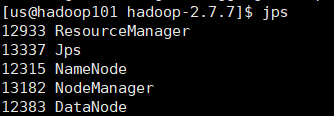
可以在网页上查看hadoop101:8088
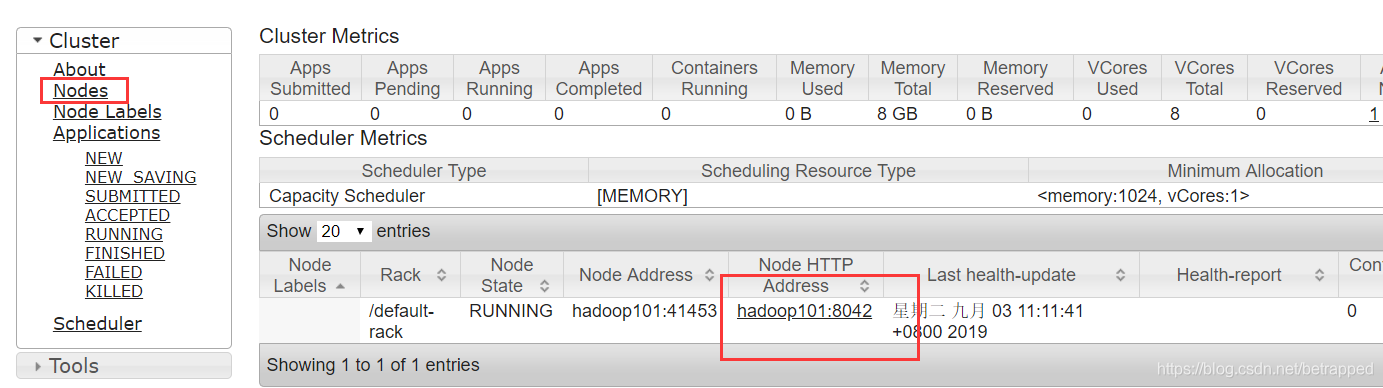
到此hdfs和yarn就配置好了,测试一下单节点的伪分布式
$ hadoop fs -put wcinput / #把本地文件上传到根目录上面
可以通过hadoop101:50070中的utilities查看是否上传成功

#和本地测试的时候基本是一样的,因为上面已经修改了默认的文件系统为hdfs,所以的文件已经都是hdfs
中的根目录下的指定文件了
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /wcinput /wcoutput

可以直接点进去把结果下载下来查看,也可以从下面这查看
#查看一下结果,和之前本地运行的结果是一样的
$ hadoop fs -cat /wcoutput/*

2.13 完全分布式运行模式(*)
第一部分:搭建虚拟机的环境
- 准备三台虚拟机(按2.6和2.7配置好静态ip和主机名)
- 使用远程传递的方式把hadoop101安装好的软件复制到其他三台虚拟机中
- scp(安全远程拷贝)
$ scp -r hadoop101:/opt/module/hadoop-2.7.7 hadoop102:/opt/module #把hadoop101中:/opt/module/hadoop-2.7.7文件夹下的内容复制到hadoop102
- rsync:比scp要好一点
-av(-a 归档拷贝(完全一样的拷贝,包括文件的权限和时间戳都复制过来) -v 显示复制的过程)
源和目的目录不能同时为远程端
$ rsync -av hadoop101:/opt/module/hadoop-2.7.7 /opt/module #需要在hadoop102上执行
rsync只拷贝不一样的地方,所以一般使用这个方法
为了方便发送,封装一个使用rsync发送到各个集群的脚本
$ cd ~ #回到根目录
$ vim xsync #新建脚本
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
# 2 获取文件名称
p1=$1
fname=$(basename $p1) #得到目录的最后一级的文件名
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=$(cd -P $(dirname $p1); pwd) #cd -P追踪绝对路径,可以追踪软链接到真实的目录,还可以避免得到.(即当前目录 )
echo pdir=$pdir
#4 获取当前用户名称
user=$(whoami)
#5 循环
for((host=102;host<105;host++)); do
echo -------------------hadoop$host------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
$ ./xsync xsync #尝试一下把该脚本分发到新建的三台虚拟机
$ sudo cp xsync /bin #为了方便执行,把这个脚本路径增加到环境变量里面(这是根目录的bin,这样sudo的时候才可以直接执行)
$ sudo xsync #查看一下配置成功与否
把该脚本分发到101的bin目录下面
$ sudo rsync -av /bin/xsync hadoop101:/bin
可以开始从hadoop101进行各种软件配置的分发了。
$ cd /opt/moudel
$ xsync hadoop-2.7.7 #分发hadoop
$ xsync jdk1.8.0_221 #分发java
$ sudo xsync /etc/profile #分发配置文件,因为etc是的权限是属于root的,所以需要使用sudo
$ source /etc/profile #每个虚拟机上都需要执行这句话
$ java -version #查看一下是否分发成功
$ hadoop version
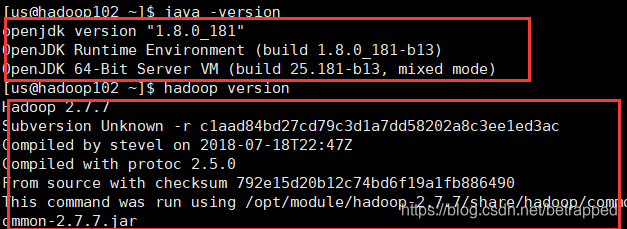
tips:一次性对所有窗口执行同一个语句可以使用撰写栏
第二部分:集群配置
- 集群规划
一个集群最小的配置:6台
1:NN(hdfs主机)
2:2NN(hdfs从机)
3:RM(yarn主机)
因为NM是管理进程和CPU的,所以和DN在一起
4:DN+NM(hdfs从机)(yarn从机)
5:DN+NM(hdfs从机)(yarn从机)
6:DN+NM(hdfs从机)(yarn从机)
but,因为学习过程,电脑撑不起六台虚拟机,所以(1+4=hadoop102;3+5=hadoop103;2+6=hadoop104)这样混搭,只使用3台虚拟机就可。如下图:

2. 集群配置
tips:可以使用notepad++中的插件NPPFTP来修改,操作起来比较方便
可以在插件管理里面直接下载
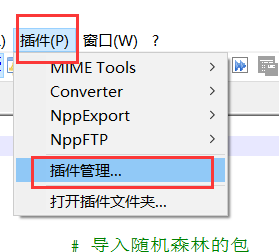
下载完成后,点击下图的小齿轮->profile setting
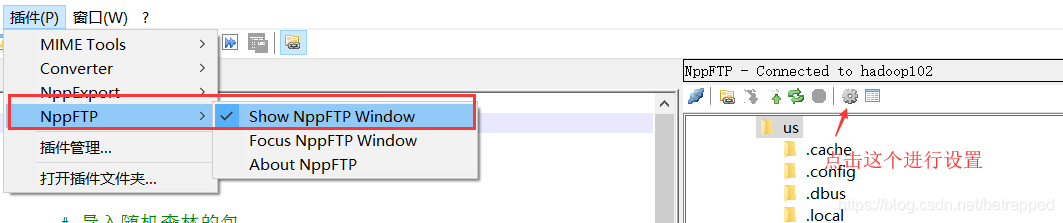

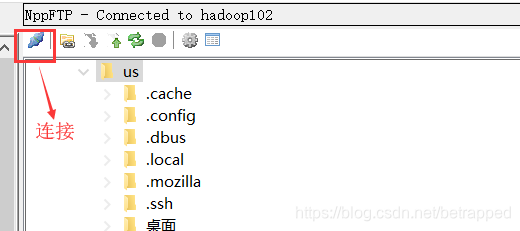
修改.sh配置文件
如果没有经过伪分布式和本地模式步骤的,需要填写下面三个配置文件的JAVA_HOME,具体填写的位置和内容可以查看上面2.11的第一张图
$ vim hadoop-env.sh
$ vim mapred-env.sh
$ vim yarn-env.sh
修改.xml配置文件
需要修改下面的xml文件(具体的代码、注释和位置可以网上翻到2.12查看)
配置 core-site.xml
$ sudo vim core-site.xml #hadoop102作为hdfs的主机,放NameNode
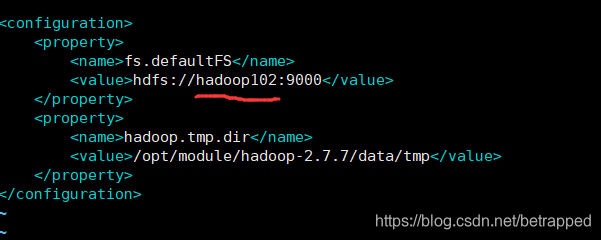
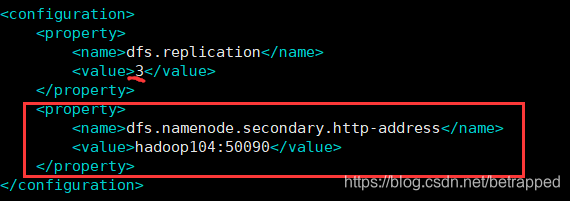
配置hdfs-site.xml
$ sudo vim hdfs-site.xml
<configuration>
#指定hdfs副本数量,这里要修改成3
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
#指定hadoop辅助名称节点的主机配置,前面说把2NN放在hadoop104
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
</configuration>
mapred-site.xml(在2.12的基础上不需要修改)
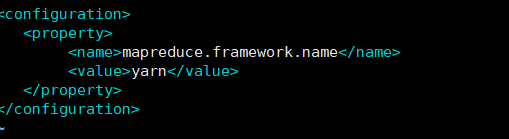
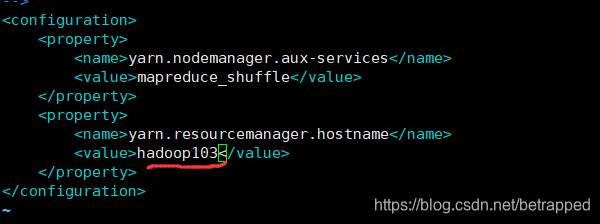
配置yarn-site.xml
$ sudo vim yarn-site.xml #hadoop103作为yarn的主机
第三部分:启动集群
这样配置之后,就配置了NameNode、ResourceManager、SecondaryNameNode
但是DateNode+NodeManager没有一台配置了
如果手动启动集群,那么不需要配置的
先把刚刚配置好的文件发到其他三台虚拟机上
一:手动启动
$ cd /opt/module/hadoop-2.7.7/
$ xsync etc
格式化集群
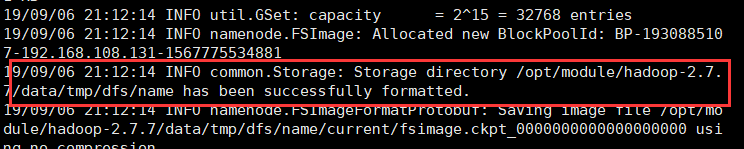
$ hdfs namenode -format
出现下面这段话说明成功
这中间可能会出现问题
Wrong 1.
这个问题需要把图中报错的地址中data文件夹下的所有文件删掉(也就是tmp文件夹)
$ cd /opt/module/hadoop-2.7.7/data/
$ sudo rm -rf tmp/
Wrong 2.
这个是因为没有权限去新建文件夹,并且hdfs命令前不能加sudo,所以只能修改data文件夹的权限
$ sudo chmod -R a+w data/
再次执行初始化就可以成功了。
启动Namenode和DataNode
$ hadoop-daemon.sh start namenode #hadoop102执行
$ hadoop-daemon.sh start datanode #hadoop102、hadoop103、hadoop104执行
$ hadoop-daemon.sh start secondarynamenode #hadoop104要记得额外启动一下2NN
如果执行了之后DataNode还是不出现,就删掉data文件里的内容再执行一次就好。(出错就看看logs文件夹查看错误内容)
看一下每台虚拟机上的配置
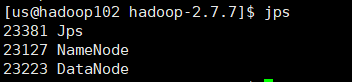

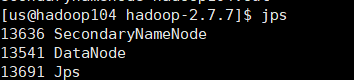
这样的配置和上面的集群规划一致。DataNode出现三个虚拟机的名称说明成功。

二:SSH无密登录
简单讲一下SSH远程登录的流程:
1.首先,本地向远程主机发送一个登录请求
2.主机收到了后,就会给本地发送一个密钥,用来加密数据流。
3.本地收到密钥后,把密码加密后发送给主机
4.主机收到后,用配对的密钥进行解密,跟认证信息比对一下
在登录的过程中,会弹出一段指令让你选择yes/no。这就让你人工确认一下你要发送密码的主机ip是不是当前显示的,如果不是,就可能存在被中间攻击的风险。
那么免密登录的原理就是,提前准备一对密钥,本地先把一个密钥(公钥)发送给主机,下次直接就把数据通过密钥发送给主机,主机如果有可以解密的密钥,就说明这段连接是ok的,就不要密码传来传去登录了。
实践一下:
先来一种铁憨憨改法,很憨但是可以理解一下上述说的过程。
$ ssh-keygen -t rsa #生成公钥,加密算法是rsa
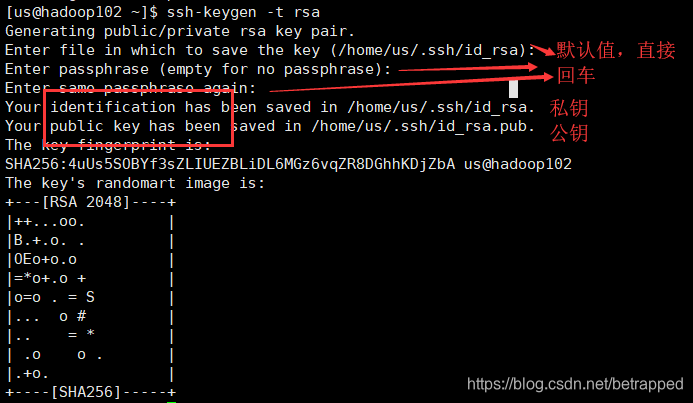
把密钥传给hadoop103
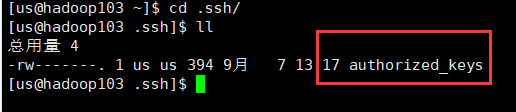
$ ssh-copy-id hadoop103 #这个文件会传到hadoop103的.ssh文件夹下
authorized_keys这个文件里面就存着所有可以免密登录hadoop103的用户,这个文件也是就是前面公钥的文件,改了名字而已。
$ ssh hadoop103 #现在不需要登录就可以连接

但是现在连接是单向的,如果要双向连接,在103上重复上面的内容即可。
这样配置就可以完成两台虚拟机之间的免密登录,但是自己连自己还是需要密码,所以需要在hadoop102上$ ssh-copy-id hadoop102这个指令,来完成自己连接自己的免密登录。其他虚拟机也同理。
上述就是铁憨憨改法,很慢。
这里不建议直接写一个修改这个的脚本,因为把密码写到脚本里很不安全。
不铁憨憨的改法(快,但是安全性降低了):
#地址定位:[us@hadoop102 .ssh]
$ rm authorized_keys #先把前面传送来的文件删除,删除后就无主机可以免密登hadoop102
$ ssh-copy-id hadoop102 #设置自己连接自己的免密登录
$ cd ..
$ xsync .ssh
三:群起脚本
#地址定位:[us@hadoop102 ~]
$ cd /opt/module/hadoop-2.7.7/etc/hadoop/
$ vim slaves #把文件里的内容修改成下图:
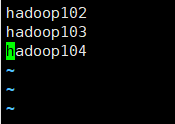
修改完配置文件记得要同步
#地址定位:[us@hadoop102 hadoop-2.7.7]
$ xsync etc
$ start-dfs.sh #这样就可以完成群起集群了
$ jps #可以在每个虚拟机上查看一下,结果应该和前面手动启动的结果是一样的
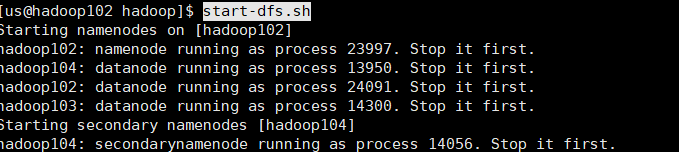
启动yarn,yarn的启动一定要在hadoop103上启动,因为resourcemanager配置在hadoop103上面。
#地址定位:[us@hadoop103 ~]
$ start-yarn.sh
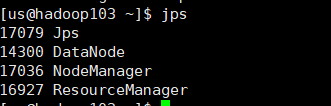
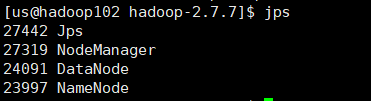
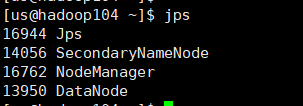
配置成这样就基本完成了,可以去网页上查看一下,如果每个虚拟机都对应三台节点说明ok了。
- hadoop102:50070
- hadoop103:8088
测试 一下
依旧是它
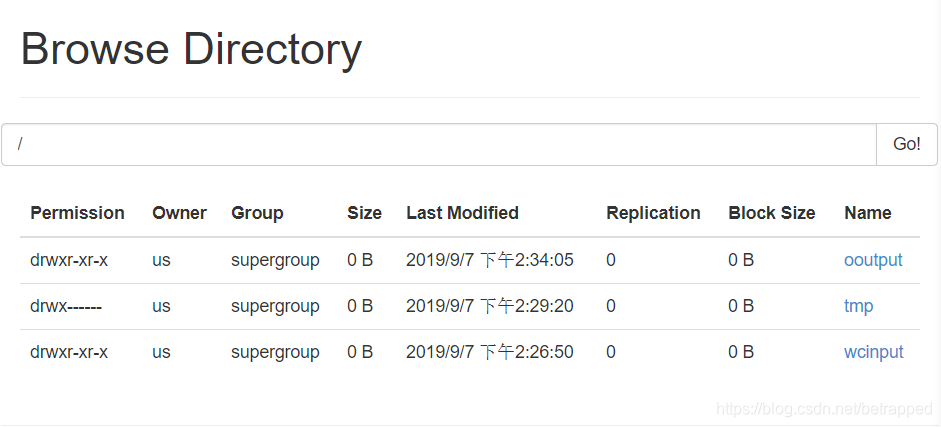
$ hadoop fs -put wcinput /
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /wcinput /ooutput
没报错就完事了
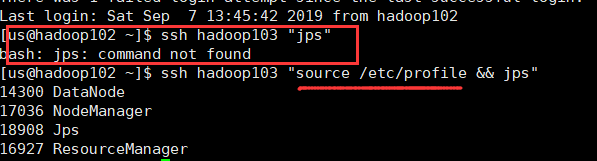
无密登录时会遇到下面这样的问题及解决方案:
下面的两部分都不是必要的
第四部分:历史服务器、日记聚集的配置
#位置定位:/opt/module/hadoop-2.7.7/etc/hadoop
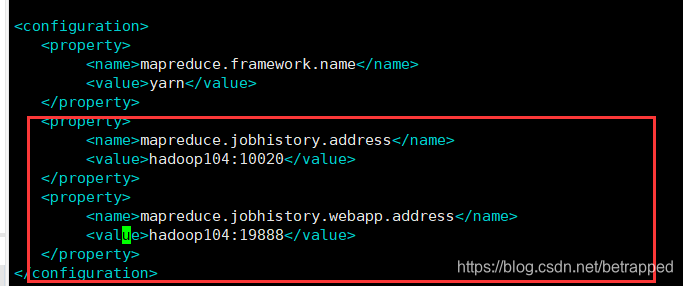
$ vim mapred-site.xml
#写入下面的内容
#历史服务器端地址
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop104:10020</value>
</property>
#历史服务器web端地址
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop104:19888</value>
</property>
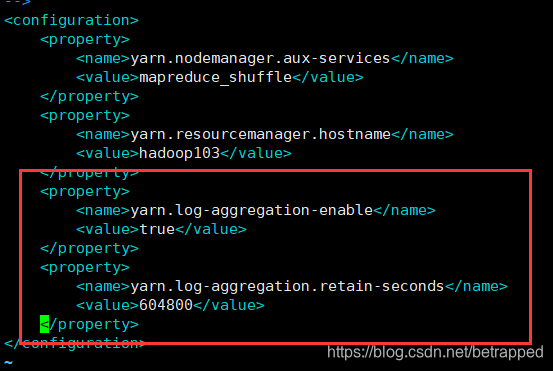
日志聚集功能
#位置定位:/opt/module/hadoop-2.7.7/etc/hadoop
$ vim yarn-site.xml
#开启日记聚集功能
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
#日志保存的天数,604800s=7天
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
记得同步
$ xsync etc/
开启集群
$ start-dfs.sh #在hadoop102开启hdfs
$ start-yarn.sh #在hadoop103开启yarn
$ mr-jobhistory-daemon.sh start historyserver #在hadoop104开启历史服务器
测试一下,依旧是它:
目录定位:[us@hadoop102 hadoop-2.7.7]
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /wcinput /oooutput
在网站上查看:hadoop103:8088
如下点击history可以查看历史信息

会跳转到这个页面,点击logs可以查看日志信息
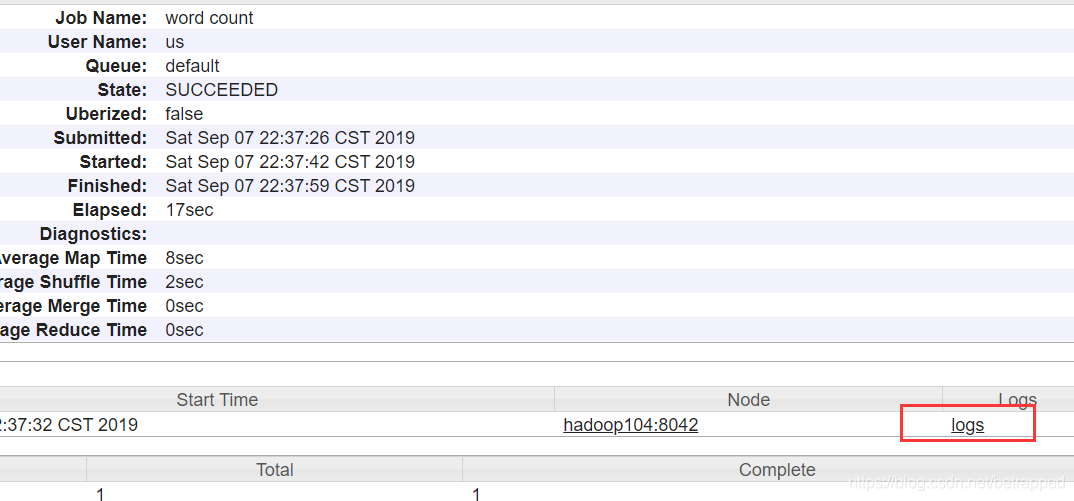
到这里呢,集群的搭建就算是基本完成了!
第五部分:集群时间同步
这是本文的最后一部分,不属于集群搭建的部分。具体的做法是:找一台机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如每个十分种、半小时同步一次时间。
hadoop对时间同步的要求比较低(所以这里不配也ok),两星期的差距也不会影响它的启动,但是HBASE对时间同步的要求就很高了。
配置的步骤:
- 选择一台机器作为时间同步的主机(我选择hadoop102),切换到root用户的模式下:
$ su - #切换到root模式
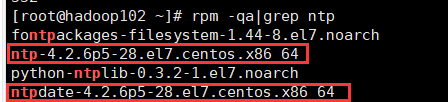
# rpm -qa |grep ntp #查看是否安装了ntp
看是否存在这两个
# service ntpd status #查看ntp的运行情况,每台都需要查看一下
# service ntpd stop #如果正在运行就需要把每台机器上的服务停掉

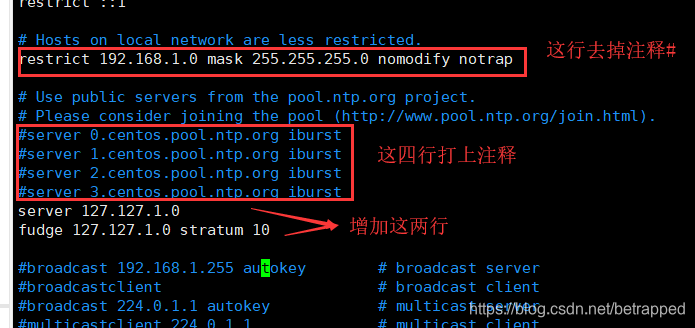
# vim /etc/ntp.conf #把该文件修改成下面图片的样子
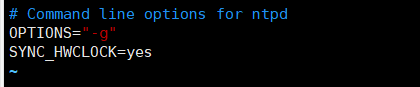
# vim /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes #增加这行,同步硬件时钟
# service ntpd start #重启服务
# chkconfig ntpd on #开机启动
hadoop102的配置到这里就结束了,现在去配置hadoop103和hadoop104
# crontab -e #也是要在root用户下执行
*/10 * * * * /usr/sbin/ntpdate hadoop102 #十分钟更新一次的意思
出现这个说明成功

如需修改时间
# data -s “2019-9-9 15:57:55”
----------------------END














 1309
1309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









