







创建表
oracle 中创建表:
普通的直接创建表:定义表名,列名,列类型,约束。
创建表指定表存储组织方式:堆表(存在同一物理区域),索引表(一般只要建立主键,都会默认为索引表),外部表(创建指定的表从指定的目录下由数据库服务器读取对应的内容,如CSV文件的数据读取)
创建表时指定分区:有三种分区,按照范围(range,一般都是数值型数据来根据指定的范围来划分),按照列表(list,直接列举哪些内容为一个分区),按照哈希值(hash,此种情况直接指定需要创建多少个分区即可)。
创建全局或者私人的临时表:用于在一个事务中存储数据,只有创建表的人在增加数据的会话中能查看到并进行操作,事务结束数据如果未写入到永久表中,则数据将会丢失,可用作一些中间表,当然使用存储过程或匿名块都有游标来处理这种事情。
总结:不同形式的表创建,都是基于性能考虑或者用作分析考虑,还有一种获取数据从多个表的属于Oracle的表簇,即定义一个表簇,指定列,后续将其他表对应的列指定加入这个簇,相当于增加一个索引表,这样获取其他内容时,会快速一些。
SQL子查询
主要描述子查询语句,分为四种:
标量子查询,内联视图,嵌套子查询,可重用子查询。
标量子查询:子查询放置在select语句后面,如
select b.id,(select name from empo a where a.id = b.id) as name
from deptno b;
内联视图:
子查询放置在from后,如
select a.id
from (select id from hrmresources) a;
嵌套子查询(相关或者不相关,主要考虑子查询是否使用父表的值作为条件,是就相关,否就不相关),如
select a.deptid
from hrmresouces a
where a.name in (select b.name from department b where b. = a.deptid)
可重用子查询:可以在同一个事务中重复利用的子查询,如
with test as(select * from hrmresources)
,test1 as(select * from hrmdepartment)
select * from test;
聚合函数与分析函数
聚合函数:sum,averge,min,max,count(*)等,其结果只会输出一行。
分析函数:
over()—分析函数标志(结合聚合函数即可成为分析函数)
分析函数参数之排序,分组:
order by 字段名,字段名1:按照字段进行排序取值。
partition by 字段名,字段名2:
分析函数参数之窗口定义:
rows between 范围左边界 and 范围有边界:只计算当前行满足范围条件得值。
range between 范围左边界 and 范围有边界:所有满足此范围定义的当前行的值都会被计算。
范围定义:
当前行:current row
前n行:n preceding
后n行: n following
无限制:
左面范围无限制:unbounded preceding
右面范围无限制:following preceding
分析函数的窗口定义参数只限于结合order by使用时产生作用,可以使用默认窗口(定义:range between unbounded preceding and current row),或者自己定义滑动窗口(如rows between unbounded preceding and current row)
例子:
select b.*,
min ( colour ) over (
order by brick_id
rows BETWEEN 2 preceding AND 1 preceding
) first_colour_two_prev,
count (*) over (
order by weight
range BETWEEN CURRENT ROW AND 1 following
) count_values_this_and_next
from bricks b
order by weight;
解读:
第一个分析函数:
min ( colour ) over (
order by brick_id
rows BETWEEN 2 preceding AND 1 preceding
) first_colour_two_prev,
根据brick_id来进行排序,找到范围在当前值之前的前两行与前一行之间满足条件的行,然后取出他对应的colour的值。(如果有重复值,应该去重,然后根据排序的值找出对应的范围)
第二个分析函数:
count (*) over (
order by weight
range BETWEEN CURRENT ROW AND 1 following
) count_values_this_and_next
根据weight排序(备注:
因为此列存在重复值,而排序时默认忽略重复值来构造范围,例如列值为1,1,1,2,2,3(排序时是1,2,3),假设在当前行及后一行且当前行的值为1,是指这个字段的值在大于等于1并且小于等于2,而不是大于等于1并且小于等于1
),然后进行行数的计算。
整体理解:第一个分析函数找出范围在前两行与前一行范围之间的满足聚合函数的值然后将其赋值给当前行的值。
第二个分析函数找出范围在找出范围在当前行及后一行范围之间的满足聚合函数的值然后将其赋值给当前行。
结果:
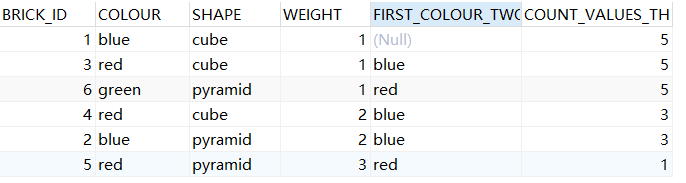
重点理解窗口条件的内容:
根据当前行判断当前行的值来源于哪个范围,这个范围由窗口定义结合排序函数来决定(其取范围的值是排序后逻辑性的去掉重复值的排序,避免直接给定无意义的范围),决定范围后将其聚合后的值赋值给当前行对应列的值。
分析函数之过滤:
分组函数可以搭配having过滤,而分析函数没有相应的设计,其次不能用在where后面进行判断,因为where进行判断时,还未存在相应的值,因为放置在select后面,除了order by是在其后执行,他都在其他后面执行,因此,分析函数过滤,需要放置在子查询当(内联视图,可重用子查询皆可)中,从外层过滤。
如:
with totals as (
select b.*,
sum ( weight ) over (
ORDER BY shape
RANGE BETWEEN CURRENT ROW AND CURRENT ROW
) weight_per_shape,
sum ( weight ) over (
ORDER BY brick_id
) running_weight_by_id
from bricks b
)
select * from totals
where weight_per_shape = 6 AND running_weight_by_id > 3
order by brick_id;
备注:上图使用的子查询是可重用子查询。
以下是常见分析函数的概述
行编号
rank、dense_rank 和 row_number :
区别:
rank:遇到相同值排序相同,后续的值取在排序集中所占的位置。
dense_rank:遇到相同的值排序相同,后续的值依次接着顺序排序。
row_number:无论值是否相同,按顺序直接依次排序。
如一下代码的排序:
select brick_id, weight,
row_number() over ( order by weight ) rn,
rank() over ( order by weight ) rk,
dense_rank() over ( order by weight ) dr
from bricks;
排序结果:

上一个和下一个值
滞后(Lag )和领先(lead)使您能够从结果中向后和向前的行中获取值。
select b.*,
lag ( shape ) over ( order by brick_id ) prev_shape,
lead ( shape ) over ( order by brick_id ) next_shape
from bricks b;
第一个和最后一个值
您可以使用 first_value 和 last_value 获取有序集合中的第一个或最后一个值:
select b.*,
first_value ( weight ) over (
order by brick_id
) first_weight_by_id,
last_value ( weight ) over (
order by brick_id
) last_weight_by_id
from bricks b;
注意 first_value 的结果保持不变。但是对于 last_value 它每行都会改变。这是因为默认窗口子句在当前行停止。要查找数据集中最后一行的值,请将窗口末尾更改为“无界跟随”。例如:
select b.*,
first_value ( weight ) over (
order by brick_id
) first_weight_by_id,
last_value ( weight ) over (
order by brick_id
range between current row and unbounded following
) last_weight_by_id
from bricks b;
分组函数
group by 字段名,字段名2等
但是有时为了限制分组或者相当于列举为
group by (字段名1),(字段名1,字段名2)这样的限制分组,可以使用特定的函数来完成。
如: cube ,rollup等,具体可参照网络资源。
其与分析函数的不同就是,不能输出额外的列,例如除了进行分组的,其余的只能进行聚合,而不参与其中一种的,不能输出,但等效的分析函数,可以输出其他列。
dbms使用总结
dbms使用可以分为以下几种类型来构成:
select操作步骤:
一般步骤:
open_cursor >> parse(先解析后续再定义列或者绑定变量) >> define column>>excute(尽量定义一个返回参数 ,因为会报错找不到这个过程或者函数) >> fetch_rows(对于定义的列或者绑定的变量,需要取出对应的值,如variable_value(),column_value())>>close cursor.
带条件的步骤:
open_cursor >> parse >> define column或者bind variable>>excute>> fetch_rows及column_value()>>close cursor.
对应承接select查询结果的变量(一般为单个记录)
open_cursor >> parse >> bind variable>>excute>> fetch_rows及variable_value()>>close cursor.
对于insert,update操作:
open_cursor >> parse >> bind variable>>excute>> close cursor.
对于delete操作:
open_cursor >> parse >> bind variable(根据删除是否需要条件决定)>>excute>> close cursor.
例子:
DECLARE
v_brick_id NUMBER;
v_cursor NUMBER;
v_colour VARCHAR2(6);
v_sql VARCHAR2(200);
v_num NUMBER;
v_condition char(4) := 'blue';
BEGIN
v_sql := 'SELECT * FROM bricks WHERE colour = :v_condition';
--打开游标
v_cursor := dbms_sql.open_cursor;
--解析sql
dbms_sql.parse(v_cursor,v_sql,dbms_sql.native);
--定义列
dbms_sql.define_column(v_cursor,1,v_brick_id);
dbms_sql.define_column(v_cursor,2,v_colour,6);
--绑定变量
dbms_sql.bind_variable(v_cursor,':v_condition',v_condition);
v_num := dbms_sql.execute(v_cursor);
LOOP
IF dbms_sql.fetch_rows(v_cursor) = 0 THEN
EXIT;
END IF;
dbms_sql.column_value(v_cursor,1,v_brick_id);
dbms_sql.column_value(v_cursor,2,v_colour);
dbms_output.put_line('brick_id:'|| v_brick_id || 'colour:' || v_colour);
END LOOP;
EXCEPTION
WHEN others THEN
dbms_output.put_line('异常出现');
dbms_sql.close_cursor(v_cursor);
END;
使用的是上述的“带条件的查询步骤”。
备注:原始动态SQL语句列举如下:
嵌入式 SQL 语句
嵌入式 SQL 语句将 DDL、DML 和事务控制语句合并到过程语言程序中。.
嵌入式语句与 Oracle 预编译器一起使用。嵌入式 SQL 是将 SQL 合并到过程语言应用程序中的一种方法。另一种方法是使用过程 API,例如开放式数据库连接 (ODBC) 或 Java 数据库连接 (JDBC)。
嵌入式 SQL 语句使您能够:
定义、分配和释放游标(DECLARE CURSOR、OPEN、CLOSE)。
指定一个数据库并连接到它 ( DECLARE DATABASE, CONNECT)。
分配变量名称 ( DECLARE STATEMENT)。
初始化描述符 ( DESCRIBE)。
指定如何处理错误和警告条件 ( WHENEVER)。
解析并运行 SQL 语句 ( PREPARE, EXECUTE, EXECUTE IMMEDIATE)。
从数据库中检索数据 ( FETCH)。















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









