






以前简单说明过scrapy 集成s3 feed exports 的配置,以下是集成browserless 的处理,通过browserless 进行数据内容的处理(尤其适合包含了基于ajax的请求,以及延迟加载的项目)
项目准备
主要是s3以及browserless
- docker-compose
参考处理
如下图,实际上对于原始website 的请求,直接通过browserless 提供的content api 进行内容获取,之后browserless 会进行实际website 内容的加载,然后返回html content,scrapy 的parse 对于content 进行解析
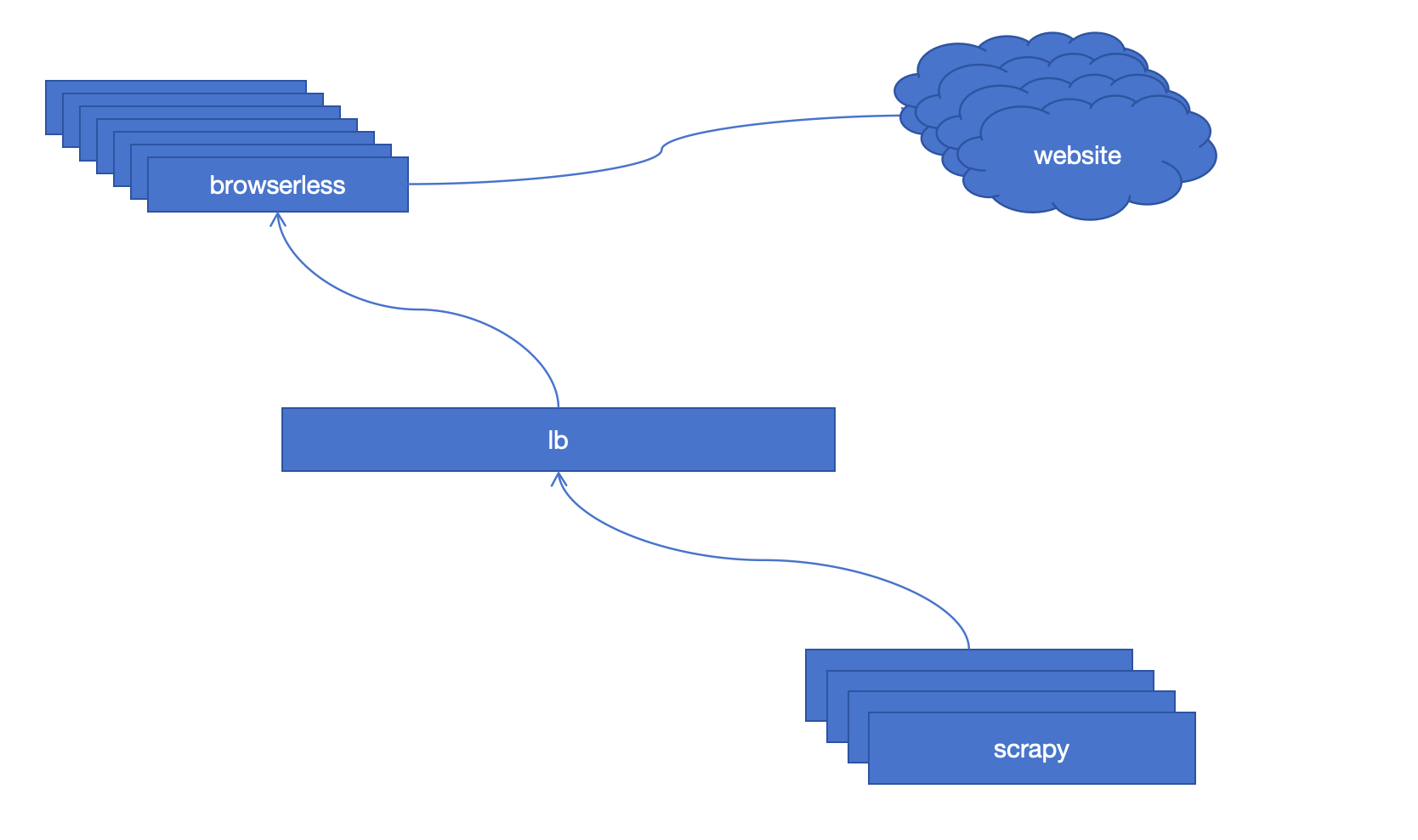
代码说明
关于scrapy 快速项目创建可以参考scrapy startproject <name> 命令,我只说明内容处理
- blog spider 代码
整个处理还是比较简单的,就是进行替换,scrapy.Request 的request 请求本来是website 现在到browserless 了,对于browserless 的请求是post
效果
说明
以上是一个简单示例,实际上对于大量爬去需求我们可以基于lb 部署多个browserless 服务,提升处理的稳定性,有些时候基于的模browserless 并不是一个较好的选择,毕竟browserless 处理还会慢一些,基于api 直接发起请求的处理可能是更好的选择
参考资料
https://www.browserless.io/blog/scrapy-headless
https://github.com/rongfengliang/scrapy-browserless-learning
https://docs.scrapy.org/en/latest/intro/tutorial.html















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









