







根据关键字爬取京东商城评论区图片
声明:本文章所涉及的技术和代码仅供学习交流使用,切勿扩散和频繁爬取网站。
分析过程
首先进入京东官网,在搜索栏中输入关键字如“三明治”,F12打谷歌开发者工具,选中network面板,network捕获的的请求分类栏中有all、xhr等,all代表的是所有请求,xhr代表的是异步请求,绝大多数的网站的大多数的重要数据请求都是采用异步请求,但此次京东搜索栏的搜索请求不是异步请求,按下enter键,发送搜索请求,然后就是分析请求,筛选出哪个是我们需要的请求,这一个过程很重要,下图是我找到的请求
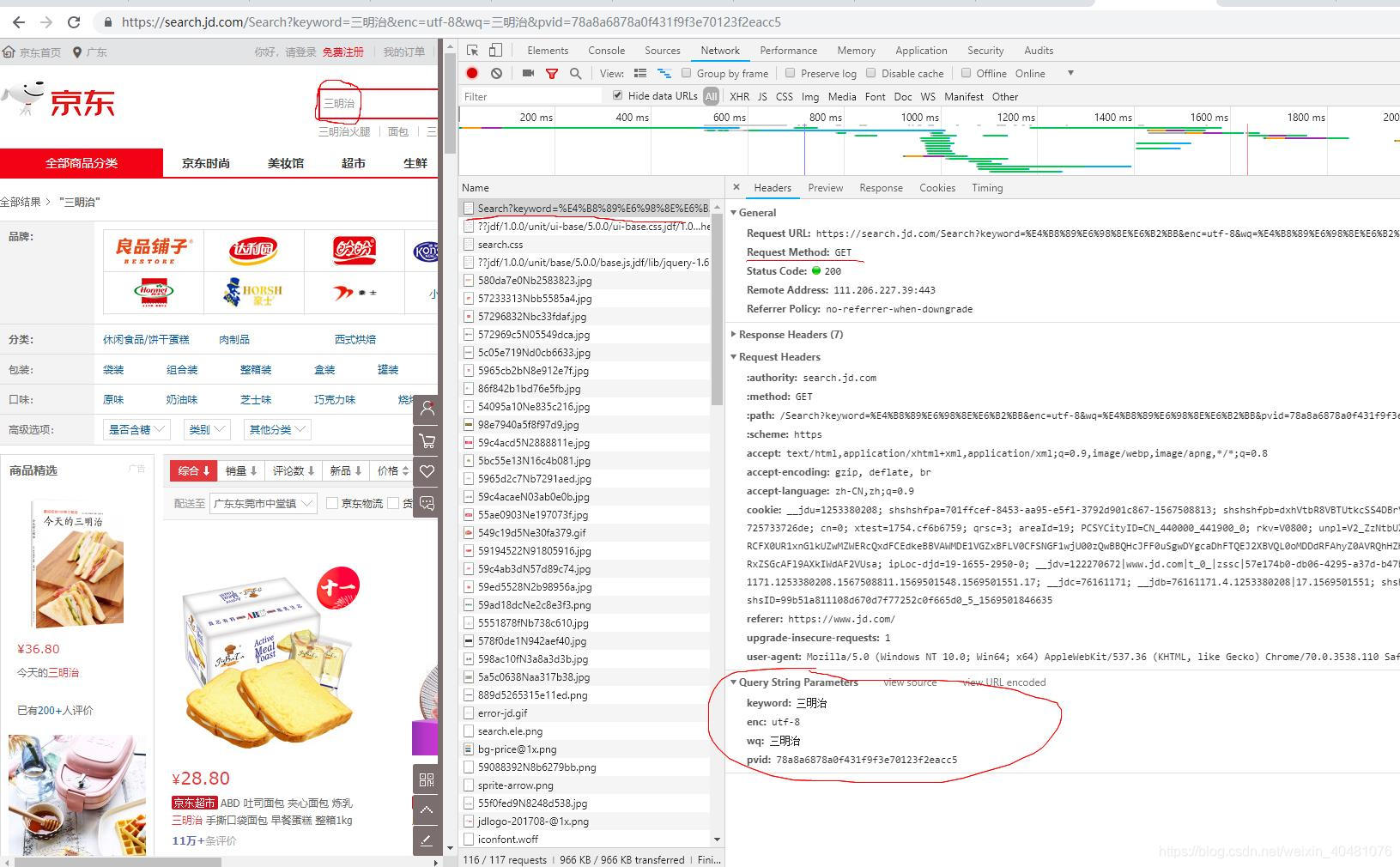
由此便得到了三明治这个类别商品的信息,注意这个请求有referer防盗链,headers信息头里面的信息不要遗漏。然后解析这个页面,得到商品的id信息
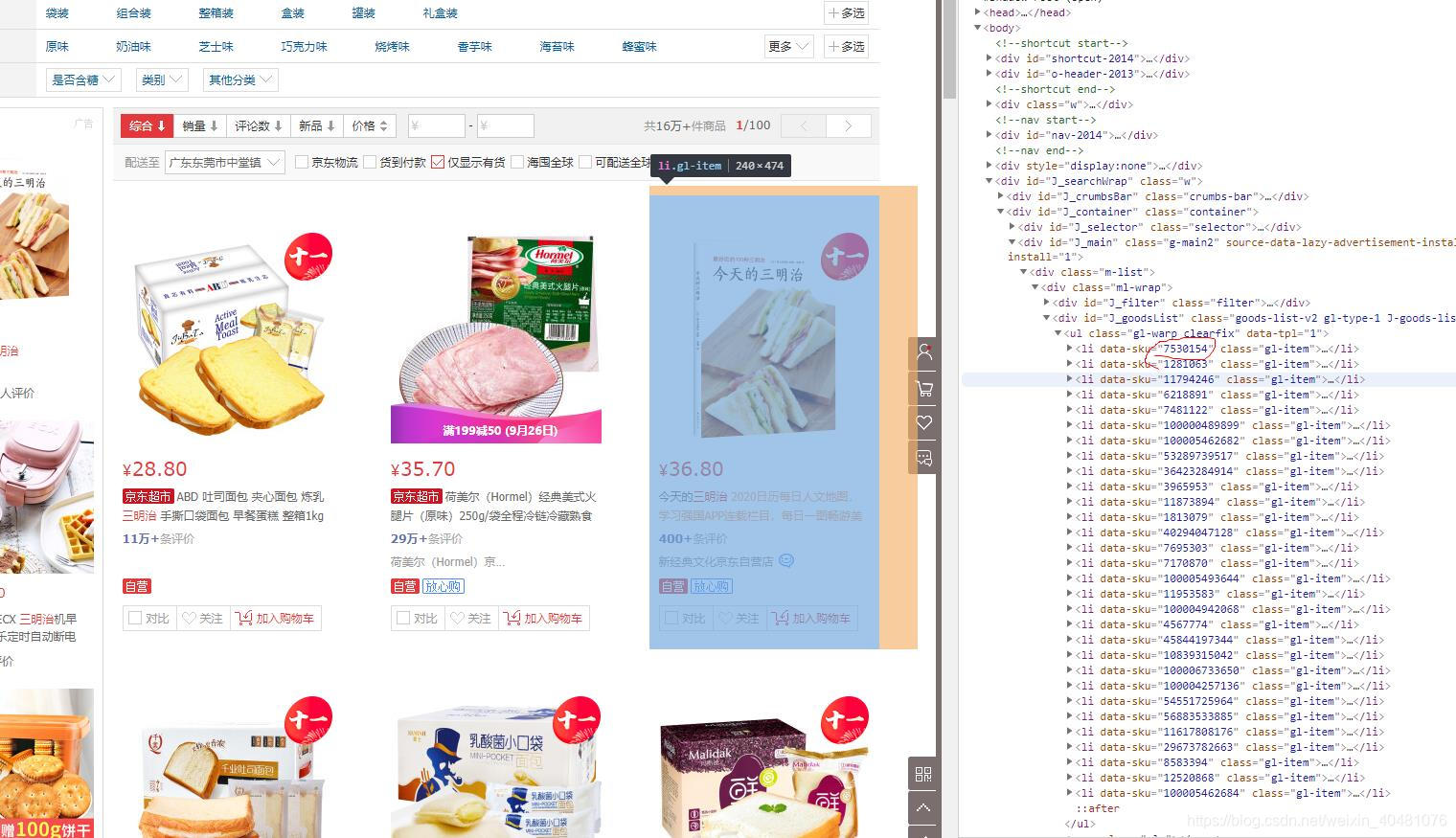
然后再再点击一个商品进入商品详情页,然后再打开谷歌开发者工具,选中network面板,选中下面的商品评价栏,再选中“晒图”,如下所示
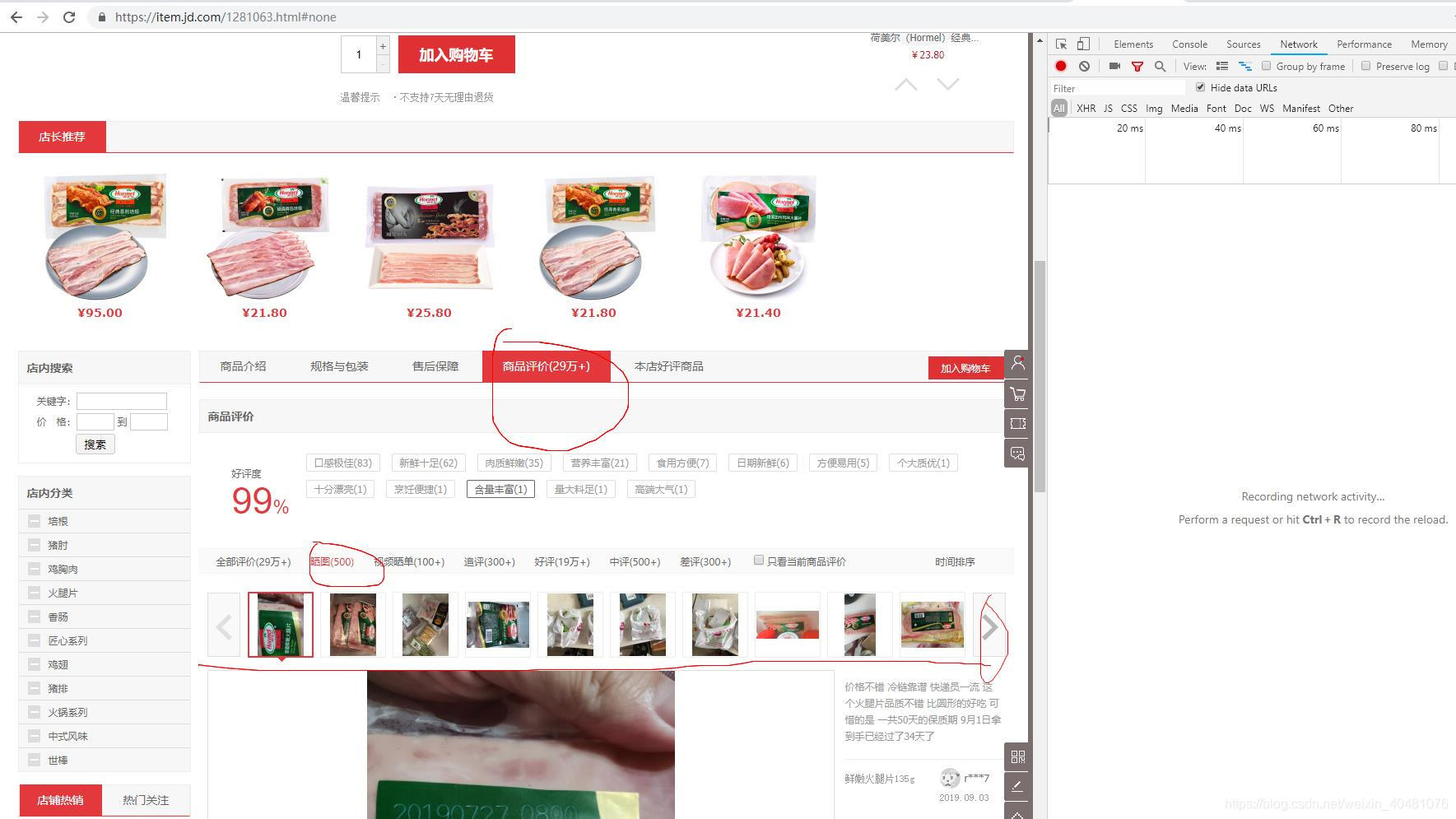
注意点击右边的图片翻动键,观察请求栏中的变化。
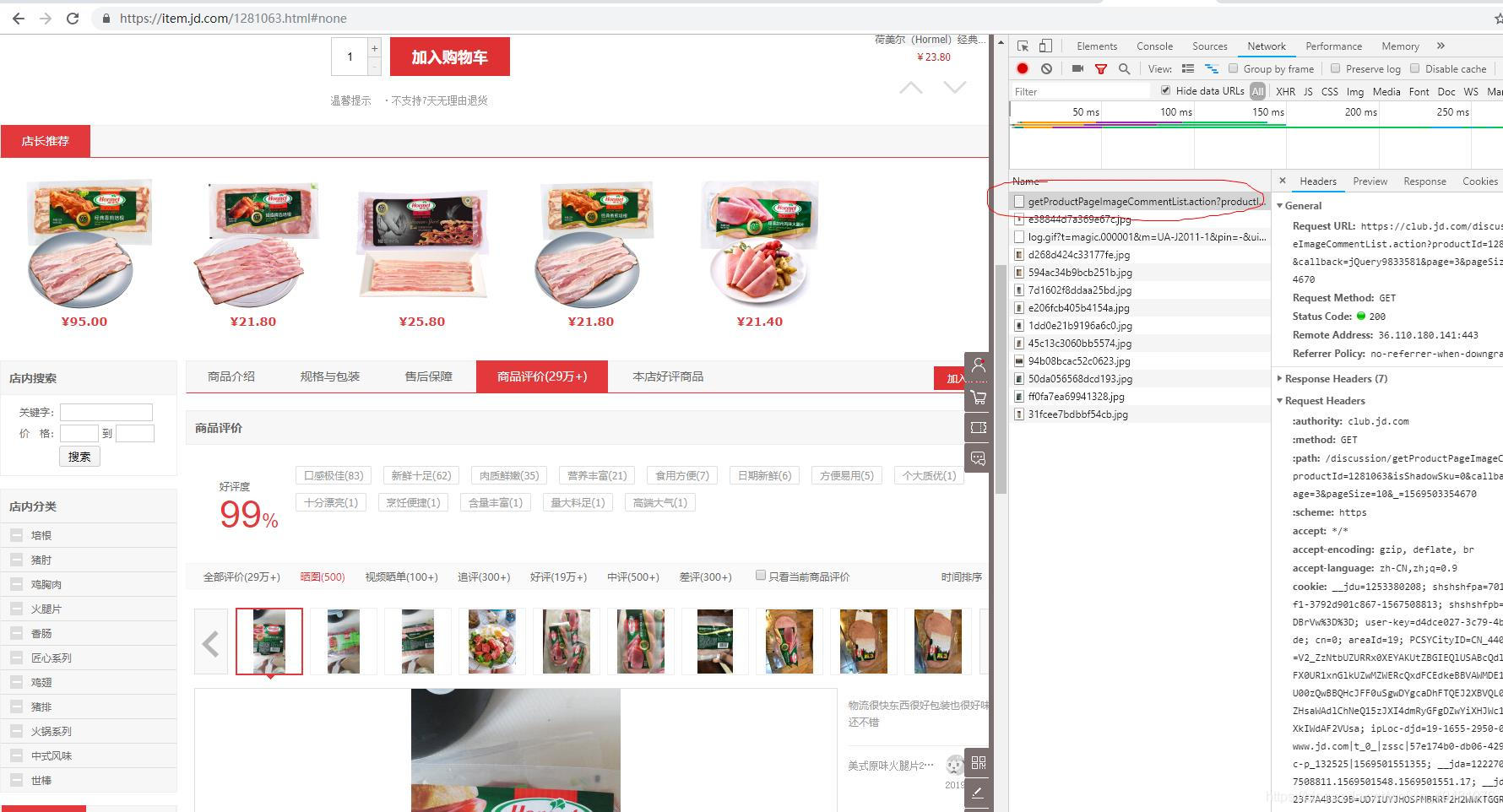
划动了一页就可以看到左边请求栏中的请求变化,出现“https://club.jd.com/discussion/getProductPageImageCommentList.action?productId=1281063&isShadowSku=0&callback=jQuery9833581&page=3&pageSize=10&_=1569503354670”的请求,是不是很眼熟“productId”,"productId"代表的是商品id,正是我们刚才爬取的目标,“page”很明显代表的是页码,“pageSize”不就是一页的数量吗?没有用的参数可以去掉。
然后我们在选中“preview”面板,该请求返回的json数据里面就有我们要的图片地址
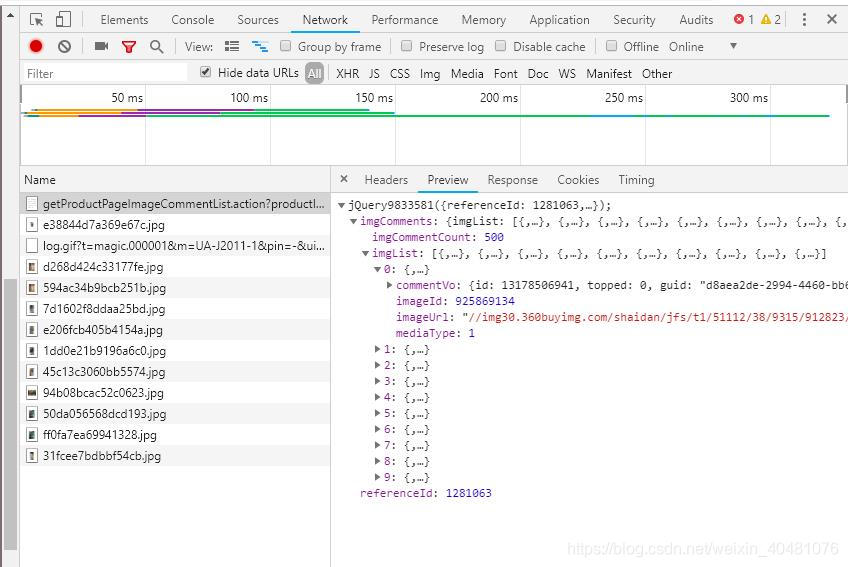
至此我们只要根据productId拼接该请求即可得到我们想要的评论区的图片,page(页码)我们自己控制,pageSize固定了。
总结
整个爬虫过程分为两步:
1、发送带关键字查询请求得到商品ID
2、根据商品ID自己拼接请求得到带有评论区图片地址的json。
代码
完整代码如下,博主码字不易,点个赞呗!
import json
import urllib
import jsonpath
import requests
import lxml
from lxml import etree
import os
def getProductIdsByKeyword(keyword):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'authority': 'search.jd.com',
'method': 'GET',
'scheme': 'https',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept - Encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'upgrade-insecure-requests': '1'
}
header['Referer'] = 'https://www.jd.com/'
url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
response = requests.get(url, headers=header)
response.encoding = 'utf-8'
response = lxml.etree.HTML(response.text)
productIds = response.xpath("//li[@class='gl-item']/@data-sku")
return productIds
def getJdCommentsImage(startPage,endPage,productId,path):
num=1
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'authority':'club.jd.com',
'method':'GET',
'scheme':'https',
'Accept': '*/*', 'Accept - Encoding': 'gzip, deflate, br'
}
header['path'] = '/discussion/getProductPageImageCommentList.action?productId='+productId+'&page='+str(num)+'&pageSize=10'
header['Referer'] = 'https://item.jd.com/'+productId+'.html'
requests.packages.urllib3.disable_warnings()
for num in range(startPage, (endPage + 1)):
url = 'https://club.jd.com/discussion/getProductPageImageCommentList.action?productId='+productId+'&page=' + str(
num) + '&pageSize=10'
# url_2 = 'https://club.jd.com/comment/skuProductPageComments.action?productId='+productId+'&page=' + str( num) + '&pageSize=10'
images = requests.post(url, headers=header, verify=False,timeout=10)
jsonObjs = json.loads(images.text)
# print(jsonObjs)
images = jsonpath.jsonpath(jsonObjs, '$..imageUrl')
i = 1
for image_url in images:
print('*' * 10 + '正在下载第' + str((num - 1) * 10 + i) + '张图片' + '*' * 10)
try:
# urllib.request.urlretrieve('https:'+image_url, path + productids[j]+str((num - 1) * 10 + i) + '.jpg')
res = urllib.request.urlopen('https:'+image_url,timeout=5).read()
with open(path + productids[j]+str((num - 1) * 10 + i) + '.jpg','wb') as file:
file.write(res)
file.close()
except Exception as e:
print('第' + str((num - 1) * 10 + i) + '张图片下载出错,错误信息如下:')
print(' ' * 10 + str(e))
print('')
continue
finally:
i += 1
print('*' * 15 + '下载完成' + '*' * 15)
# getJdCommentsImage(1,10,'d:/download/评论/') # 一页10张 (起始页,结束页,图片存储路径)
if __name__ == '__main__':
keywords = ['三明治'] # 分类关键字在这里放在这里
for keyword in keywords:
productids=getProductIdsByKeyword(keyword)
# print(len(productids))
path = 'd:/download/京东买家秀/' + keyword + '/'
if not os.path.exists(path):
os.makedirs(path)
for j in range(1,31):
try:
getJdCommentsImage(1,30,productids[j],path)
except Exception as e:
print(str(e))
continue

















 4515
4515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









