






1.Information Retrieval
定义:
Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
web search
- 数量庞大
- 需要索引
- 反欺诈
- 利用超链接
personal information retrieval:
- eg:Email
- 分类
- 垃圾邮件过滤
- 存储大量类别
- 维护免费
- 磁盘空间
enterprise,institutional, and domain-specific search
- stored on centralized file systems
线性查找:grep
- 在文本中查某个词足够了,但有其他需求
其他需求:
- 数据量大而多,快速处理
- flexible matching operations
- 排序
布尔模型
- query:布尔表达式
任务:
- ad hoc retrieval task.
- 输入query,输出doc列表(排序后)
评估
- precision
- recall
- …
专有名词
- term:索引的单元,如词、词组、潜在词等
- document:检索的单位,如网站列表,也可能是某一章节
- collection或者corpus:doc的集合
- information need
- 用户向计算机传递的需求
- 可能并不精确
- relevant:如果用户认为包含与其个人信息需求相关的信息
1.1 term-document matrix

词袋->doc向量:每列一个doc向量,每行一个term向量
query:Brutus AND Caesar AND NOT Calpurnia,
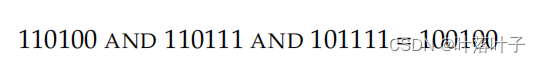
答案:Antony and Cleopatra and Hamlet
问题
- 稀疏,词表大难以存储–>倒排索引
1.2 倒排索引
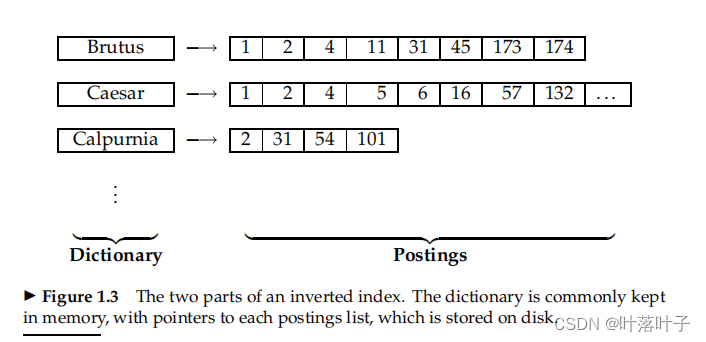
INVERTED INDEX
- dictionary(vacabulary):
- 内存
- key:term列表,也排序了,也会记录postings的长度(doc freq)
- value:postings list/postings:排好序的,按doc id,出线相关词的freq,…
- postings
- posting记录:docid,term在doc中出现的位置、freq,…
- 存储:disk
- 固定长度:不行,浪费
- linked list:链表,
- 便于插入,
- 便于扩展到advanced indexing strategies
- skip list,需要新的指针
- 问题:要存储指针
- 可变数组
- 顺序存储,遍历快
- 无需存储指针,指针可以是offset
- 混合
- 不变数组的链表
建立:
- Collect the documents to be indexed:
- 分词
- normalized
- index
- merge:相同term的相同doc合并
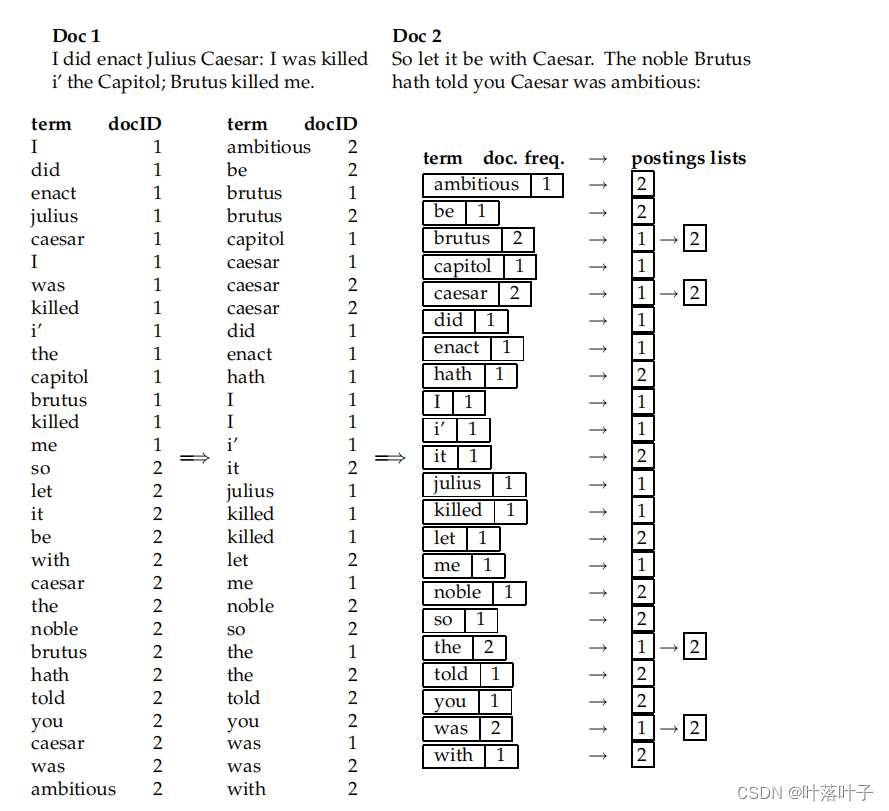
- merge:相同term的相同doc合并
1.3 Processing Boolean queries
- 得到每个term的postings
- OR:则两个表融合,取并集,AND:取交集,转化为AND链接的形式
取交集:(标准方法)

问题:取交集时,常数复杂度,但这个常数很大
解决:
- 先按doc freq排序(posting的长度),先合并短的
- 最终结果的长度不会超过最短的列表
- 这是保存doc freq.的原因
- 先算OR,再算AND

- 先算短的,然后保存到中间结果
- 每次下一个输入与中间结果求交集
- 问题:不对称
- 中间结果:内存;下一个输入:disk
- 但下一个输入可能比中间结果大得多(两个数量级?)
- 加速合并过程
- 中间结果的doc在长positng中二分查找合并
- 长postings采用哈希存储
- 上述无法用于压缩后的positngs
- 都是常见词,仍可以用标准法
带中间结果的求交集:

1.4 对基本布尔操作的扩展和有序检索
布尔检索和有序检索(排序检索模型)对应
布尔检索:
- query:精确的逻辑表达式
- 结果:无序
- 布尔操作符的扩展
- 邻近操作符:term的距离在文档中接近(中间含有几个词,来表征接近的程度
- 专业人士更喜欢布尔检索:查询精确,控制力和透明度
- 排序:按时间。。。
有序检索
- query:不像逻辑表达式这么精确,采用一个或多个词构建(自由文本查询)
- 结果:有序
要点
- term:提供,容忍拼写错误,词语表达不一致(语义相同)
- 复合词和短语:(Gates Near Microsoft)
- 相似度:布尔查询仅记录存在与否,但是我们需要得到文档相关的可靠程度
- 词项频率:term在doc中的频率高,权重高
- 排序
ad hoc search:
- 大搜、电商搜索。。。
- 部分支持布尔操作,专业人士喜欢,大多人用的少















 8274
8274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









