










摘要
研究了大规模知识图的学习推理问题。更具体地说,我们描述了一个用于学习多跳关系路径的新型强化学习框架:我们使用一个基于知识图嵌入的具有连续状态的基于策略的代理,该代理通过采样最有希望的关系来扩展其路径,从而在KG向量空间中进行推理。与之前的工作相比,我们的方法包含一个考虑准确性、多样性和效率的奖励函数。实验结果表明,该方法优于基于路径排序的算法
Introduction
- 复杂的自然语言处理问题往往需要多个相互关联的决策,而赋予深度学习模型学习推理的能力仍然是一个具有挑战性的问题
最近工作
- Path-Ranking Algorithm(PRA)
- PRA使用基于重启推理机制的随机行走来执行多个有界深度优先搜索过程来寻找关系路径。结合基于弹性网络的学习,PRA使用监督学习选择更合理的路径。
- 缺点:PRA是在一个完全离散的空间中运行的,这使得在KG中评估和比较相似的实体和关系变得困难
- 瓶颈:连接大量表单的超节点(连接大量表单的超节点
- A potential bottleneck for random walk inference is that supernodes connecting to large amount of formulas will create huge fan-out areas that significantly slow down the inference and affect the accuracy.(随机行走推理的一个潜在瓶颈是连接大量公式的超级节点会产生巨大的扇出区域,这会显著降低推理速度并影响推理的准确性。)
- 降低速度和准确性
基于PRA的其他方法
- Toutanova等(2015)提出了一种针对多跳推理的卷积神经网络解决方案。他们构建了一个基于词法化依赖路径的CNN模型,该模型存在解析错误导致的错误传播问题。
- Guu等(2015)使用KG嵌入来回答路径查询。
- Zeng et al.(2014)描述了一种用于关系提取的CNN模型,但是它并没有明确的对关系路径进行建模。
- Neelakantan等人(2015)提出了一种递归神经网络模型,用于知识库完成(KBC)中关系路径的建模,但是它训练了太多的独立模型,并且因此它不具有可伸缩性。
- 注意,最近的许多KG推理方法(Neelakantan et al., 2015;(Das et al., 2017)仍然依赖于首次学习PRA路径,它只在离散空间中运行。
其他使用强化学习的方法
-
神经符号机器(Liang et al., 2016)是KG推理的最新成果,它也应用了强化学习,但与我们的工作有不同的风格。NSM学习编写可以找到自然语言问题答案的程序,而为了得到答案,NSM学习生成一个可以组合成可执行程序的操作序列,NSM中的操作空间是一组预定义的令牌
-
使用
我们的方法
- 强化学习
- 策略梯度训练
- 连续空间:基于TransE
- 首次提出了学习知识图中关系路径的强化学习方法;
- 我们的学习方法使用一个复杂的奖励函数,同时考虑准确性、效率和路径多样性,在寻路过程中提供更好的控制和更大的灵活性;
- 我们证明,我们的方法可以扩展到大规模的知识图,在两个任务中都优于PRA和KG嵌入方法。
- 优点:与PRA相比,我们的方法是在一个连续的空间中推理,通过在奖励函数中加入各种标准,我们的强化学习(RL)框架对寻路过程有更好的控制和更大的灵活性。
- 与NSM比:
- 我们的RL模型则尝试通过现有的KG三元组推理向知识图(KG)中添加新的事实。
- 在我们的框架中,目标是找到推理路径,因此动作空间是KG中的关系空间。
- DQN比:
- 与Deep Q Network (DQN) (Mnih et al., 2013)相比,基于策略的RL方法更适合我们的知识图场景。原因之一是,对于KG中的寻路问题,由于关系图的复杂性,使得动作空间非常大。这可能导致DQN收敛性差。此外,该策略网络可以学习一个随机策略,避免agent陷入中间状态,而不是学习DQN等基于值的方法中常见的贪婪策略。
方法介绍(强化学习
In this section, we describe in detail our RL-based framework for multi-hop relation reasoning. The specific task of relation reasoning is to find reliable predictive paths between entity pairs. We formulate the path finding problem as a sequential decision making problem which can be solved with a RL agent. We first describe the environment and the policy-based RL agent. By interacting with the environment designed around the KG, the agent learns to pick the promising reasoning paths. Then we describe the training procedure of our RL model. After that, we describe an efficient path-constrained search algorithm for relation reasoning with the paths found by the RL agent.
在本节中,我们将详细描述基于rl的多跳关系推理框架。关联推理的具体任务是在实体对之间找到可靠的预测路径。我们将寻径问题描述为一个可以用RL代理来解决的顺序决策问题。我们首先描述环境和基于策略的RL代理。通过与围绕KG设计的环境交互,代理学会选择有希望的推理路径。然后描述了RL模型的训练过程。然后,我们描述了一个有效的路径约束搜索算法,用RL代理找到的路径进行关系推理。

-
环境:(S,A,P,R)
-
R-奖励
- 全局精度:走一步-1,到目的地+1
- 因为错误决策比正确决策多得多
- path effeciency:希望走短路径
- r e f f e c i e n c y = 1 l e n g t h r_{effeciency}=\frac{1}{length} reffeciency=length1
- path diversity:希望保证路径多样性
- r d i v e r s i t y = − 1 ∣ F ∣ Σ i = 1 ∣ F ∣ c o s ( p , p i ) p = Σ i = 1 n r i , r 是 关 系 r_{diversity}=-\frac{1}{|F|}\Sigma_{i=1}^{|F|}cos(p,p_i)\\p=\Sigma_{i=1}^nr_i,r是关系 rdiversity=−∣F∣1Σi=1∣F∣cos(p,pi)p=Σi=1nri,r是关系
- 全局精度:走一步-1,到目的地+1
-
S-状态-实体所在的位置 s t = ( e t , e t a r g e t − e t ) s_t=(e_t,e_{target}-e_t) st=(et,etarget−et)
-
A-行动(边,关系)
-
转移矩阵: P ( s i + 1 ∣ s i , a i ) P(s_{i+1}|s_i,a_i) P(si+1∣si,ai)
-
采取行动的概率: π ( s , a ) = p ( a ∣ s ) \pi(s,a)=p(a|s) π(s,a)=p(a∣s)
-
网络:全连接网络
-
2个隐层“:relu
-
输出层:sofmax
-
可能路径太多
- AlphaGo:AlphaGo首先使用专家棋训练一个有监督的策略网络。
- 我们:使用随机的广度优先搜索(BFS)训练监督策略。
-
监督学习部分:
-
对于每个关系,我们使用所有正样本的子集(实体对)来学习监督策略。对于每个阳性样本(esource、etarget),将执行一个双边BFS,以在实体之间找到相同的正确路径。对于每条路径p与关系序列r1→r2→…→rn,我们更新参数θ最大化预期累积奖励使用蒙特卡罗策略梯度
-
总奖励:
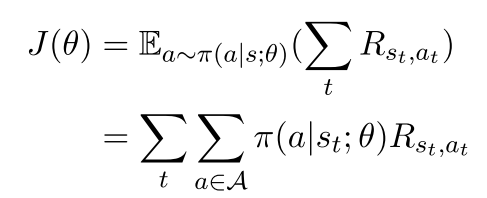
-
梯度:
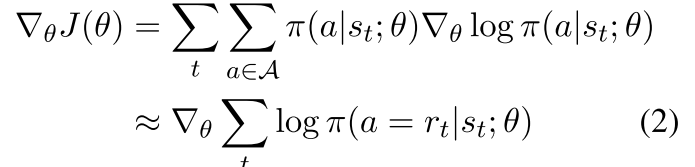
-
然而,普通的BFS是一种偏爱短路径的有偏搜索算法。当插入这些有偏差的路径时,代理很难找到可能有用的更长的路径。我们希望这些路径只由已定义的奖励函数控制。为了防止偏置搜索,我们采用了一个简单的技巧,向BFS中添加一些随机机制。我们没有直接搜索esource和etarget之间的路径,而是随机选择一个中间节点einter,然后在(esource, einter)和(einter, etarget)之间执行两个BFS。连接的路径用于训练代理。监督学习为agent节省了从失败行为中学习的大量精力。有了这些经验,我们就可以训练代理去寻找合适的路径。
-
然后再训练

-
Bi-directional Path-constrained Search减少中间节点个数(验证)
















 3016
3016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









