 Linux内存管理详解:页框、伙伴系统与SLAB分配器
Linux内存管理详解:页框、伙伴系统与SLAB分配器





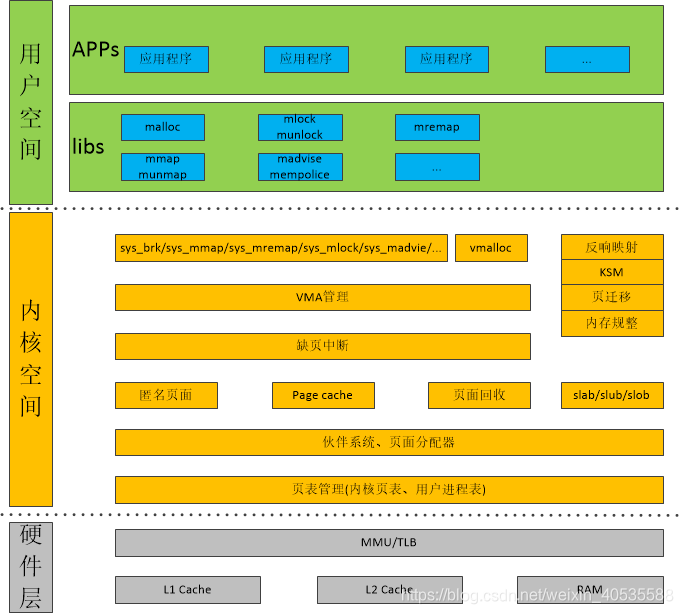
Linux内存管理框架图
一、页框管理
1.1. 页框的定义和数据结构
内核以页框为基本单位管理物理内存,分页单元中,页指一组数据,而存放这组数据的物理内存就是页框,当这组数据被释放后,若有其他数据请求访问此内存,那么页框中的页将会改变。
内核必须记录每个页框当前的状态。如,内核必须能区分哪些页框包含的是属于进展的也,哪些页框包含的是内核代码或者内核数据。同理,内核还必须能确认动态内存中页框是否空闲。这种状态信息被保存在一个描述符数组中,每个页框对应数组中的一个元素,这种类型为sruct page描述符
struct page是内存管理中第三个重要的数据结构,它代表系统内存的最小单位。(内存管理中重要的数据结构参考https://blog.csdn.net/melody157398/article/details/107241034)
- 内核用struct page结构表示系统中的每个物理页,该结构位于<linux/mm_types.h>中——下面给出了一个简略版的定义,去除了两个容易混淆我们讨论主题的联合结构体:

因为内核会为每一个物理页帧创建一个struct page的结构体,因此要保证page结构体足够的小,否则仅struct page就要占用大量的内存。
出于节省内存的考虑,struct page中使用了大量的联合体union。下面仅对常用的一些的字段做说明:
- flags:描述page的状态和其他信息
- _count域存放页的引用计数——也就是这一页被引用了多少次
- virtual域是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址
- 须要理解的一点是page结构与物理页相关,而并非与虚拟页相关。因此,该结构对页的描述只是短暂的。即使页中所包含的数据继续存在,由于交换等原因,它们也可能并不再和同一个page结构相关联。内核仅仅用这个数据结构来描述当前时刻在相关的物理页中存放的东西。 这种数据结构的目的在于描述物理内存本身,而不是描述包含在其中的数据
- 内核用这一结构来管理系统中所有的页,因为内核需要知道一个页是否空闲(也就是页有没有被分配)。如果页已经被分配,内核还需要知道谁拥有这个页。拥有者可能是用户空间进程、动态分配的内核数据、静态内核代码或页高速缓存等
- 系统中的每个物理页都要分配一个这样的结构体,开发者常常对此感到惊讶。他们会想 “这得浪费多少内存呀”!让我们来算算对所有这些页都这么做,到底要消耗掉多少内存。就算struct page占40个字节的内存吧,假定系统的物理页为8KB大小,系统有4GB物理内存。那么, 系统中共有页面 524288个,而描述这么多页面的page结构体消耗的内存只不过20MB:也许绝对值不小,但是相对系统4GB内存而言,仅是很小的一部分罢了。因此,要管理系统中这么多物理页面,这个代价并不算太大
https://www.cnblogs.com/zhaoyl/p/3695517.html
https://zhuanlan.zhihu.com/p/67059173
1.2.物理地址的空间分布
LInux下用伙伴系统管理物理内存页
伙伴系统得益于其良好的算法,一定程度上可以避免外部碎片为何这么说?先回顾下Linux下虚拟地址空间的分布。
x86的物理地址空间布局:
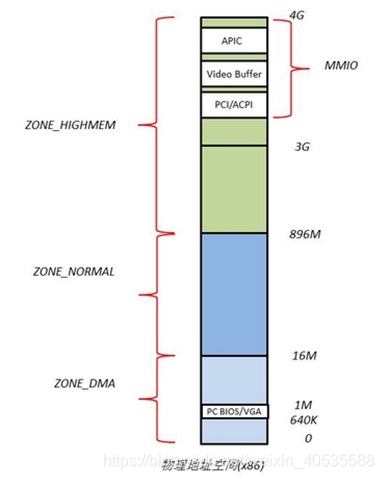
针对不同的用途,Linux内核将所有的物理页面划分到3类内存管理区中,如图,分别为ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM。
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束
- ZONE_DMA+ZONE_NORMAL属于直接映射区:虚拟地址=3G+物理地址 或 物理地址=虚拟地址-3G,从该区域分配内存不会触发页表操作来建立映射关系。
- ZONE_HIGHMEM属于动态映射区:128M虚拟地址空间可以动态映射到(X-896)M(其中X位物理内存大小)的物理内存,从该区域分配内存需要更新页表来建立映射关系,vmalloc就是从该区域申请内存,所以分配速度较慢。
直接映射区的作用是为了保证能够申请到物理地址上连续的内存区域,因为动态映射区,会产生内存碎片,导致系统启动一段时间后,想要成功申请到大量的连续的物理内存,非常困难,但是动态映射区带来了很高的灵活性(比如动态建立映射,缺页时才去加载物理页)。
Linux系统在初始化时,会根据实际的物理内存的大小,为每个物理页面创建一个page对象,所有的page对象构成一个mem_map数组。
1.3 linux虚拟地址内核空间分布
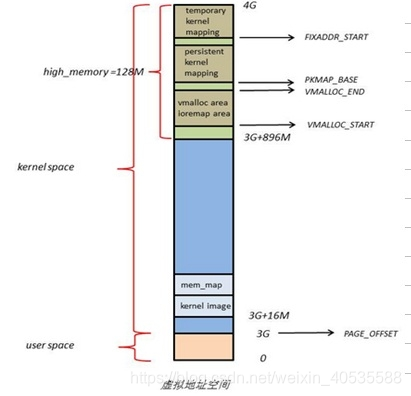
由于ZONE_NORMAL和内核线性空间存在直接映射关系,所以内核会将频繁使用的数据如kernel代码、GDT、IDT、PGD、mem_map数组等放在ZONE_NORMAL里。而将用户数据、页表(PT)等不常用数据放在ZONE_ HIGHMEM里,只在要访问这些数据时才建立映射关系(kmap())。比如,当内核要访问I/O设备存储空间时,就使用ioremap()将位于物理地址高端的mmio区内存映射到内核空间的vmalloc area中,在使用完之后便断开映射关系。
1.4 linux虚拟地址用户空间分布
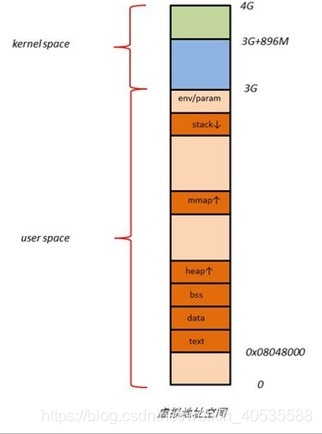
用户进程的代码区一般从虚拟地址空间的0x08048000开始,这是为了便于检查空指针。代码区之上便是数据区,未初始化数据区,堆区,栈区,以及参数、全局环境变量。
linux 应用程序加载地址
0x08048000 (32)
0x00400000 (64)
1.5 linux虚拟地址与物理地址映射的关系
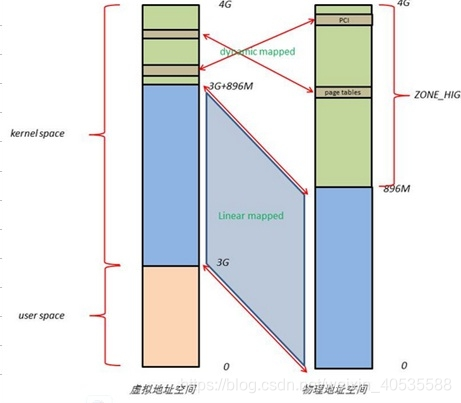
Linux将4G的线性地址空间分为2部分,0~3G为user space,3G~4G为kernel space。
由于开启了分页机制,内核想要访问物理地址空间的话,必须先建立映射关系,然后通过虚拟地址来访问。为了能够访问所有的物理地址空间,就要将全部物理地址空间映射到1G的内核线性空间中,这显然不可能。于是,内核将0~896M的物理地址空间一对一映射到自己的线性地址空间中,这样它便可以随时访问ZONE_DMA和ZONE_NORMAL里的物理页面;此时内核剩下的128M线性地址空间不足以完全映射所有的ZONE_HIGHMEM,Linux采取了动态映射的方法,即按需的将ZONE_HIGHMEM里的物理页面映射到kernel space的最后128M线性地址空间里,使用完之后释放映射关系,以供其它物理页面映射。虽然这样存在效率的问题,但是内核毕竟可以正常的访问所有的物理地址空间了。
- LInux内核加载在ZONE_NORMAL区域
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。读者会问,系 统启动时,内核的代码和数据不是被装入到物理内存吗?它们为什么也处于虚拟内存中呢?这和编译程序有关,后面我们通过具体讨论就会明白这一点。
虽 然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000)开始。对内核空间来说,其地址映射是很简单 的线性映射,0xC0000000就是物理地址与线性地址之间的位移量,在Linux代码中就叫做PAGE_OFFSET。
Linux内核高端内存的由来
参考:https://www.zhihu.com/question/280526042/answer/1616700795
(为什么需要高端内存)
对于内核,直接映射时虚拟地址0xc0000003对应的物理地址为0x00000003,0xc0000004对应的物理地址为0x00000004(可以看下面的linux虚拟地址与物理地址映射的关系)
虚拟地址与物理地址有如下的对应关系:
物理地址 = 虚拟地址 – 0xC0000000(3G)
如果按照上面所说的采用直接映射的方式,将内核1G的地址空间全部直接映射,就会发现内核只能访问1GB的物理内存,但是实际上我们的物理内存,往往是8G、16G,甚至更高,那么其他空间内核将无法访问和管控。所以必须要有一种灵活的方式,既减少开销,同时又让内核能够访问全部的物理内存,Linux高端内存十分必要。
Linux 规定“内核直接映射空间” 最多映射 896M 物理内存~
高端内存就是帮助我们访问除了直接映射的896MB物理内存之外的其他内存空间。
内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存呢?
在《深入理解LINUX内核》中介绍了,内核可以采用三种不同的机制将页框映射到高端内存,分别叫做:永久内存映射临时内存映射非连续内存分配当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的虚拟地址空间,借用一会。借用这段虚拟地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。
通俗地讲,"high memory"要解决的是32位下虚拟地址空间不足带来的问题(而显然,对64位系统这个问题就不存在了),因为32的物理内存最大时4G,但是64位时512G,已够用
2. 32位系统和64位系统的区别
32位和64位是指CPU处理器一次能处理的最大位数
- 对于32位,最大寻址空间2 ^32 = 4G(32位可以通过PAE,物理地址扩展,把32位线性地址转换为36位物理地址,PAE就是为了访问大于4GB的RAM,线性地址仍然是32位,而物理地址是36位。)
- 对于64位,原来应该是2^64 = 16EiB,但是系统用不到那么大的空间,所以系统使用48位作为寻址,即2 ^ 48 = 256T
c
地址映射
64位地址采用4层地址映射,如下图:

pgd、pud、pmd、pte各占了9位,加上12位的页内index,共用了48位。即可管理的地址空间为248=256T。而在32位地址模式时,该值仅为232=4G。
另外64位地址时支持的物理内存最大为64T,见e820.c中MAX_ARCH_PFN的定义:
#define MAX_ARCH_PFN MAXMEM>>PAGE_SHIFT
其中MAXMEM为2^46,PAGE_SHIFT为12。
https://www.cnblogs.com/wuchanming/p/4756911.html
https://blog.csdn.net/abc3240660/article/details/81484984
地址空间
32位与64位具体地址分布如下图:
-
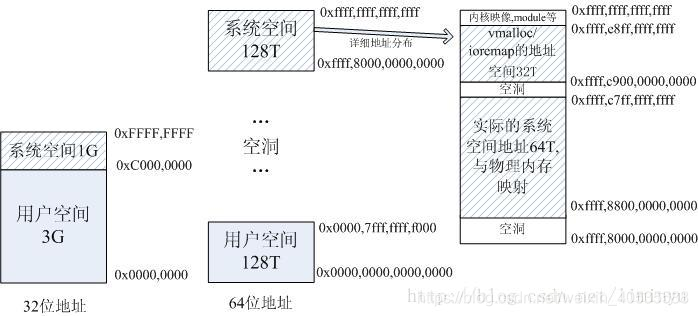
64位地址时将0x0000,0000,0000,0000 – 0x0000,7fff,ffff,f000这128T地址用于用户空间。
-
而0xffff,8000,0000,0000以上为系统空间地址。
-
另外0xffff,8800,0000,0000 – 0xffff,c7ff,ffff,ffff这64T直接和物理内存进行映射,0xffff,c900,0000,0000 – 0xffff,e8ff,ffff,ffff这32T用于vmalloc/ioremap的地址空间。
-
而32位地址空间时,当物理内存大于896M时(Linux2.4内核是896M,3.x内核是884M,是个经验值),由于地址空间的限制,内核只会将0~896M的地址进行映射,而896M以上的空间用做一些固定映射和vmalloc/ioremap。而64位地址时是将所有物理内存都进行映射。
-
在64位系统中,内核空间的映射变的简单了,因为这时内核的虚拟地址空间已经足够大了,即便它要访问所有的物理内存,直接映射就是,不再需要ZONE_HIGHMEM那种动态映射机制了。
注:虽然现在64位系统支持最大256T虚拟地址,64T物理地址,但是实际上现在市面上并没有这么大的RAM,现在通用的个人电脑大多都是4G/8G/16G或以上的内存条
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和物理地址有关系,和线性地址、逻辑地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
二、伙伴算法
2.1为什么会有伙伴算法
通常情况下,一个高级操作系统必须要给进程提供基本的、能够在任意时刻申请和释放任意大小内存的功能,就像malloc 函数那样,然而,实现malloc 函数并不简单,由于进程申请内存的大小是任意的,如果操作系统对malloc 函数的实现方法不对,将直接导致一个不可避免的问题,那就是内存碎片。
内存碎片就是内存被分割成很小很小的一些块,这些块虽然是空闲的,但是却小到无法使用。随着申请和释放次数的增加,内存将变得越来越不连续。最后,整个内存将只剩下碎片,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框就可能无法满足,所以减少内存浪费的核心就是尽量避免产生内存碎片。
针对这样的问题,有很多行之有效的解决方法,其中伙伴算法被证明是非常行之有效的一套内存管理方法,因此也被相当多的操作系统所采用。
2.1 算法作用
参考:https://blog.csdn.net/wenqian1991/article/details/27968779
它要解决的问题是频繁地请求和释放不同大小的一组连续页框,必然导致在已分配页框的块内分散了许多小块的空闲页面,由此带来的问题是,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框可能无法满足请求。
Linux 便是采用这著名的伙伴系统算法来解决外部碎片的问题。把所有的空闲页框分组为 11 块链表,每一块链表分别包含大小为1,2,4,8,16,32,64,128,256,512 和 1024 个连续的页框。对1024 个页框的最大请求对应着 4MB 大小的连续RAM ,因此,伙伴算法最多一次能够分配4M的内存空间。每一块的第一个页框的物理地址是该块大小的整数倍。例如,大小为 16个页框的块,其起始地址是 16 * 2^12 (2^12 = 4096,这是一个常规页的大小)的倍数。
下面通过一个简单的例子来说明该算法的工作原理:
假设要请求一个256(129~256)个页框的块。算法先在256个页框的链表中检查是否有一个空闲块。如果没有这样的块,算法会查找下一个更大的页块,也就是,在512个页框的链表中找一个空闲块。如果存在这样的块,内核就把512的页框分成两等分,一般用作满足需求,另一半则插入到256个页框的链表中。如果在512个页框的块链表中也没找到空闲块,就继续找更大的块——1024个页框的块。如果这样的块存在,内核就把1024个页框块的256个页框用作请求,然后剩余的768个页框中拿512个插入到512个页框的链表中,再把最后的256个插入到256个页框的链表中。如果1024个页框的链表还是空的,算法就放弃并发出错误信号。
简而言之,就是在分配内存时,首先从空闲的内存中搜索比申请的内存大的最小的内存块。如果这样的内存块存在,则将这块内存标记为“已用”,同时将该内存分配给应用程序。如果这样的内存不存在,则操作系统将寻找更大块的空闲内存,然后将这块内存平分成两部分,一部分返回给程序使用,另一部分作为空闲的内存块等待下一次被分配。
下面通过一个例子,来深入地理解一下伙伴算法的真正内涵(下面这个例子并不严格表示Linux 内核中的实现,是阐述伙伴算法的实现思想):
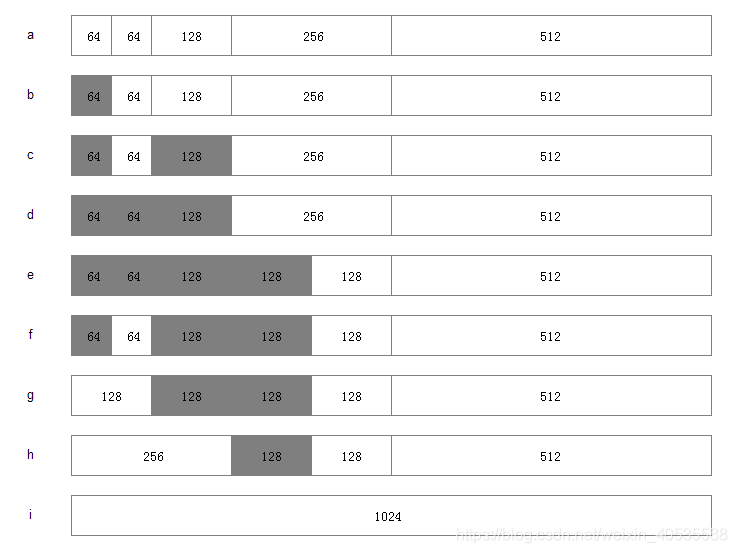
假设系统中有 1MB 大小的内存需要动态管理,按照伙伴算法的要求:需要将这1M大小的内存进行划分。这里,我们将这1M的内存分为 64K、64K、128K、256K、和512K 共五个部分,如下图 a 所示
-
1.此时,如果有一个程序A想要申请一块45K大小的内存,则系统会将第一块64K的内存块分配给该程序(产生内部碎片为代价),如图b所示;
-
2.然后程序B向系统申请一块68K大小的内存,系统会将128K内存分配给该程序,如图c所示;
-
3.接下来,程序C要申请一块大小为35K的内存。系统将空闲的64K内存分配给该程序,如图d所示;
-
4.之后程序D需要一块大小为90K的内存。当程序提出申请时,系统本该分配给程序D一块128K大小的内存,但此时内存中已经没有空闲的128K内存块了,于是根据伙伴算法的原理,系统会将256K大小的内存块平分,将其中一块分配给程序D,另一块作为空闲内存块保留,等待以后使用,如图e所示;
-
5.紧接着,程序C释放了它申请的64K内存。在内存释放的同时,系统还负责检查与之相邻并且同样大小的内存是否也空闲,由于此时程序A并没有释放它的内存,所以系统只会将程序C的64K内存回收,如图f所示;
-
6.然后程序A也释放掉由它申请的64K内存,系统随机发现与之相邻且大小相同的一段内存块恰好也处于空闲状态。于是,将两者合并成128K内存,如图g所示;
-
7.之后程序B释放掉它的128k,系统也将这块内存与相邻的128K内存合并成256K的空闲内存,如图h所示;
-
8.最后程序D也释放掉它的内存,经过三次合并后,系统得到了一块1024K的完整内存,如图i所示
有了前面的了解,我们通过Linux 内核源码(mmzone.h)来看看伙伴算法是如何实现的:
伙伴算法管理结构
#define MAX_ORDER 11
struct zone {
……
struct free_area free_area[MAX_ORDER];
……
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;//该组类别块空闲的个数
};
前面说到伙伴算法把所有的空闲页框分组为11块链表,内存分配的最大长度便是2^10页面。
上面两个结构体向我们揭示了伙伴算法管理结构。zone结构中的free_area数组,大小为11,分别存放着这11个组,free_area结构体里面又标注了该组别空闲内存块的情况。
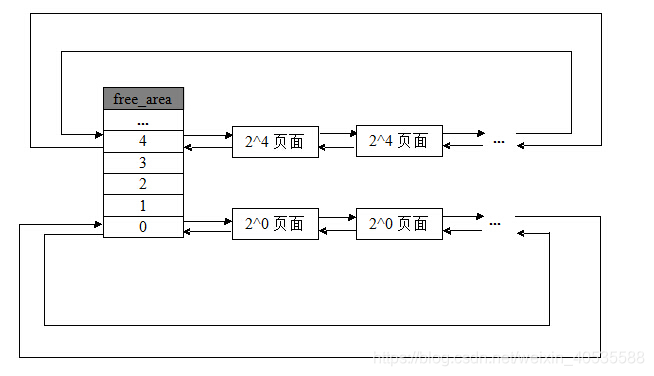
将所有空闲页框分为11个组,然后同等大小的串成一个链表对应到free_area数组中。这样能很好的管理这些不同大小页面的块。

三、内存区管理
伙伴系统系统算法采用页框作为基本内存区,这适合对于大块内存的请求,但我们处理对小内存区的请求呢,比如说几十或者几百个字节?
显然,如果为了存放很小的字节而给他分配一个整页框,这显然是一种浪费。取而代之的正确方法是引入一种新的数据结构来描述同一页框中如何分配小内存区。但这样也引入了一个新的问题,即所谓的内存碎片,内存碎片的产生主要是由于请求内存的大小与分配给它的大小不匹配而造成的。
https://blog.csdn.net/ibless/article/details/81367700
内部碎片和外部碎片
外部碎片指的是还没有被分配出去(不属于任何进程)但由于太小而无法分配给申请内存空间的新进程的内存空闲区域。外部碎片是除了任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。简单示例如下图:

如果某进程现在需要向操作系统申请地址连续的32K内存空间,注意是地址连续,实际上系统中当前共有10K+23K=33K空闲内存,但是这些空闲内存并不连续,所以不能满足进程的请求。这就是所谓的外部碎片,造成外部碎片的原因主要是进程或者系统频繁的申请和释放不同大小的一组连续页框。Linux操作系统中为了尽量避免外部碎片而采用了伙伴系统(Buddy System)算法。
内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;内部碎片是处于区域内部或页面内部的存储块,占有这些区域或页面的进程并不使用这个存储块,而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。简单示例如下图:

某进程向系统申请了3K内存空间,系统通过伙伴系统算法可能分配给进程4K(一个标准页面)内存空间,导致剩余1K内存空间无法被系统利用,造成了浪费。这是由于进程请求内存大小与系统分配给它的内存大小不匹配造成的。由于伙伴算法采用页框(Page Frame)作为基本内存区,适合于大块内存请求。在很多情况下,进程或者系统申请的内存都是4K(一个标准页面)的,依然采用伙伴算法必然会造成系统内存的极大浪费。为满足进程或者系统对小片内存的请求,对内存管理粒度更小的SLAB分配器就产生了。(注:Linux中的SLAB算法实际上是借鉴了Sun公司的Solaris操作系统中的SLAB模式)
3.1 SLAB分配器
参考:https://zhuanlan.zhihu.com/p/61457076
参考:https://www.jianshu.com/p/95d68389fbd1
3.1.1 为什么Linux内存管理要用到slab分配器
我们知道Linux内存以页为单位进行内存管理,buddy算法以2的n次方个页面来进行内存分配管理,最小为2^ 0, 也就是一页,最大为2^10,成就是4MB大小的连续内存空间。但是页的粒度还是太大,Linux下是4KB大小,也就是4096个字节,而kernel本身有很多数据结构时时刻刻都需要分配或者释放,这些数据的大小又往往小于4KB大小,一般只有几个几十个字节这样的大小。比方最常用到的task_struct结构体和mm_struct结构体,我们可以自己用下面程序测试一下它多大,可能不同机器上会有不同的结果。
#include<linux/slab.h>
#include<linux/module.h>
#include<linux/sched.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("");
int __init task_init(void)
{
struct task_struct p;
struct mm_struct m;
printk("sizeof task_struct = %ld,sizeof mm_struct = %ld\n",sizeof(p),sizeof(m));
return 0;
}
void __exit task_exit(void)
{
return;
}
module_init(task_init);
module_exit(task_exit);
sizeof task_struct = 9152,sizeof mm_struct = 2064
task_struct稍微大一点将近2个页面,mm_struct就只有差不多半个页面了。这样一来如果所有的这些数据结构都按照页来分配存储和管理,那么我相信kernel过不了多久自己就玩完了,内存碎片肯定一堆一堆。所以,引入slab分配器是为了弥补内存管理粒度太大的不足。
3.1.2 它能解决什么问题?
slab分配需要解决的是内存的内部碎片问题
3.1.3 它的核心思想是什么?
答案是使用对象的概念来管理内存
什么叫对象?这里的对象就是指具体相同的数据结构和大小的某个内存单元。比方上面所说的mm_struct结构体。我们知道,内核每创建一个进程时就需要给其分配mm_struct,这样一来内核中需要维护这个结构体的数目是相当多的,如果全部使用buddy分配器来分配,那么将会产生大量的碎片。而且,这种结构体在内核中分配和释放的频率是很高的,每分配一次又需要对它初始化,用过以后又需要释放,对系统的性能影响也很大。
这种场景是非常多的,为了应对这种场景,slab为这样的对象创建一个cache,即缓存。每个cache所占的内存区又被划分多个slab,每个 slab是由一个或多个连续的页框组成。每个页框中包含若干个对象,既有已经分配的对象,也包含空闲的对象。如下所示:
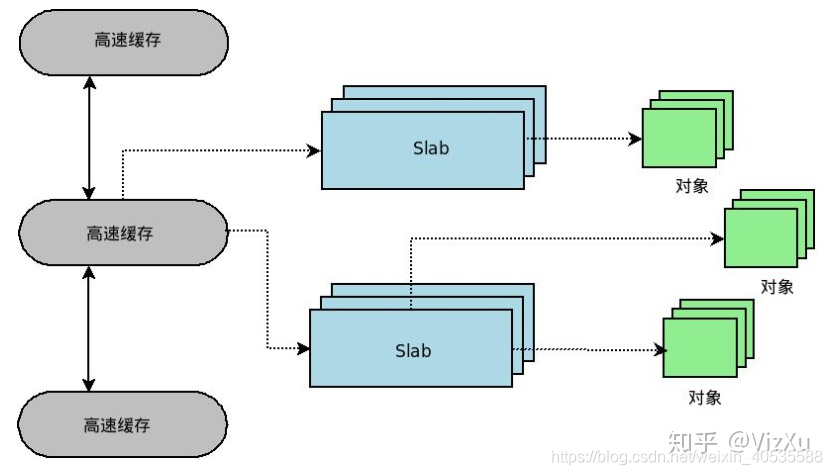
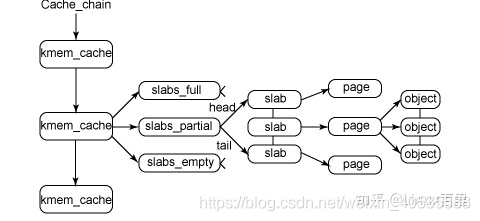
简要分析下这个图:kmem_cache是一个cache_chain的链表,描述了一个高速缓存,每个高速缓存包含了一个slabs的列表,这通常是一段连续的内存块。存在3种slab:slabs_full(完全分配的slab),slabs_partial(部分分配的slab),slabs_empty(空slab,或者没有对象被分配)。slab是slab分配器的最小单位,在实现上一个slab有一个货多个连续的物理页组成(通常只有一页)。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从slabs_partial中被删除,同时插入到slabs_full中去。
我们可以看出,内核对象的管理与用户进程中的堆管理比较相似,核心问题均是:如何高效地管理内存空间,使得可以快速地进行对象的分配和回收并减少内存碎片。但是内核不能简单地采用用户进程的基于堆的内存分配算法,这是因为内核对其对象的使用具有以下特殊性:
-
内核使用的对象种类繁多,应该采用一种统一的高效管理方法。
-
内核对某些对象(如 task_struct)的使用是非常频繁的,所以用户进程堆管理常用的基于搜索的分配算法比如First-Fit(在堆中搜索到的第一个满足请求的内存块)和 Best-Fit(使用堆中满足请求的最合适的内存块)并不直接适用,而应该采用某种缓冲区的机制。
-
内核对象中相当一部分成员需要某些特殊的初始化(例如队列头部)而并非简单地清成全 0。如果能充分重用已被释放的对象使得下次分配时无需初始化,那么可以提高内核的运行效率。
-
分配器对内核对象缓冲区的组织和管理必须充分考虑对硬件高速缓存的影响。
-
随着共享内存的多处理器系统的普及,多处理器同时分配某种类型对象的现象时常发生,因此分配器应该尽量避免处理器间同步的开销,应采用某种 Lock-Free 的算法。
每个高速缓存通过kmem_cache结构来描述,这个结构中包含了对当前高速缓存各种属性信息的描述
3.1.4 slab分配器的API有哪些
下面看一下slab分配器的接口——看看slab缓存是如何创建、撤销以及如何从缓存中分配一个对象的。
- 一个新的kmem_cache通过kmem_cache_create()函数来创建:
struct kmem_cache *
kmem_cache_create( const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void*));
- 撤销一个kmem_cache则是通过kmem_cache_destroy()函数:
int kmem_cache_destroy( struct kmem_cache *cachep);
- 从kmem_cache中分配一个对象:
void* kmem_cache_alloc(struct kmem_cache* cachep, gfp_t flags);
- 释放一个对象的函数如下:
void kmem_cache_free(struct kmem_cache* cachep, void* objp);
使用以上的API写内核模块,生成自己的slab高速缓存。
#include <linux/autoconf.h>
#include <linux/module.h>
#include <linux/slab.h>
MODULE_AUTHOR("wangzhangjun");
MODULE_DESCRIPTION("slab test module");
static struct kmem_cache *test_cachep = NULL;
struct slab_test
{
int val;
};
void fun_ctor(struct slab_test *object , struct kmem_cache *cachep , unsigned long flags )
{
printk(KERN_INFO "ctor fuction ...\n");
object->val = 1;
}
static int __init slab_init(void)
{
struct slab_test *object = NULL;//slab的一个对象
printk(KERN_INFO "slab_init\n");
//注意:这个函数的第二个参数(对象的大小),是有上限和下限的
//4Byte<=object size <= 4M(即在4字节到4M之间),如果不在这个范围之内,会导致内核崩溃
test_cachep = kmem_cache_create("test_cachep",sizeof(struct slab_test)*3,0,SLAB_HWCACHE_ALIGN,fun_ctor);
if(NULL == test_cachep)
return -ENOMEM ;
printk(KERN_INFO "Cache name is %s\n",kmem_cache_name(test_cachep));//获取高速缓存的名称
printk(KERN_INFO "Cache object size is %d\n",kmem_cache_size(test_cachep));//获取高速缓存的大小
object = kmem_cache_alloc(test_cachep,GFP_KERNEL);//从高速缓存中分配一个对象
if(object)
{
printk(KERN_INFO "alloc one val = %d\n",object->val);
kmem_cache_free( test_cachep, object );//归还对象到高速缓存
//这句话的意思是虽然对象归还到了高速缓存中,但是高速缓存中的值没有做修改
//只是修改了一些它的状态。
printk(KERN_INFO "alloc three val = %d\n",object->val);
object = NULL;
}else
return -ENOMEM;
return 0;
}
static void __exit slab_clean(void)
{
printk(KERN_INFO "slab_clean\n");
if(test_cachep)
kmem_cache_destroy(test_cachep);//调用这个函数时test_cachep所指向的缓存中所有的slab都要为空
}
module_init(slab_init);
module_exit(slab_clean);
MODULE_LICENSE("GPL");
我们结合结果来分析下这个内核模块:
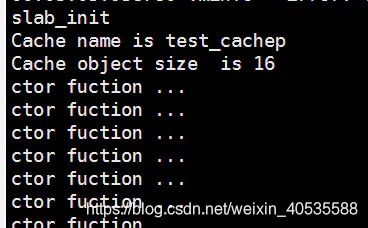
这是dmesg的结果,可以发现我们自己创建的高速缓存的名字test_cachep,还有每个对象的大小。
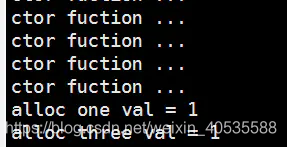
还有构造函数修改了对象里面的值,至于为什么构造函数会出现这么多次,可能是因为,这个函数被注册了之后,系统的其他地方也会调用这个函数。在这里可以分析源码,当调用keme_cache_create()的时候是没有调用对象的构造函数的,调用kmem_cache_create()并没有分配slab,而是在创建对象的时候发现没有空闲对象,在分配对象的时候,会调用构造函数初始化对象。
另外结合上面的代码可以发现,alloc three val是在kmem_cache_free之后打印的,但是它的值依然可以被打印出来,这充分说明了,slab这种机制是在将某个对象使用完之后,就其缓存起来,它还是切切实实的存在于内存中。
再结合/proc/slabinfo的信息看我们自己创建的slab高速缓存
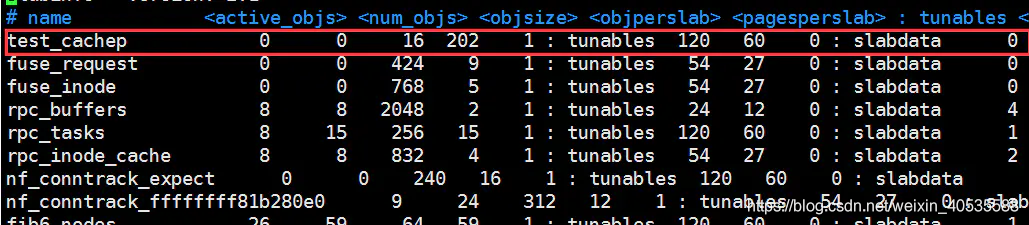
可以发现名字为test_cachep的高速缓存,每个对象的大小(objsize)是16,和上面dmesg看到的值相同,objperslab(每个slab中的对象时202),pagesperslab(每个slab中包含的页数),可以知道objsize * objperslab < pagesperslab。
在什么情况下,会用到slab
1.驱动开发使用的kmalloc(内核需要经常分配内存,我们在内核中最常用的分配内存的方式就是kmalloc了)
3.1.5 slab分配器和buddy系统的关系?
slab系统与buddy系统所要解决的问题是互补的,一个解决外部碎片一个解决内部碎片,但事实上,slab在新建cache时同样需要用到buddy来为之分配页面,而在释放cache时也需要buddy来回收这此页面。也就是说,slab事实上是依赖buddy系统的。
3.1.6 slab中算法中提到了着色,请问着色问题,主要是解决什么的?
用来防止高速缓存冲突的
着色即为缓存行添加偏移。
相同类型的slab、对象很有可能被保存到相同的CPU cache的缓存行中,经常使用的对象被放到CPU cache中,这当然使我们想要的,但如果两个不同的对象每次都被放到相同的缓存行中,那交替的读取这两个对象,会导致缓存行的内容不断的被更新,也就无法体现缓存的好处了。
3.1.7 slab算法有什么缺点,如果让你来设计,你怎么去改进它的缺点?
随着大规模多处理器系统和NUMA系统的广泛应用,slab分配器逐渐暴露出自身严重的不足:
- 较多复杂的队列管理。在slab分配器中存在众多的队列,例如针对处理器的本地缓存队列,slab中空闲队列,每个slab处于一个特定状态的队列之中。所以,管理太费劲了。
- slab管理数据和队列的存储开销比较大。每个slab需要一个struct slab数据结构和一个管理者kmem_bufctl_t型的数组。当对象体积较小时,该数组将造成较大的开销(比如对象大小为32字节时,将浪费1/8空间)。为了使得对象在硬件告诉缓存中对齐和使用着色策略,还必须浪费额外的内存。同时,缓冲区针对节点和处理器的队列也会浪费不少内存。测试表明在一个1000节点/处理器的大规模NUMA系统中,数GB内存被用来维护队列和对象引用。
- 缓冲区回收比较复杂。
- 对NUMA的支持非常复杂。slab对NUMA的支持基于物理页框分配器,无法细粒度的使用对象,因此不能保证处理器级的缓存来自同一节点(这个我暂时不太懂)。
- 冗余的partial队列。slab分配器针对每个节点都有一个partial队列,随着时间流逝,将有大量的partial slab产生,不利于内存的合理使用。
- 性能调优比较困难。针对每个slab可以调整的参数比较复杂,而且分配处理器本地缓存时,不得不使用自旋锁。
- 调试功能比较难于使用。
为了解决以上slab分配器的不足,引入新的解决方案,slub分配器。slub分配器的特点是简化设计理念,同时保留slab分配器的基本思想:每个缓冲区有多个slab组成,每个slab包含固定数目的对象。slub分配器简化了kmem_cache,slab等相关的管理结构,摈弃了slab分配器中的众多队列概念,并针对多处理器、NUMA系统进行优化,从而提高了性能和可扩展性并降低了内存的浪费。并且,为了保证内核其他模块能无缝迁移到slub分配器,API接口函数与slab保持一致。
3.2 SLUB分配器
参考:https://blog.csdn.net/Vince_/article/details/79668199
多年以来,Linux 内核使用一种称为SLAB 的内核对象缓冲区分配器。但是,随着系统规模的不断增大,SLAB 逐渐暴露出自身的诸多不足。SLUB 是 Linux 内核 2.6.22 版本中引入的一种新型分配器,它具有设计简单、代码精简、额外内存占用率小、扩展性高,性能优秀、方便调试等特点。
首先为什么要说slub分配器,内核里小内存分配一共有三种,SLAB/SLUB/SLOB,slub分配器是slab分配器的进化版,而slob是一种精简的小内存分配算法,主要用于嵌入式系统。慢慢的slab分配器或许会被slub取代,所以对slub的了解是十分有必要的。
我们先说说slab分配器的弊端,我们知道slab分配器中每个node结点有三个链表,分别是空闲slab链表,部分空slab链表,已满slab链表,这三个链表中维护着对应的slab缓冲区。我们也知道slab缓冲区的内存是从伙伴系统中申请过来的,我们设想一个情景,如果没有内存回收机制的情况下,只要申请的slab缓冲区就会存入这三个链表中,并不会返回到伙伴系统里,如果这个类型的SLAB迎来了一个分配高峰期,将会从伙伴系统中获取很多页面去生成许多slab缓冲区,之后这些slab缓冲区并不会自动返回到伙伴系统中,而是会添加到node结点的这三个slab链表中去,这样就会有很多slab缓冲区是很少用到的。
而slub分配器把node结点的这三个链表精简为了一个链表,只保留了部分空slab链表,而SLUB中对于每个CPU来说已经不使用空闲对象链表,而是直接使用单个slab,并且每个CPU都维护有自己的一个部分空链表。在slub分配器中,对于每个node结点,也没有了所有CPU共享的空闲对象链表。我们用以下图来表示以下slab分配器和slub分配器的区别(上图为SLAB,下图为SLUB):
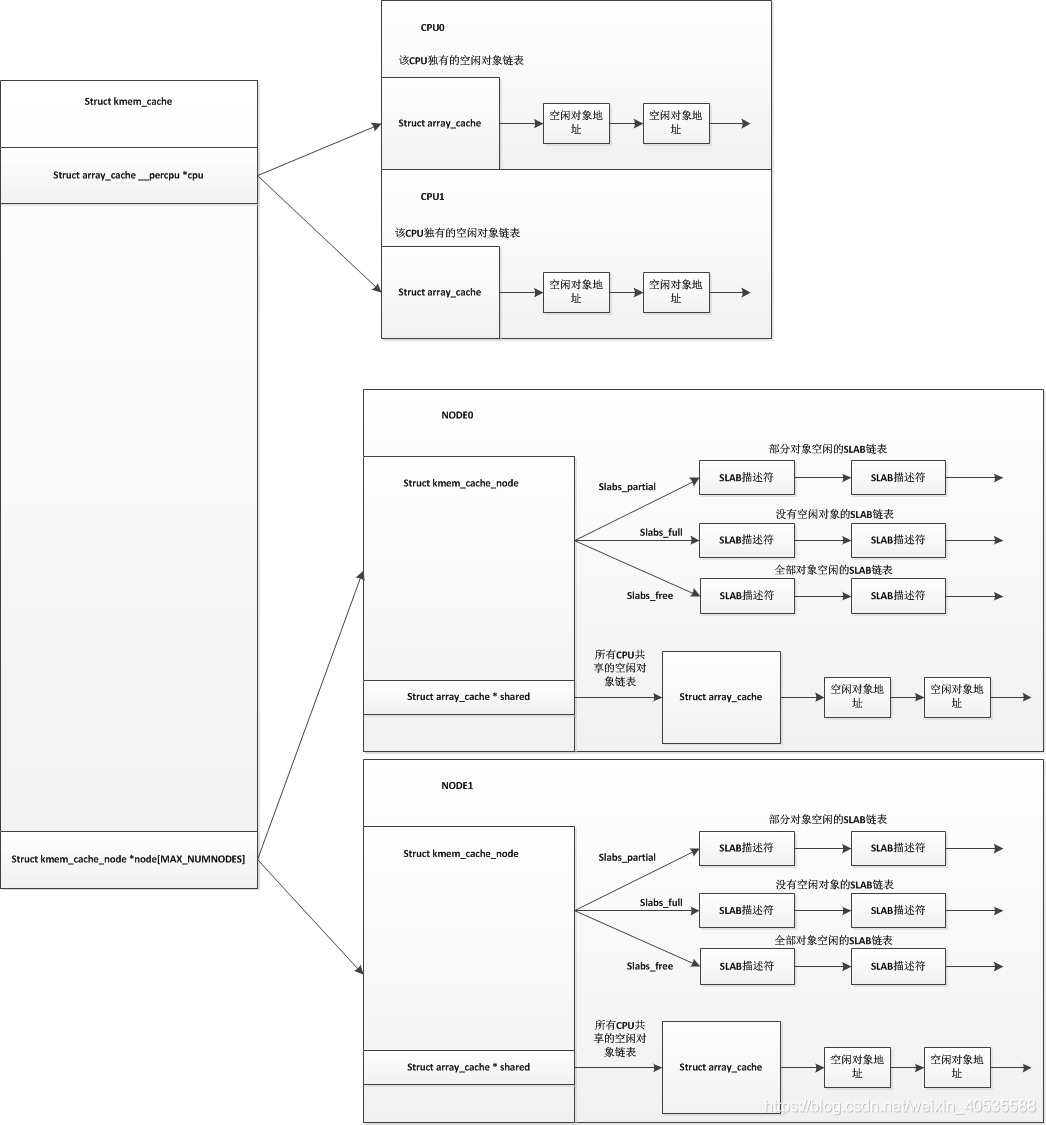
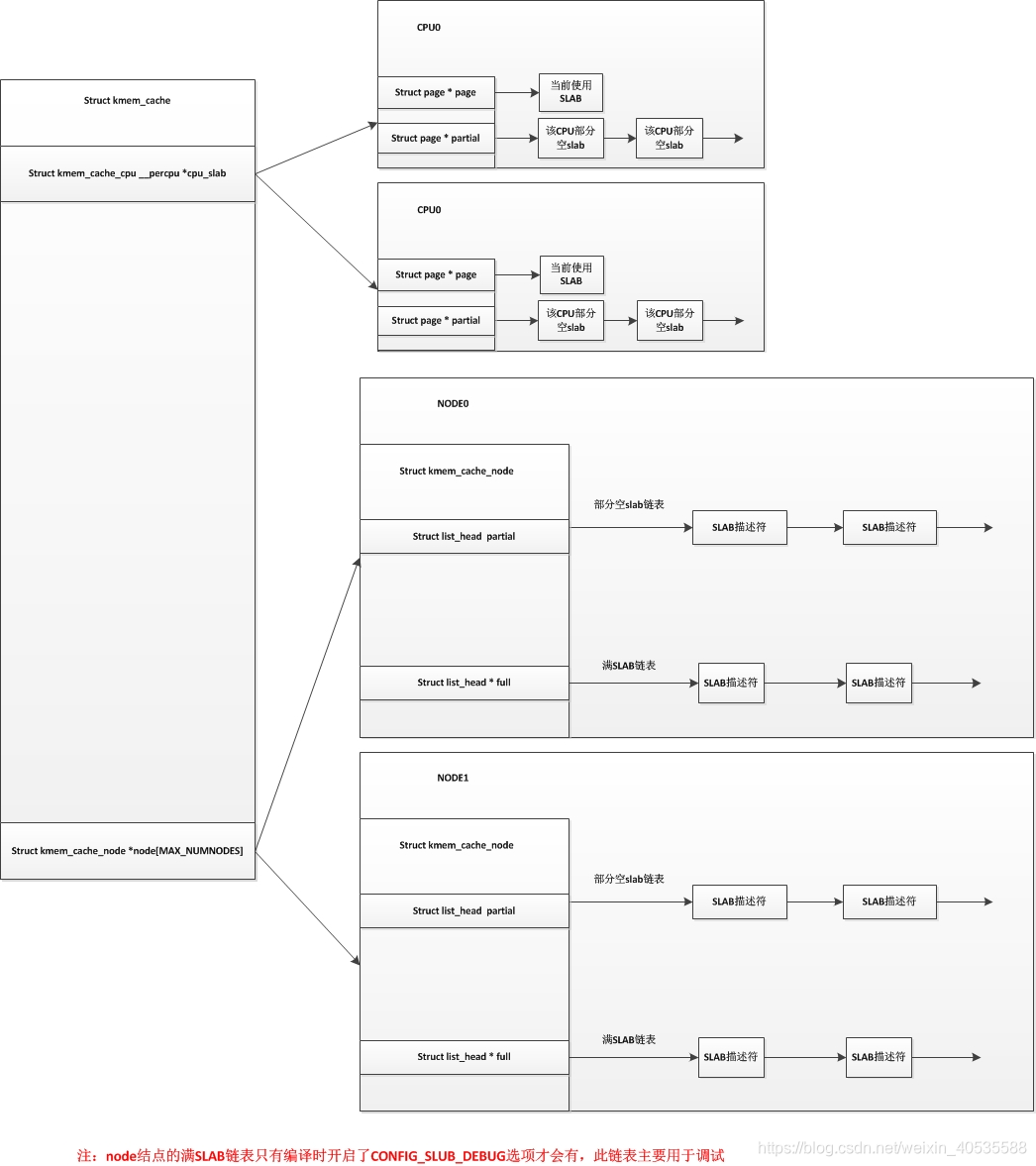
SLUB分配器的原理:
https://blog.csdn.net/lukuen/article/details/6935068
四、非连续内存区管理
先来回顾一下虚拟内存地址空间和物理内存的映射关系:
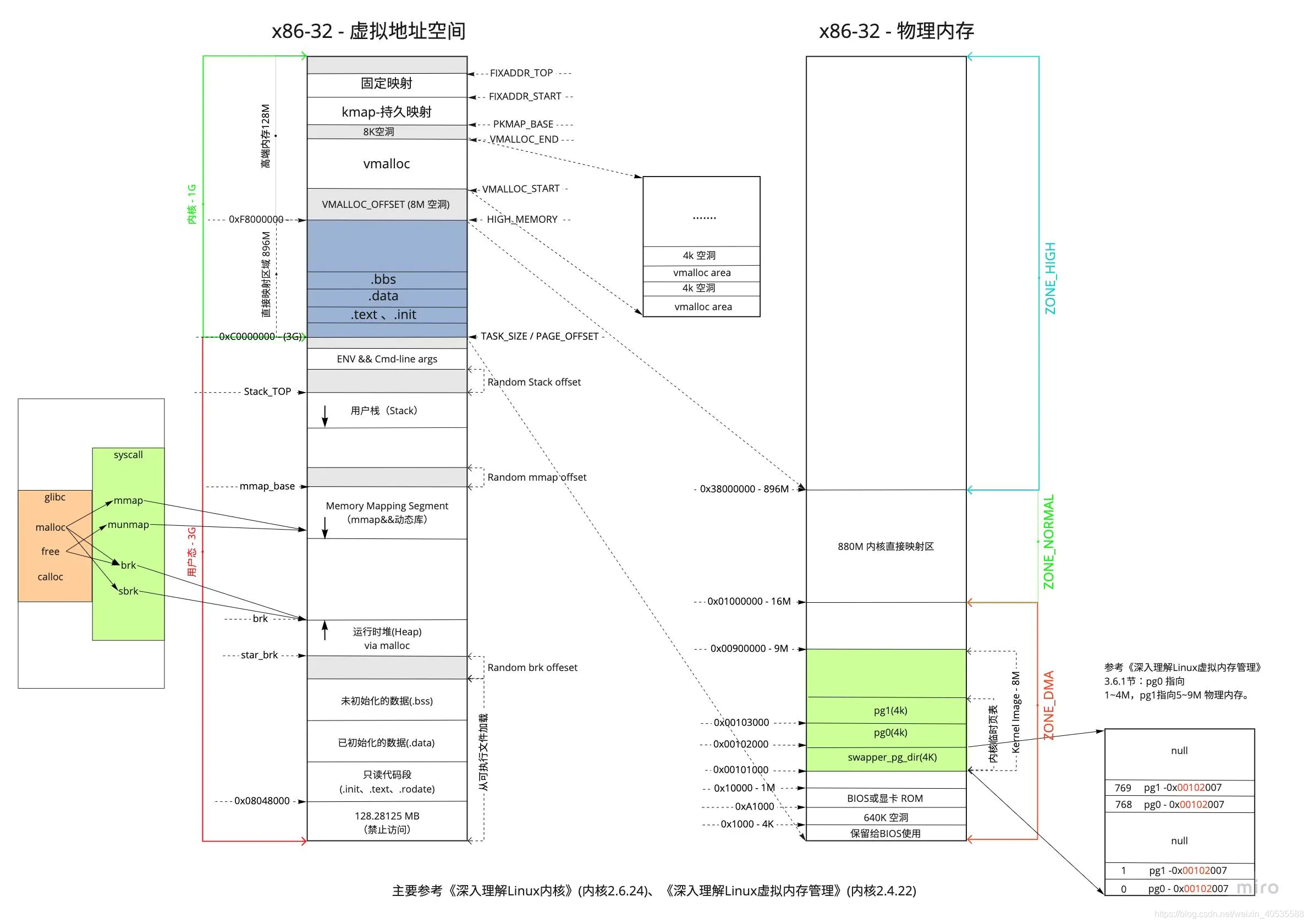
虚拟地址空间0~3G用于应用层
虚拟地址空间3~4G用于内核层
内核又将3~4G的虚拟地址空间,划分为如下几个部分:

-
直接映射区:线性空间中从3G开始最大896M的区间,为直接内存映射区,该区域的线性地址和物理地址存在线性转换关系:线性地址=3G+物理地址。
-
动态内存映射区:该区域由内核函数vmalloc来分配,特点是:线性空间连续,但是对应的物理空间不一定连续。vmalloc分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。
-
永久内存映射区:该区域可访问高端内存。访问方法是使用alloc_page(_GFP_HIGHMEM)分配高端内存页或者使用kmap函数将分配到的高端内存映射到该区域。
-
固定映射区:该区域和4G的顶端只有4k的隔离带,其每个地址项都服务于特定的用途,如ACPI_BASE等。
上图中的动态内存映射区就是非连续内存区,线性地址空间的起始地址由VMALLOC_START宏定义,而末尾地址由VMALLOC_END宏定义
4. 1 非连续内存区结构
参考:https://www.cnblogs.com/eustoma/archive/2012/04/28/2474608.html
Linux用vm_struct结构来表示vmalloc使用的线性地址
借用《深入理解linux内核》的图:
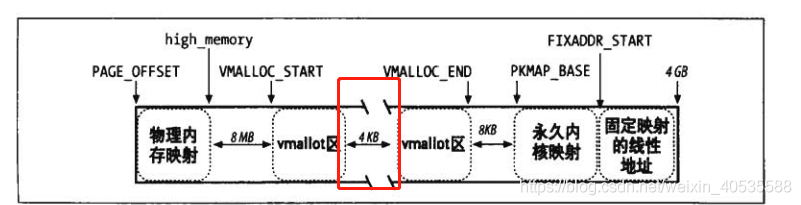
从上图中我们可以看到每一个vmalloc_area用4KB隔开,这样做是为了很容易就能捕捉到越界访问,因为中间是一个 “空洞”.
下面来分析一下vmalloc area的数据结构:
struct vm_struct {
void *addr; //虚拟地址
unsigned long size; //vm的大小
unsigned long flags; //vm的标志
struct page **pages; //vm所映射的page
unsigned int nr_pages; //page个数
unsigned long phys_addr; //对应的起始物理地址
struct vm_struct *next; //下一个vm.用来形成链表
}
对于分配非连续内存区和释放内存区这里不做深究,可以参考:
五、 kmalloc,vmalloc,malloc的区别
参考:https://www.cnblogs.com/hongzhunzhun/p/4533960.html(带用例)
简单的说:
- 1.kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
- 2.kmalloc保证分配的内存在物理上是连续的,vmalloc保证的是在虚拟地址空间上的连续,malloc不保证任何东西(这点是自己猜测的,不一定正确)
- 3.kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
- 4.内存只有在要被DMA访问的时候才需要物理上连续
- 5.vmalloc比kmalloc要慢
malloc是用户空间的,后面再讨论,我们重点看kmalloc和vmalloc的区别:
在设备驱动程序或者内核模块中动态开辟内存,不是用malloc,而是kmalloc
,vmalloc,释放内存用的是kfree,vfree,kmalloc函数返回的是虚拟地址(线性地址).
kmalloc特殊之处在于它分配的内存是物理上连续的,这对于要进行DMA的设备十分重要.
而用vmalloc分配的内存只是线性地址连续,物理地址不一定连续,不能直接用于DMA。vmalloc函数的工作方式类似于kmalloc,只不过前者分配的内存虚拟地址是连续的,而物理地址则无需连
续。通过vmalloc获得的页必须一个一个地进行映射,效率不高,
因此,只在不得已(一般是为了获得大块内存)时使用。vmalloc函数返回一个指针,指向逻辑上连续的一块内存区,其大小至少为size。在发生错误时,函数返回NULL。vmalloc可能睡眠,因此,不能从中断上下文中进行调用,也不能从其它不允许阻塞的情况下调用。要释放通过vmalloc所获
得的内存,应使用vfree函数
vmalloc和kmalloc的分配内存的特点大概如下:
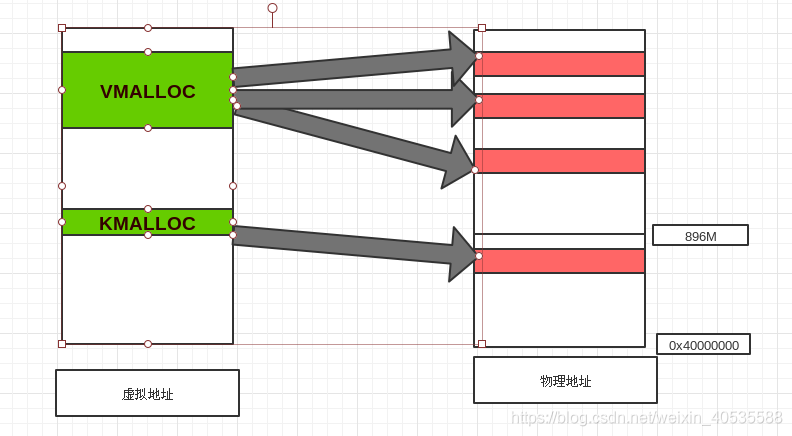
可以看到,kmalloc保证分配的内存在物理上是连续的,vmalloc保证的是在虚拟地址空间上的连续
区别大概可总结为:
1,vmalloc分配的一般为高端内存,只有当内存不够的时候才分配低端内存;kmallco从低端内存分配。
2,vmalloc分配的物理地址一般不连续,而kmalloc分配的地址连续,两者分配的虚拟地址都是连续的;
3,vmalloc分配的一般为大块内存,而kmaooc一般分配的为小块内存,(一般不超过128k);
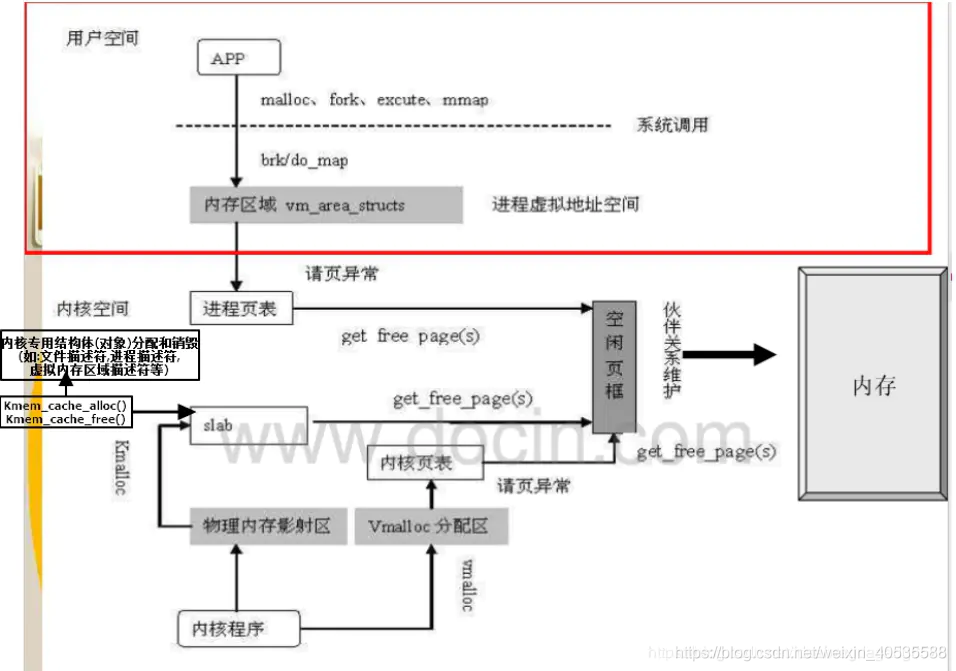
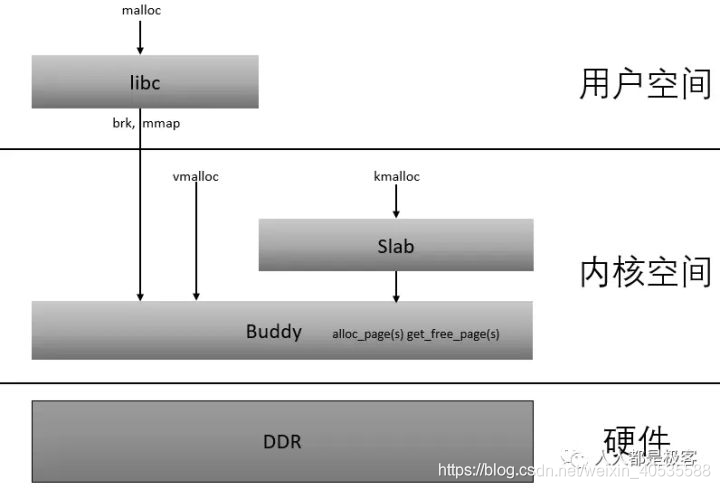
有一篇文章整理linux的内存管理整理得比较好:https://www.jianshu.com/p/a563a5565705
思考问答
- 在系统启动时,ARM Linux内核如何知道系统中有多大的内存空间?
- 在32bit Linux内核中,用户空间和内核空间的比例通常是3:1,可以修改成2:2吗?
- 物理内存页面如何添加到伙伴系统中,是一页一页添加,还是以2的几次幂来加入呢?
- 内核的一级页表存放在什么地方?二级页表又存放在什么地方?
- 用户进程的一级页表存放在什么地方?二级页表呢?
- 在ARM32系统中,页表是如何映射的?在ARM64系统中,页表又是如何映射的?
- 请简述Linux内核在理想情况下页面分配器(page allocator)是如何分配出连续物理页面的。
- 在页面分配器中,如何从分配掩码(gfp_mask)中确定可以从哪些zone中分配内存?
- 页面分配器是按照什么方向来扫描zone的?
- 为用户进程分配物理内存,分配掩码应该选用GFP_KERNEL,还是GFP_HIGHUSER_MOVABLE呢?
- slab分配器是如何分配和释放小块内存的?
- slab分配器中有一个着色的概念(cache color),着色有什么作用?
- slab分配其中的slab对象有没有根据Per-CPU做一些优化?
- slab增长并导致大量不用的空闲对象,该如何解决?
- 请问kmalloc、vmalloc和malloc之间有什么区别以及实现上的差异?
- 使用用户态的API函数malloc()分配内存时,会马上为其分配物理内存吗?
- 假设不考虑libc的因素,malloc分配100Byte,那么实际上内核是为其分配100Byte吗?
- 假设两个用户进程打印的malloc()分配的虚拟地址是一样的,那么在内核中这两块虚拟内存是否打架了呢?
- vm_normal_page()函数返回的是什么样页面的struct page数据结构?为什么内存管理代码中需要这个函数?
- 请简述get_user_page()函数的作用和实现流程?
- 请简述follow_page()函数的作用和实现流程?
- 请简述私有映射和共享映射的区别。
- 为什么第二次调用mmap时,Linux内核没有捕捉到地址重叠并返回失败呢?
- struct page数据结构中的_count和_mapcount有什么区别?
- 匿名页面和page cache页面有什么区别?
- struct page数据结构中有一个锁,请问trylock_page()和lock_page()有什么区别?
- 在Linux 2.4.x内核中,如何从一个page找到所有映射该页面的VMA?反响映射可以带来哪些便利?
- 阅读Linux 4.0内核RMAP机制的代码,画出父子进程之间VMA、AVC、anon_vma和page等数据结构之间的关系图。
- 在Linux 2.6.34中,RMAP机制采用了新的实现,在Linux 2.6.33和之前的版本中称为旧版本RMAP机制。那么在旧版本RMAP机制中,如果父进程有1000个子进程,每个子进程都有一个VMA,这个VMA里面有1000个匿名页面,当所有的子进程的VMA同时发生写复制时会是什么情况呢?
- 当page加入lru链表中,被其他线程释放了这个page,那么lru链表如何知道这个page已经被释放了。
- kswapd内核线程何时会被唤醒?
- LRU链表如何知道page的活动频繁程度?
- kswapd按照什么原则来换出页面?
- kswapd按照什么方向来扫描zone?
- kswapd以什么标准来退出扫描LRU?
- 手持设备例如Android系统,没有swap分区或者swap文件,kswapd会扫描匿名页面LRU吗?
- swappiness的含义是什么?kswapd如何计算匿名页面和page cache之间的扫描比重?
- 当系统充斥着大量只访问一次的文件访问(use-one streaming IO)时,kswapd如何来规避这种风暴?
- 在回收page cache时,对于dirty的page cache,kswapd会马上回写吗?
- 内核有哪些页面会被kswapd写回交换分区?
- ARM32 Linux如何模拟这个Linux版本的L_PTE_YOUNG比特位呢?
- 如何理解Refault Distance算法?
- 请简述匿名页面的生命周期。在什么情况下会产生匿名页面?在什么条件下会释放匿名页面?
- KSM是基于什么原理来合并页面的?
- 在KSM机制里,合并过程中把page设置成写保护的函数write_protect_page()有这样一个判断:。这个判断的依据是什么?
- 如果多个VMA的虚拟页面同时映射了同一个匿名页面,那么此时page->index应该等于多少?
- 为什么Dirty COW小程序可以修改一个只读文件的内容?
- 在Dirty COW内存漏洞中,如果Diryt COW程序没有madviseThread线程,即只有procselfmemThread线程,能否修改foo文件的内容呢?
- 假设在内核空间获取了某个文件对应的page cache页面的struct page数据结构,而对应的VMA属性是只读,那么内核空间是否可以成功修改该文件呢?
- 如果用户进程使用只读属性(PROT_READ)来mmap映射一个文件到用户空间,然后使用memcpy来写这段内存空间,会是什么样的情况?
- 请画出内存管理中常用的数据结构的关系图,如mm_struct、vma、vaddr、page、pfn、pte、zone、paddr和pg_data等,并思考如下转换关系。
- 请画出在最糟糕的情况下分配若干个连续物理页面的流程图。
- 在Android中新添加了LMK(Low Memory Killer),请描述LMK和OOM Killer之间的关系。
- 请描述一致性DMA映射dma_alloc_coherent()函数在AEM中是如何管理cache一致性的?
- 请描述流式DMA映射dma_map_single()函数在ARM中是如何管理cache一致性的?
- 为什么在Linux 4.8内核中要把基于zone的LRU链表机制迁移到基于Node呢?
Linux内核内存管理架构
https://www.cnblogs.com/wahaha02/p/9392088.html

















 9119
9119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









