







下拉框提示词也称Suggestion(查询词提示),这已经是搜索引擎必备的一个功能了,而问答系统则是搜索引擎的精简版,也需要检索提示功能,给用户带来便捷,提高产品的体验感。
当你在搜索框进行输入时,搜索框会打开下拉的提示框,动态的向你提示一些与你已经出入内容相关的查询关键词。如果在提示框中看到自己所希望输入的关键词,直接用鼠标点击或键盘选择即可进行搜索,减少了用户输入的字符数量。
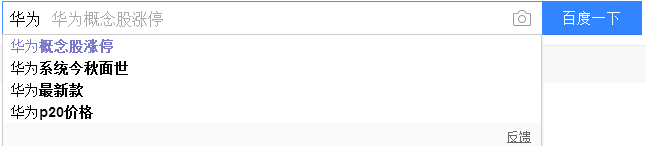
当然搜索框提示词分为中文提示和汉语拼音提示词。
中文提示:
汉语拼音提示:

为什么要将将汉字转为拼音呢?
我们希望我们的搜索引擎或问答检索系统能够更好的做到同音字的容错,采用拼音容错是一个不错的方法。因此,需要将汉字转换为拼音,提高它的容错性。同时,汉字转拼音组件还可以有多个用途,例如以拼音的首字母来检索小区名、人名等。所以汉字转换为拼音还是很重要的。
下面说一下如何将汉字转为拼音的:
1、首先必须有需要转为拼音的关键词
2、程序实现汉字转拼音
3、将汉字拼音对转化为固定格式,后续算法好操作
法一:这种方法只能全拼
# -*- coding:utf-8 -*-
import pinyin
pinyinTransfer = pinyin.PinYin()
pinyinTransfer.load_word()
print (pinyinTransfer.hanzi2pinyin("中华有为"))
print (pinyinTransfer.hanzi2pinyin_split("中华有为",split=""))结果:

法二:这种方法可以全拼、首字母拼、多音字识别、男方口音、声母、音调等,可以根据自己需求设置
例如:**我的英文名是Bob。**” 转化后为'**wo de ying wen ming shi Bob.**'
1、多种输出格式
声调:wǒ dē yīng wén míng shì Bob`或`wo3 de1 ying1 wen2 ming2 shi4 Bob
声母输出:w d y w m sh Bob
首字母输出:w d y w m s Bob
2、词组形式的拼音输出
例如输入:南京市 长江 大桥
输出:nanjingshi changjiang daqiao
3、多音字处理
例如输入:南京市长江大桥
输出:nan jing shi chang|zhang jiang da|dai qiao
4、南方口音
wo de yin wen min si Bob
5、API
convert(text, fmt=[df], sc=True, pp=False, fuzzy=0)
6、参数
text:待转化的文本
fmt:设定转换的方式的格式
`df` - Default 全拼
* `tm` - Tone Marks 全拼带音调
* `tn` - Tone Numbers 全拼带数字形式的音调
* `ic` - Initial Consonant only 声母
* `fl` - First Letter 首字母
sc:Split Character,是否以单个汉字为切割单位的拼音输出字为单位,其中True为单字拆分,False为不拆分。以输入的中文文本的分词为准。
pp:Polyphone 是否输出无法判断的多音字(词),其中False为不输出多音字,True为输出多音字
fuzzy:Puzzy 拼音模糊化
* `0` - 不处理
* `1` - 模糊化 z-zh c-ch s-sh
* `2` - 模糊化 k-g f-h l-n l-r
* `4` - 模糊化 an-ang en-eng in-ing lan-lang uan-uang
根据自己的需求设置即可。
7、返回结果
如果只需要一个格式,直接返回转换后的结果。例如调用`convert('南京市长江大桥')` 返回:
nan jing shi chang jiang da qiao
如果有多个格式选项,返回所有格式的结果。例如调用`convert('南京市 长江 大桥', fmt=[tm,tn,fl], sc=False)` 返回:
{
'tm': 'nánjīngshì chángjīang dàqiáo'
'tn': 'nan2jing1shi4 chang2jiang1 da4qiao2'
'fl': 'njs cj dq'
}
字典格式没跑通,是用的pycharm中正则匹配的。
假设转拼音服务无法识别“莘”字在下面短语中的读音,当调用`convert('莘庄 立交', fmt=[tn,fl], sc=False, pp=True)
{
'tn': 'xin1zhuang1|shen1zhuang1 li4jiao3'
'fl': 'xz|sz lj'
}
8、调用
```
$ pip install pinyin4py
```
```python
from anjuke import pinyin
converter = pinyin.Converter()
converter.load_word_file('words.txt')
print converter.convert('中华有为',fmt='fl', sc=False, pp=True, fuzzy=0)
print converter.convert('中华有为',fmt='df', sc=False, pp=True, fuzzy=0)
```zhyw
zhonghuayouwei
参考链接:http://www.cnblogs.com/franknihao/p/6541217.html
https://github.com/anjuke/pinyin4py
https://www.cnblogs.com/mypath/articles/5337998.html

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











