









一. CSS的作用
为了让网页元素的样式更加丰富,也为了让网页的内容和样式能拆分开,CSS由此思想而诞生,CSS是 Cascading Style Sheets 的首字母缩写,意思是层叠样式表。有了CSS,html中大部分表现样式的标签就废弃不用了,html只负责文档的结构和内容,表现形式完全交给CSS,html文档变得更加简洁。
二、. 快速复习CSS内容
CSS学习笔记总结(上):https://blog.csdn.net/weixin_40576010/article/details/89743531
CSS学习笔记总结(下):https://blog.csdn.net/weixin_40576010/article/details/89786285
这里讲解一下CSS反爬需要用到的知识:
1.伪元素选择器:伪元素选择器有before和after,它们可以通过样式在元素中插入内容。
.box2:before{content:'行首文字';}
.box3:after{content:'行尾文字';}
2. 关于定位
我们可以使用css的position属性来设置元素的定位类型,position的设置项如下:
| position设置项 | 功能 |
|---|---|
| relative | 生成相对定位元素,元素所占据的文档流的位置保留,元素本身相对自身位置进行偏移 |
| absolute | 生成绝对定位,元脱离文档流,不占据文档流的位置,可以理解为漂浮在文档流的上方,相对于上一个设置了定位的父级元素来进行定位,如果找不到,则相对于body元素进行定位。 |
| fixed | 生成固定定位元素,元素脱离文档流,不占据文档流的位置,可以理解为漂浮在文档流的上方,相对于浏览器窗口进行定位 |
| static | 默认值,没有定位,元素出现在正常的文档流中,相对于取消定位属性或者不设置定位元素 |
| inherit | 从父元素继承position属性的值 |
3. 定位元素的偏移
定位元素还需要用left、right、top或者bottom来设置相对于参照元素的偏移量
三、 这里就一道反爬虫题目来讲解CSS反爬:
页面上显示的数据为:

但html中的数据为:
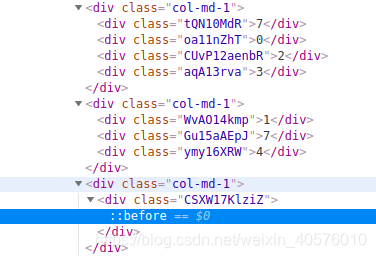
解析:
1. 第一个大div[@class=‘col-md-1’]标签下有4个div标签,该标签对应的数据是320,很明显,text内容是7这个div标签是没有用处的,剩下三个标签顺序打乱。
对于text内容为7的div标签,由于它盒子与盒子之间的间距margin-right=-1em, 也就是跟该标签全部向左移动-1em,所以数据不会显示出来,且不占用文档流的位置。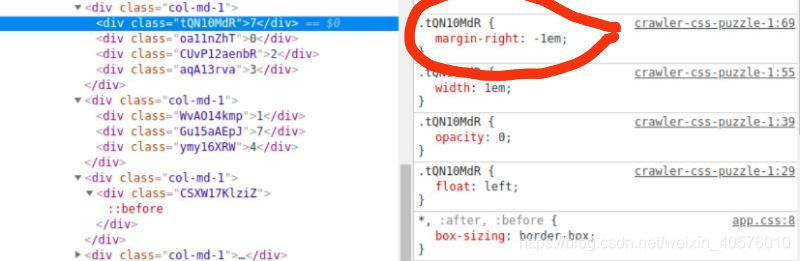
剩下的三个div标签的解析,见下文
2. 第二个大div[@class=‘col-md-1’]标签下有3个div标签,该标签对应的数据417,很明显,这三个div标签只是顺序打乱而已。
这里的标签都是采用左浮动特性,碰到父元素边界、其他元素才停下来, 元素定位采用relative,生成相对定位元素,元素所占据的文档流的位置保留,元素本身相对自身位置进行偏移,所以如果没有设置定义定位偏移量,显示的数据应该是174, 但是每个div标签都设置了left偏移量,我们可以通过分析left偏移量就可以得出正确的数据
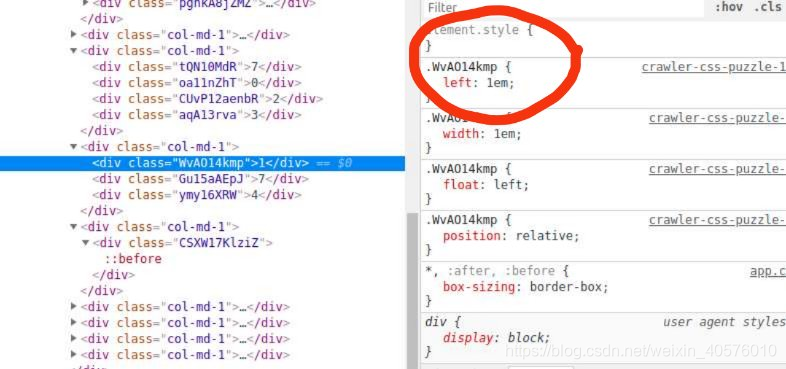
1需要从本来的百位数向右移动一位,也就是1是在十位数的位置
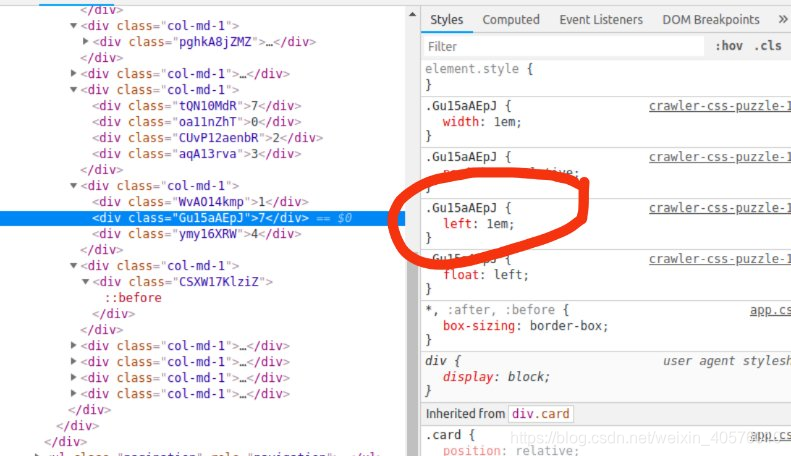
7需要从本来的十位数向右偏移1位,也就是7是在个位数的位置
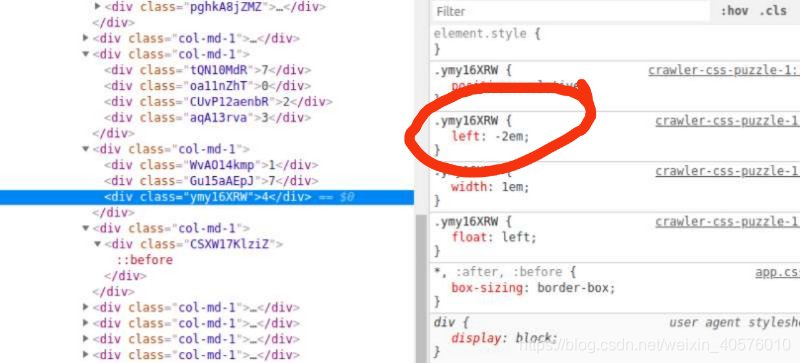
4需要从个位数向左偏移1位数,也就是4是在百位数的位置
综上,便可以得到正确的数据:417
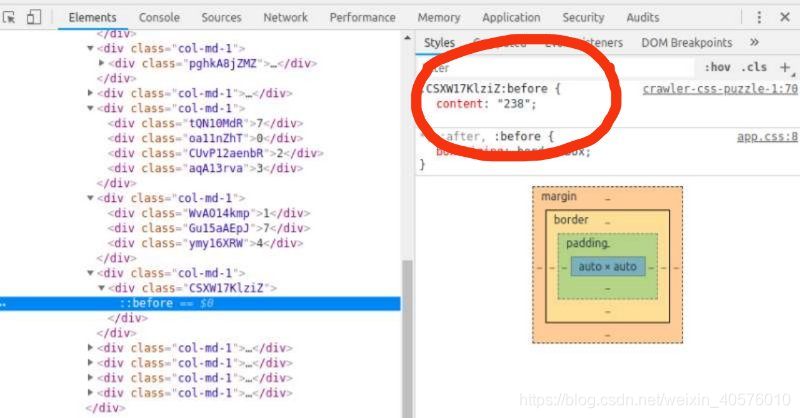
3. 对于最后一个大div[@class=‘col-md-1’]标签,该div标签下没有内嵌div标签,也没有显示数据,这个是使用了before伪元素选择器,可以查看css文件中,该标签:before选择器下的content对应的数据,就是该div标签需要显示出来的数据。
四、核心代码:
def detail_parse(self, div_html, response_str):
"""
分别每组div[@class='col-md-1']进行详细解析,有俩种不同解析,一种只是div标签顺序不正确,另外一种是使用了伪元素选择器
:param div_html: 传进来的div[@class='col-md-1']
:param response_str: 该网页的elements内容,也就是response.text
:return:None
"""
# 获取div[@class='col-md-1']下的所有div标签
div_list = div_html.xpath("./div")
# todo:1.对于div_list长度为3以下的
# 就是使用伪元素选择器
if len(div_list) < 3:
for div in div_list:
text = div.xpath("./text()")
if not text:
class_name = div.xpath("./@class")[0]
num = re.findall(r"\.{}\:before\s*.*?\s*content\:\"(\d*)\"".format(class_name), response_str, re.S)[0]
self.total_num += int(num)
print(num, "总数", self.total_num)
# todo:2.对于div_list长度大于等于3的
# 长度为4就是其中有个div不显示,长度为3就是div标签数据显示顺序打乱
else:
if len(div_list) == 4:
div_list = div_list[1:]
number = [-1, -1, -1]
for i in range(0, len(div_list)):
div = div_list[i]
class_name = div.xpath("./@class")[0]
data = div.xpath("./text()")[0]
left = re.findall(r"\.{}\s.*?\sleft\:(.*?)em".format(class_name), response_str)
if not left:
# 如果left为空,表名位置不需要调整
number[i] = data
# 否则就需要调整位置
else:
index = i + int(left[0])
number[index] = data
num = "".join(number)
self.total_num += int(num)
print(num, "总数", self.total_num)
更多内容:
爬虫验证码:破解【点击旋转验证码】
https://blog.csdn.net/weixin_40576010/article/details/89607998
极验3.0滑验证码破解:selenium+计算滑动缺口坐标算法=80%通过率
https://blog.csdn.net/weixin_40576010/article/details/89255933
Linux下利用jTessBoxEditor工具进行Tesseract样本训练【图】
https://blog.csdn.net/weixin_40576010/article/details/89517946
如何获取大量廉价可靠代理IP地址?https://blog.csdn.net/weixin_40576010/article/details/89507924


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









