







select
检索
-
检索单个列
select 列名 from table_name; # mysql 没有要求必须加分号,但加上没有坏处 # sql语句不区分大小写,一般sql关键字大写,对所有的自己命名小写,便于阅读和理解。所有空格会被忽略,可以在一行,也可以在多行。 -
检索多个列
select 列名1,列名2,。。from table_name; # 除了最后一个列名后不加逗号,其余列名后加逗号。 # sql语句一般返回原始、无格式的数据,这些是表示问题,不是检索问题。 -
检索所有列
select * from table_name; # 返回列的顺序一般都是定义中的顺序,但是表的模式变化可能会导致顺序的变化。 # 如果不是需要所有列,这么检索将会降低检索和程序性能。 -
检索不同的行(结果中行会有重复的)
select distinct 列名 from table_name; # distinct 必须直接放在列名的前边 # 它应用于所有列而不是前置它的列 -
限制结果
# select 返回所有结果,为了返回前几行,使用limit 当行数没有限制的那么多,只返回mysql能返回的那么多。 select 列名 from table_name limit 2; # 还可以限制开始行和行数(检索出来的第一行是行0而不是行1) select 列名 from table_name limit 开始行, 行数; limit 4 offset 3从行3开始去4行 ==》limit 3,4 -
使用完全限定的表名
select table_name.field from db_name.table_name;
排序检索
sql语句由子句构成,有些必须有些可选,子句通常由一个关键字和所提供的数据组成。
-
排序数据(order by 子句取一个或多个列名,对输出排序)
select field from table_name order by field; # 按照field对输出进行 # 通常使用显示所选择的列进行排序,但用非检索的列进行排序也可以。 -
按照多个列排序(默认是升序排序)
# 多个列排序,指定列名,列名之间逗号分开 select field1,field2,field3 from table_name order by field1,field2; # 首先按field1进行排序,再按field2排序 仅在多个行具有相同的field1时,才根据field2排序 如果field1所有值都是唯一的,则不会按照field2进行排序。 -
指定排序方向
# 降序排序只当desc select field from table_name order by field desc; # desc 只应用到直接位于其前面的列名,因此对field1 进行降序排序,对field2进行默认的升序排序 select field1, field2 from table_name order by field1 desc, field2; # 如果对多个列进行指定排序,必须对每个列指定desc关键字 # desc相反的时asc # 在字典排序顺序中,A和a视为相同的,这是mysql的默认行为,但是可以在需要时改变这种行为。 # order by子句必须位于from子句之后,limit必须位于order by子句之后
过滤数据
where子句
# 只检索所需数据指定搜索条件,也就是过滤条件
select field1, field2 from table_name
where field1 = condition;
# sql过滤和应用过滤
# 应用层过滤则需要服务器不得不通过网络发送多余的数据,浪费网络带宽资源,因此对数据库优化,可有效对数据进行过滤。
# 在同时使用where子句和order by子句,order by子句应位于where子句之后。

-
检查单个值
select field1, field2 from table_name where field1 = condition; # mysql在执行匹配时默认不区分大小写 -
不匹配检查
select field1, field2 from table_name where field1 <> condition; # 不等于某个条件的数据 # 将值与字符串类型的列进行比较,需要单引号 与数值列进行比较不用引号 -
范围值检查
# 使用between select field1,field2 from table_name where field1 between 开始值 and 结束值; -
空值检查
# null 无值,与字段包含0、空字符串或者仅仅包含空格不同。 select field2 from user where field1 is null; # 获取field1为null的field2 # null与不匹配 如果希望返回具有null值的行,是不行的,未知具有特殊的含义,数据库不知道是否匹配,所以在匹配过滤或者不匹配过滤时不返回它们。就是如果使用年龄匹配,但是某一列的值为null,无论匹配不匹配过滤都不会返回该行的数据 因此过滤数据时,一定要验证返回数据中,确实给出了过滤列具有null的行
数据过滤
通过and子句或者or子句组合where子句来实现更强的过滤
-
and操作符
select field1,field2,field3 from table_name where field1 = condition and field2 = condition2; # 返回满足所有条件的数据 # 可以使用多个and连接多个where子句 -
or操作符
select field1,field2 from table_name where field1 = condition or field1 = condition2; # 返回满足任一条件的数据 -
计算次序
# where 可以包含任意数目的and和or操作符,两者可结合进行复杂过滤 但是要注意sql语句中and操作符的计算优先级要高于or操作符,可以使用括号来限制优先级 select field1,field2 from table_name where (field1 = condition or field1 = condition2) and field2 = condition3 # 只要有or和and结合,尽量使用圆括号来限制优先级,消除歧义 -
in操作符
# in操作符用来指定条件范围,范围中每个条件都可以匹配,in操作符后跟由逗号分隔的合法值清单 # in在某种意义上可以和or完成相同的功能,in操作符的语法更清楚,计算次序更容易管理,执行比or更快 最大的优点是可以包含其他select语句 select field1,field2 from table_name where field1 in (1,2,n) -
not操作符
# where子句中not操作符有且只有一个功能,就是否定它之后的任何条件 select field1 , field2 from table_name where field1 not in (1,2,n) # mysql 支持使用not对in、between、exists取反 和其他多数dbms允许使用not对各种条件取反不同。用通配符进行过滤
通配符:用来匹配值的一部分的特殊字符
搜索模式:由字面值、通配符或者两者组合构成的搜索条件
在搜索子句中使用通配符,必须使用like操作符,后跟的搜索模式利用通配符而不是直接相等匹配进行比较。
操作符在作为谓词时,不是操作符
-
%通配符
# %表示任何字符出现任意次数 select field1,fiield2 from table_name where field1 like 'sz%'; # 返回field1字段以sz起头的数据 # 根据mysql的配置,注意是否区分大小写 select field1,fiield2 from table_name where field1 like '%sz%'; # 返回field1任意位置包含sz的数据 select field1,fiield2 from table_name where field1 like 's%z'; # 返回field1列以s开头,z结尾的数据 # %通配符可以匹配0、1个或者任意多个字符 结尾处的空格会干扰通配符匹配,看不出来空格,但是实际存在,通常在结尾加上%或者利用函数去掉首尾空格。 # %通配符可以匹配任何字符,但是不能匹配null -
下划线_通配符
# 下划线_只能匹配单个字符而不是多个字符 -
通配符使用技巧
- 能用其他方法搜索数据,不要使用通配符,更耗时
- 除非必要,否则不要把通配符放在搜索模式的开始处
- 仔细注意通配符的位置
正则表达式进行搜索
-
基本字符匹配
select field from table_name where field regexp '100' order by field; # regexp后跟的东西作为正则表达式处理 select field from table_name where field regexp '.00' order by field; .是正则表达式的一个特殊字符,表示匹配任意一个字符 like 和 regexp like匹配的是整个列,即使被匹配的文本在列值中出现,也不会将行返回 regexp在列值内进行匹配,如果被匹配的文本在列值中出现就会被返回。 mysql的正则表达式匹配不区分大小写,为了区分大小写可以在regexp后使用binary关键字 -
进行or匹配
select field from table_name where field regexp '100|200' order by field; # 返回满足任一条件的数据 -
匹配几个字符之一
# 使用[]括起来一组字符完成 select field from table_name where field regexp '[123] Ton' order by field; # 能够匹配 1 Ton或者2 Ton 或者3 Ton # 是另一种方式的or [123] Ton -> 1|2|3 Ton 但是是 1或2或3Ton [^123]匹配除了这些字符以外的任何东西 # 在[]中^ 可以否定后边的条件
-
-
匹配范围
# 使用-来定义一个范围 [1-9] [a-z] select field from table_name where field regexp '[1-5] Ton' order by field; -
匹配特殊字符
# 使用转义\\作为前导 select field from table_name where field regexp '\\.' order by field; 匹配. 其他特殊字符也是如此 \\- # 元字符 \\f -> 换页 \\n -> 换行 \\r -> 回车 \\t -> 制表 \\v -> 纵向制表 \\\ 匹配\ # 多数正则表达式使用单个反斜杠进行转义 mysql使用双反斜杠,mysql解析一个,正则表达式库解析另一个 -
匹配字符类
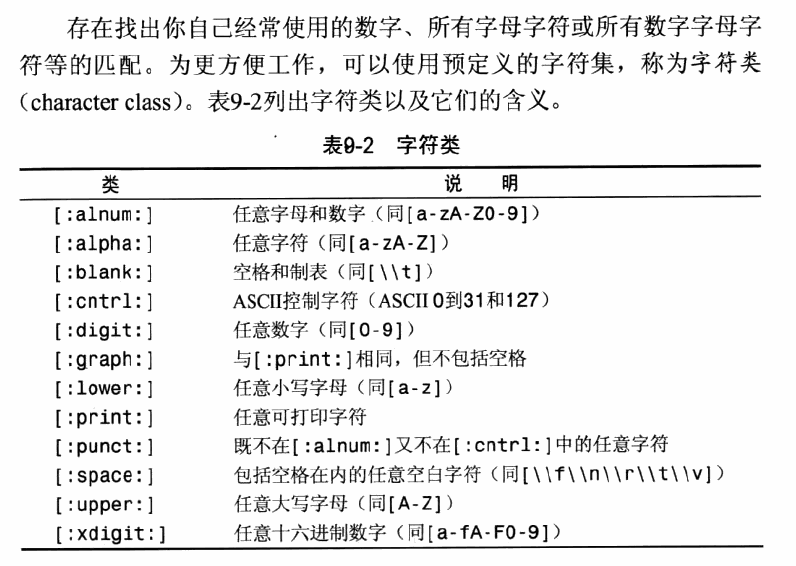
-
匹配多个实例

select field from table_name
where filed regexp '[[:digit:]]{4}'
# 匹配连在一起的四位数字
上下两个情况是等价的
select field from table_name
where filed regexp '[0-9][0-9][0-9][0-9]'
-
定位符
# 定位元字符 ^ 文本的开始 $ 文本的结尾 [[:<:]] 词的开始 # ^在集合中[],用它来否定该集合,或者用来指定串的开始处 # like来匹配整个串,但是 regexp来匹配子串 # 利用^开始每个表达式,用$结束每个表达式,可以用regexp来达到和like同样的效果 # regexp检查总是返回0(没有匹配)1(匹配)创建计算字段
-
计算字段
可以在sql语句完成许多转换和格式化工作,比在客户机完成这些操作要快得多
-
拼接字段
#mysql使用concat来拼接两个列 其他dbms可以使用+或者||来拼接 select concat(field1, ' (',field2,')') from table_name -> field1 (field2) # Trim函数去掉值右边所有空格 # LTrim 函数去掉左边的空格 # 通过as使用别名 select field as new_name-
执行算术计算
# select 后字段可以通过基本算数计算进行运算 运算后最好执行as作为别名 # now()函数返回当前日期和时间
-
使用数据处理函数
SQL函数的可移植性不强,几乎每种DBMS的实现都支持其它实现不支持的函数。所以为了代码的可移植性,尽可能少用函数
- 文本处理函数
# RTrim函数去除列值右边的空格 # LTrim函数去除列值左边的空格 # Upper函数将文本转换成大写 #Left函数返回串左边字符 #Length函数返回串长度 #Locate函数找出串的一个子串 #Lower函数将串转换为小写 #Right返回串右边的字符 #Soundex 返回串的Soundex值 soundex是一个将任何文本转化为描述其语音表示的字母数字模式的算法,考虑了类似的发音字符和音节,使得对串进行发音比较而不是字母比较 select name from table_name where soundex(name) = soundex('Lie') 会匹配发音接近的Lee、lie #SubString函数返回子串的字符-
日期和时间处理函数
# mysql的日期格式是yyyy-mm-dd # Date提取列的日期时间的日期部分和日期匹配 # Date可以保证无论是日期时间还是日期返回的都是日期 # Time则只返回时间部分 # select field from table_name where Year(date) = 2020 and Month(date) = 10 # 获取该月的数据,这样不需要知道2020年9月是几天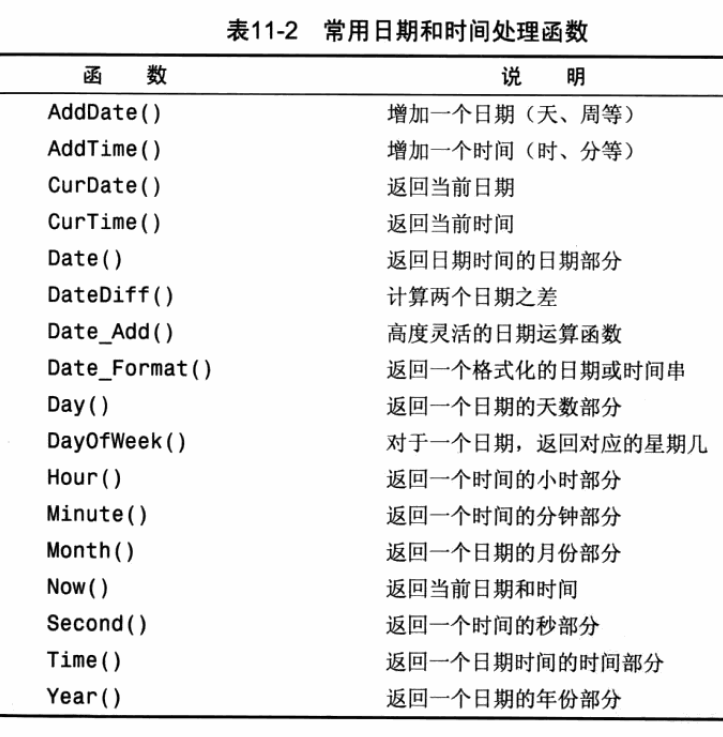
-
数值处理函数

-
汇总数据
聚集函数运行在行组上,计算和返回单个值的函数
# avg() 返回某列(数值列)的平均值,多个列的平均值就需要多个avg()函数,它会忽略列为null的行
count() 返回某列的行数,忽略空值, count(*)对表中的行数进行统计 无论是不是null
max() 返回某列的最大值,如果用于文本数据,如果数据按相应的列排序,返回最后一行,max会忽略null的行
min() 返回某列的最小值
sum() 返回某列值之和,可以计算多个列的和,忽略null
all() 是默认行为,不知地你个distinct 假定就是all
# 各个函数可以组合使用
组合数据
order by子句
可以包含任意数目的列,指定的所有列都一起计算
order by子句中列出的每个列都必须是检索列或者有效的表达式,但不能是聚集函数,如果在select中使用该表达式,必须在group by
内容来自《MySQL必知必会》















 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









