






- 主要参考资料:Stanford University CS236: Deep Generative Models Lec8.
这篇blog基本上是CS236 Lec8的刷课总结/刷课笔记。
VAE
这一节回顾生成模型的一般框架和VAE方法。
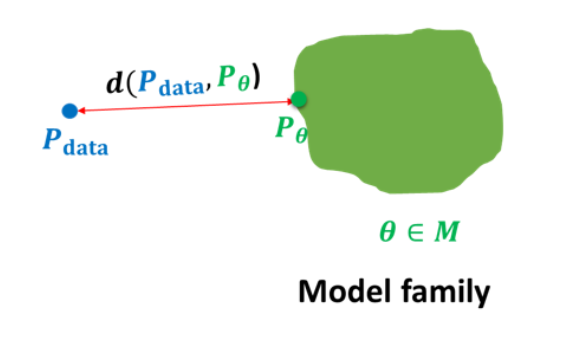
生成模型问题的一般框架,一般有三个组件:
- Pdata P d a t a :数据的真实分布。
- Pθ P θ :由θ θ 参数化的模型族,用于近似真实分布。
- d(Pdata,Pθ) d ( P d a t a , P θ ) :某种衡量“距离”的指标,比如KL散度。
生成模型的训练目标,就是尝试最小化d(Pdata,Pθ) d ( P d a t a , P θ ) 。
下面是VAE的概率图,及其特点:
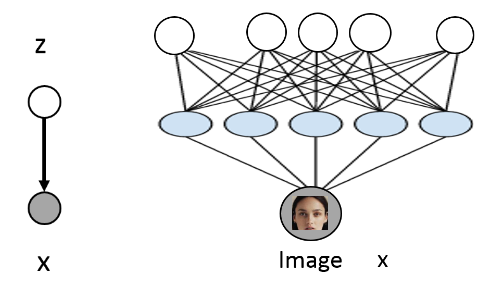
- 是隐变量生成模型。
- 隐变量z z 服从一个简单的先验分布,比如高斯分布.
- 用神经网络建模似然函数p(x∣z;θ)=N(μθ,σθ) p ( x ∣ z ; θ ) = N ( μ θ , σ θ ) ,于是得到Evidence p(x;θ)=∫p(x∣z;θ)p(z)dz p ( x ; θ ) = ∫ p ( x ∣ z ; θ ) p ( z ) d z . 这就是VAE的model family.
- VAE中,衡量距离的指标是KL散度,也就是使用极大似然训练 (最小化KL散度和极大似然学习的关系,可以参见cs236_lecture4.pdf)
应用难点在于:极大似然训练需要max evidence,需要积分,intractable.
VAE中结合了变分推断的方法,近似出了后验概率q(z∣x) q ( z ∣ x ) ,然后就有了Encoder-Decoder的结构xi→q(z;fλ(xi))→z→P(X∣z;θ)→¯xi x i → q ( z ; f λ ( x i ) ) → z → P ( X ∣ z ; θ ) → x ¯ i ,就避免了intractable的积分。
VAE详细内容可以参考我的旧文章:变分推断(VI)、随机梯度变分推断(SGVI/SGVB)、变分自编码器(VAE)串讲 - 伊犁纯流莱 - 博客园;或者参考课程的前几节:Stanford University CS236: Deep Generative Models lec5, 6
Normalizing flow model
有点像VAE。也是隐变量模型,而且在训练的时候也是用KL散度来衡量模型输出分布和真实分布的“距离”。下面就是flow model的概率图。
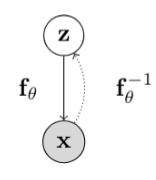
其中z z 仍然服从一个简单分布,满足:
- 和x x 是连续变量,并且具有相同的维度。
- 从到x
x
的变换是一个确定性的可逆变换。假设,Z=f−1θ(X)
Z
=
f
θ
−
1
(
X
)
.
根据以下定理,只需要计算等式右边,很容易就可以计算出evidence:

根据行列式性质,也可以用正映射对应矩阵的Jacobian的行列式:
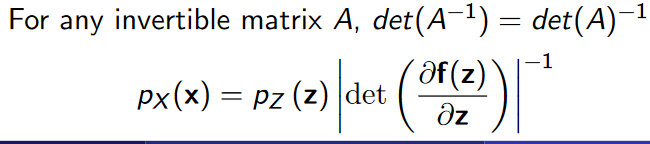
为何右边容易计算?
- pZ p Z 是简单分布,可以直接evaluate。
- 假设映射可逆,所以f−1(x) f − 1 ( x ) 也容易算。
- 暂且假定Jacobian矩阵的行列式也容易计算 (后面会说原因)。
Evidence容易算,就可以很方便使用极大似然学习。这就是flow model的核心思想。
Flow model的学习和推断

- 学习:由于变换可逆,根据change of variable,极大似然学习会很方便。
- 采样/生成:直接从简单分布p(z) p ( z ) 采样,然后变换得到样本。
- 隐变量表示:对数据进行逆变换,得到隐变量表示。
如何构造可逆变换
这一部分解决两个问题:
- 如何构造表示能力足够的可逆变换 (model family足够大),因为我们希望模型pθ(x) p θ ( x ) 足够表示数据原本的分布。
- 计算变换矩阵的Jacobian行列式复杂度O(n3) O ( n 3 ) ,是否可以通过构造可逆变换来简化复杂度。
Flow of transformation
针对第一个问题,可以合成多个结构相同的简单变换,构造一个复杂的可逆变换。实现上就是用多层的网络,每层结构相同、参数不同。
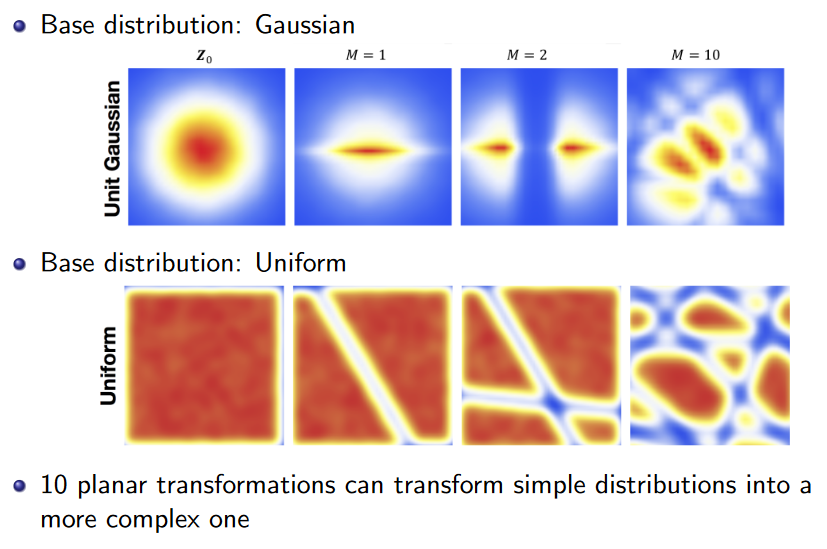
合成之后,计算过程也不难:

- 合成多个结构相同,参数不同的变换。
- 最后行列式计算可以拆成连乘的形式。
Triangular Jacobian
针对第二个问题,可以尝试构造出一个上三角或者下三角形式的变换矩阵,计算行列式就只需要将对角元素相乘,复杂度降低为O(n) O ( n ) 。
假设xi x i 和zi z i 表示第i i 个维度,要构造下三角的可逆变换,我们希望只依赖于z z 的前个维度 (就像自回归模型):

Example
单个层的可逆变换应该如何构造,这一部分简单介绍几种具体的构造方法。
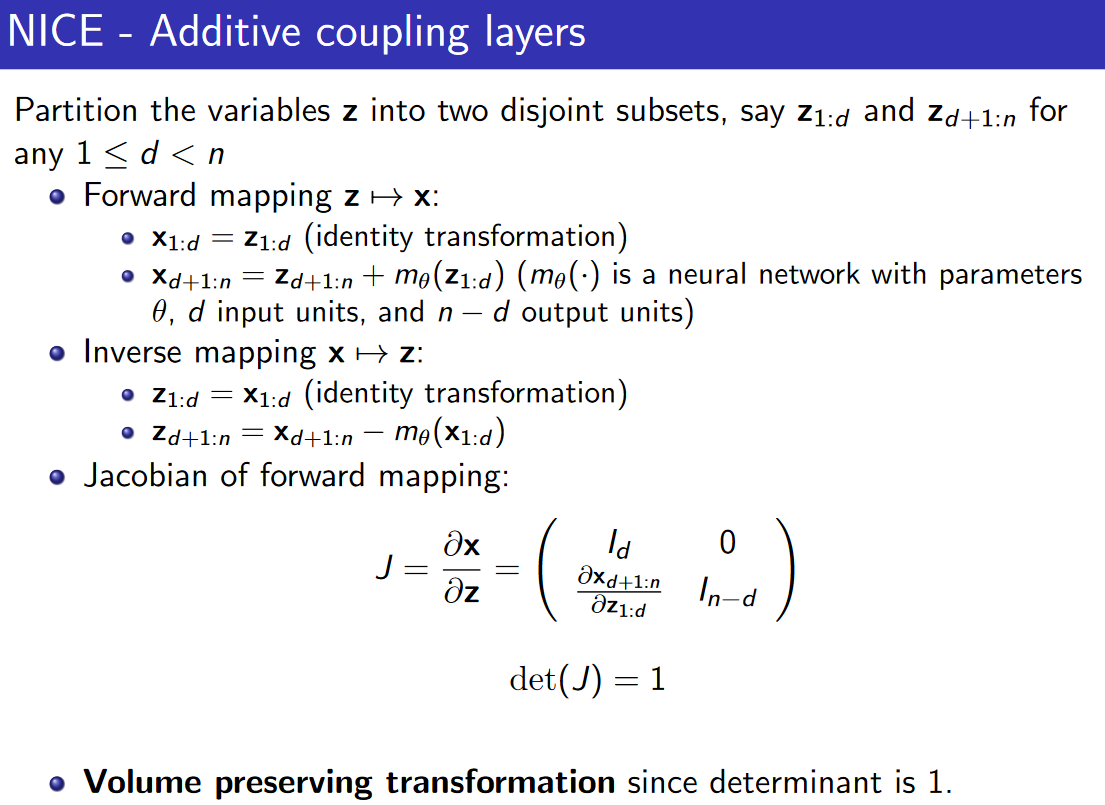
NICE (Nonlinear Independent Components Estimation)
NICE中的可逆变换组成:
- 堆叠的Additive coupling layers
- 最后接的一层Rescaling layers
以下给出了Additive coupling layers和Rescaling layers的细节,很容易就可以看出它们都满足:变换可逆和Jacobian行列式容易计算的特点。

Real-NVP (Non-volume preserving extension of NICE)
相对于NICE,在计算xd+1:n x d + 1 : n 时,隐变量zd+1:n z d + 1 : n 多乘了一个缩放因子。其逆变换和Jacobian行列式仍然容易计算。而且生成效果比NICE好了不少。

MAF (Masked Autoregressive Flow)
考虑一个高斯自回归模型(根据链式法则,按照某个顺序对p(x) p ( x ) 进行因子分解),假定每个因子对应的概率分布都用高斯分布建模,高斯分布的均值和方差都用神经网络建模。
Remark:理解自回归模型的一个简单例子。把一张图片的每个像素看作是xi x i ,每个像素的分布都可以由之前出现过的像素推断出来,对应链式法则的每个因子p(xi∣x<i)=N(μi(x<i),σ2i(x<i)) p ( x i ∣ x < i ) = N ( μ i ( x < i ) , σ i 2 ( x < i ) ) .
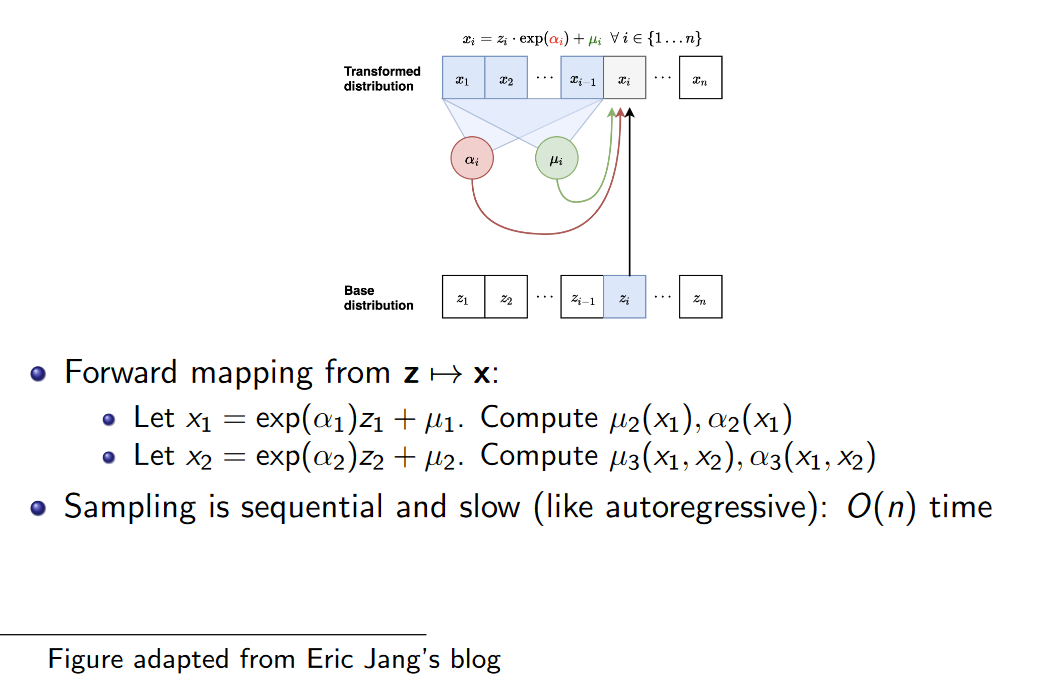
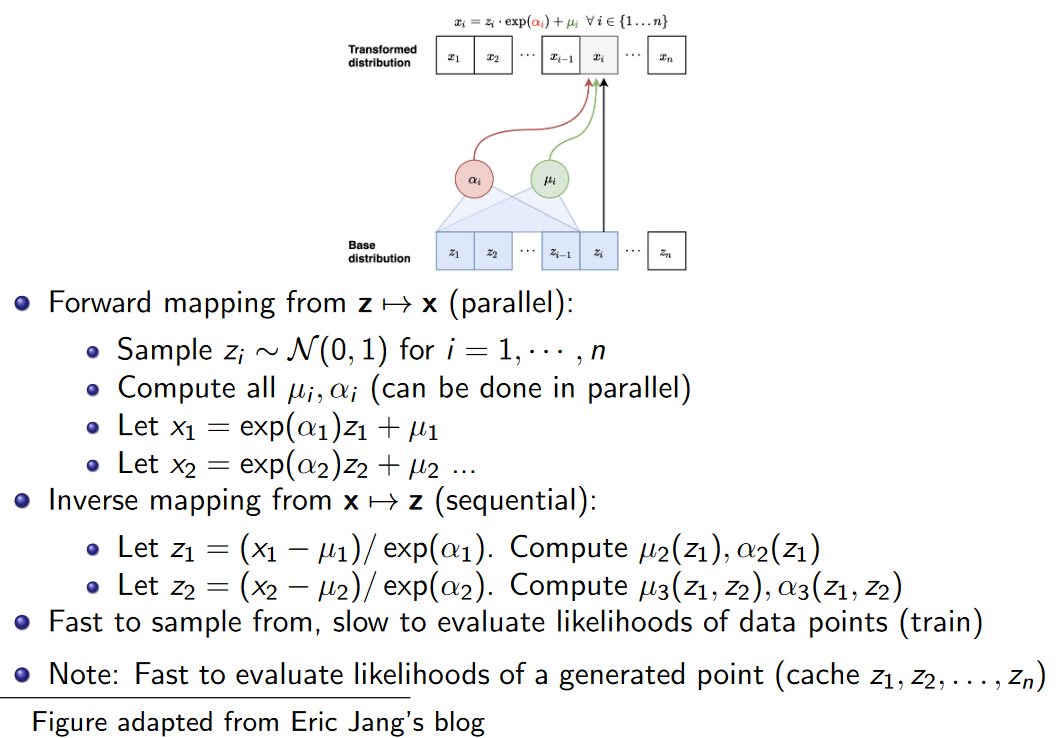
从自回归模型采样的过程,总体上可以看作是从服从简单分布的隐变量z z 变换到的过程。具体来说,就是将以下两个步骤当做整体来看:
- 简单分布采样:先从N(0,1) N ( 0 , 1 ) 中采样出z1...n z 1... n .
- 链式生成:对于每个xi x i ,根据重参数化技巧有xi=exp(αi)zi+μi x i = exp ( α i ) z i + μ i ,然后在通过神经网络计算xi+1 x i + 1 的均值和方差,即μi+1(x<i) μ i + 1 ( x < i ) 和αi+1(x<i) α i + 1 ( x < i ) 。直到生成整个x x 。
这就是自回归模型 as 流模型的思想。可以结合ppt食用。

MAF的正变换过程,因为需要序列生成,所以速度会慢一些。
- MAF的逆变换过程可以并行进行,比如使用MADE。也就是说,计算很快,根据change of variable,计算p(x) p ( x ) 也快,所以做极大似然训练也较快。(这里的"快"都是相对于后面讲的IAF)
- 另外,因为是自回归模型,Jacobian天然就是三角形的,容易计算行列式。
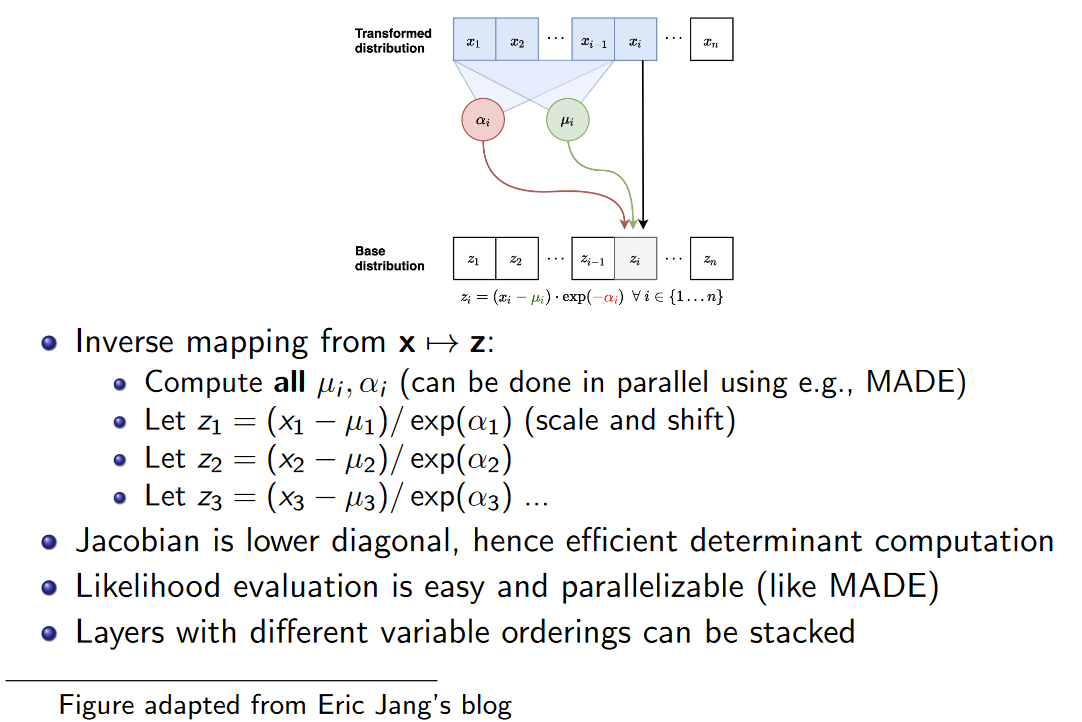
Remark:MADE在这门课Stanford University CS236: Deep Generative Models的lec 3有介绍,在这里就只需要知道:输入x1...n x 1... n 之后,MADE能够并行计算出自回归模型每个因子对应高斯分布的均值和方差就行。
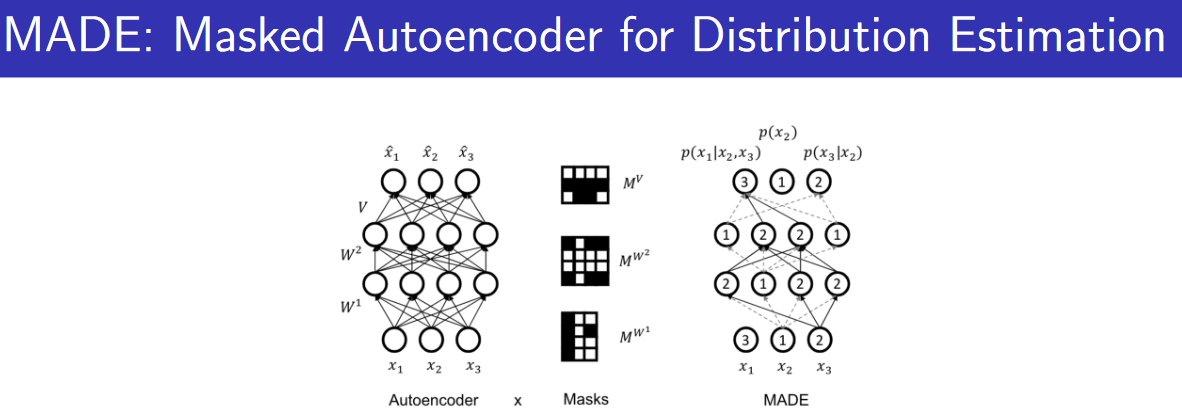
IAF (Inverse Autoregressive Flow)
再考虑自回归模型,只不过这次认为隐变量z z 是自回归而且需要序列生成的,这样就得到了IAF。
IAF特点和MAF恰好相反。
- 正变换()可以并行进行,也就是说模型生成样本的速度是较快的。
- 逆变换(x→z x → z )需要序列生成,也就是说要计算p(x) p ( x ) 比较慢,训练会较慢。
- 值得注意的一点是,如果样本^x
x
^
是由IAF自己生成的 (而不是来自真实分布),由于我们可以把生成^x
x
^
用的采样z
z
记录下来,所以逆变换可以并行进行,就较快了。
Parallel Wavenet
博主博主,这个MAF和IAF确实不错,但缺点还是太明显了,有没有训练和生成样本速度都快的自回归流模型推荐一下嘛?有的有的,Parallel wavenet。
Parallel wavenet结合了MAF和IAF的优势,概括来说就是:
- MAF训练快,就直接训练MAF模型,但是不用它来做生成,而是把它作为训练IAF的教师模型。
- 前面说IAF对自己生成的样本^x x ^ 做逆变换的速度较快,于是利用这一点,设计了新的loss DKL(IAF,MAF)=Ex∼s[logIAF(x)−logMAF(x)] D K L ( I A F , M A F ) = E x ∼ s [ log I A F ( x ) − log M A F ( x ) ] 。使用训练好的教师模型MAF,再结合这个loss来训练IAF,避免了IAF对真实分布的样本x x 做逆变换 (需要序列进行的慢速操作)。
- 最后做样本生成的时候,上IAF就可以了。
详情食用ppt。


MintNet
一种利用掩码卷积来构造可逆分布的方法,略。详情参考课程。

Gaussianization Flows
我们之前训练流模型的思路,都是最小化真实分布和模型表示分布的KL散度,是还有另一种角度。根据下面的推导,我们可以知道,只要让真实样本点经过逆变换之后,得到的样本分布接近高斯分布 (即我们假定的隐变量简单先验分布),同样可以达到训练的目标。
所以问题转化成了,如何设计一个可逆的变换,使得真实数据的分布经过变换之后,能够变成高斯分布。

考虑只有一维的样本,利用两次inverse CDF trick,就可以得到能够高斯化数据的变换。

Remark:inverse CDF是一种从分布中采样的方法(和重要性采样、拒绝采样是一类东西),表达式如ppt所示,就是。从CDF图上来思考,就是在y轴上 (范围是[0,1] [ 0 , 1 ] )随机取一个点,然后平行往右对应到曲线上的一点,再竖直往下对应到x轴上一点,这个点就是采到的样本。
但是对于多维的样本来说,每个维度各自是高斯分布不代表联合分布是高斯分布。
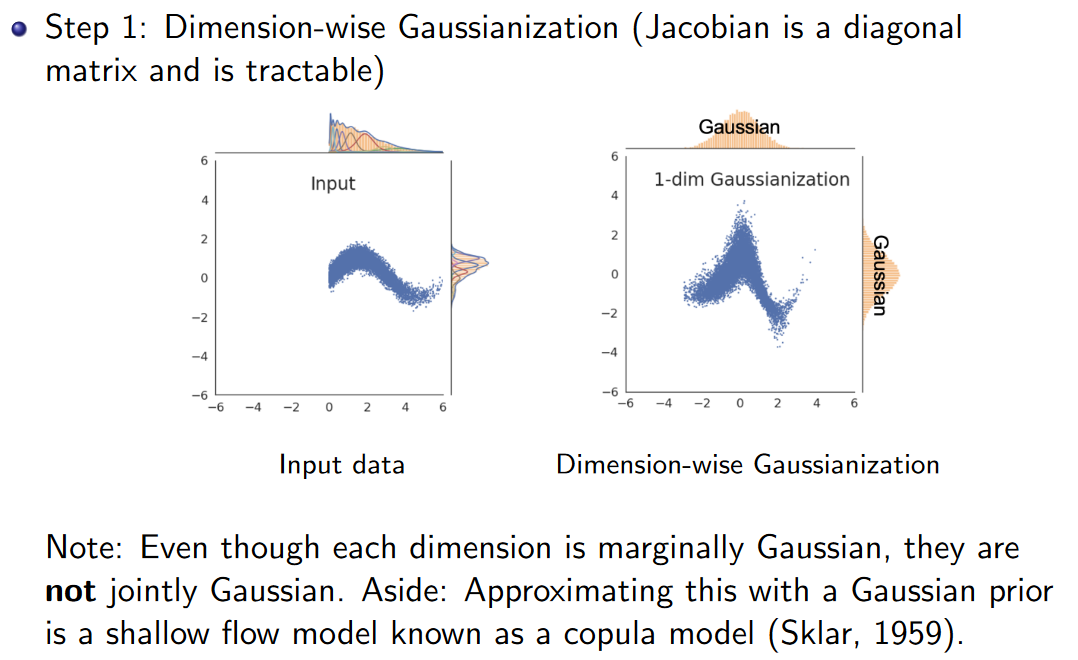
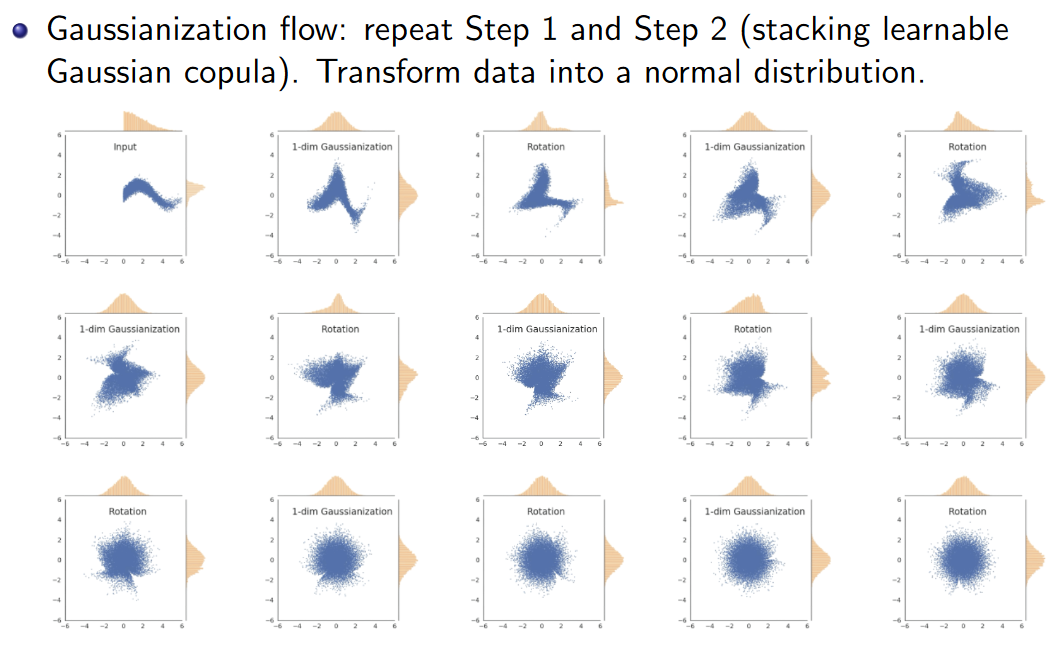
于是在高斯化之后,还需要加入旋转变换。
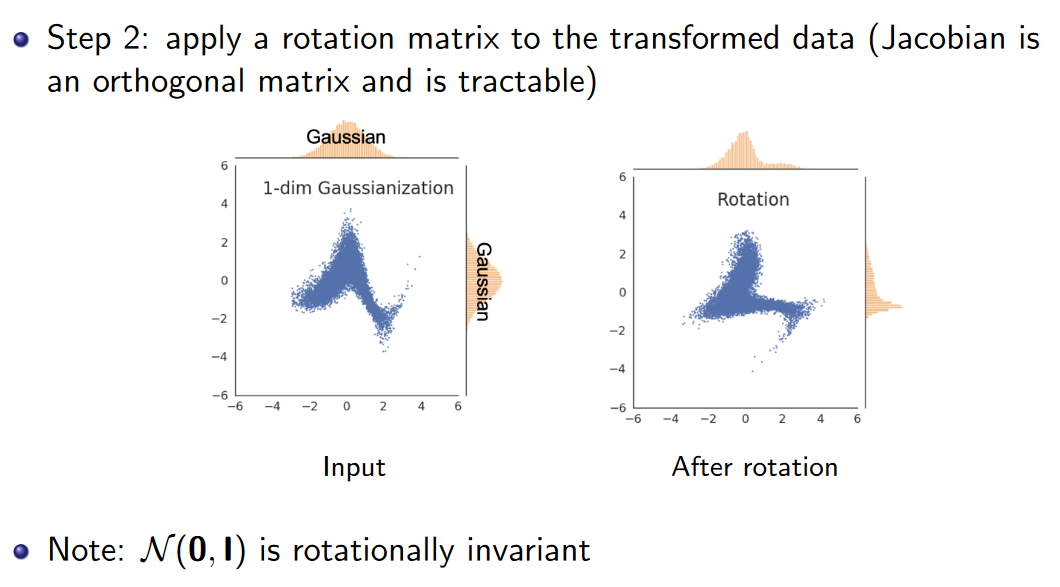
重复高斯化和旋转两个操作 (多个简单可逆变换合并成一个复杂的可逆变换),最终可以把数据高斯化。
原创作者: tshaaa 转载于: https://www.cnblogs.com/tshaaa/p/18734925


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









