







文章目录
Abstract
- 跨域行人重识别中一个popular的方法:聚类后为目标域上行人分配标签。但该方法会引入noisy labels,直接将置信度较低的样本丢弃将降低模型的泛化能力。
- 本文试图在聚类后加入一个样本过滤的过程,更有效地利用所有样本。
- 设计了一个非对称地协作网络,其中一个模型用于接收尽可能pure地样本,另一个模型尽可能保证训练样本的多样性。最终达到训练样本clean and miscellaneous。
1 Introduction
解决行人重识别中无监督域适应问题的两个方向:
- 分布对齐(distribution aligning):减小域之间的分布差异
- 目标伪标签挖掘(target pseudo label discovering):利用目标样本之间的潜在关系,为其预测标签用于模型的再训练
通常采用聚类的方法为目标域样本分配标签,该方法有两个弊端:
- 聚类准确性无法保证,预测出的标签存在噪声干扰
- 大多数聚类方法将置信度较低的样本丢弃,降低了用于再训练的样本多样性
Co-Teaching(CT) 是一种常用于训练有噪声标签的样本的算法,它同时学习两个网络,训练过程中两个网络将损失较低的样本互相喂给对方。但现有CT方法采用对称输入,无法有效运用到跨域行人重识别聚类方法中。这是因为低置信度的样本往往在训练中具有较大的损失,如果采用对称输入会使得网络总是只选择easy samples而忽略了置信度低的样本。
因此本文提出一种非对称的co-teaching框架,先通过聚类将目标域样本分成inliers和outliers。然后用一个网络(main model)从inliers中选出损失小的样本,另一个网络(collaborator model)从outliers中选出损失小的样本。

2 Related Work
2.1 Cross-Domain Person Re-identification
Distribution aligning:
-
image-level (GAN等)无法保证生成图像的身份标签,生成图与真实图仍存在large gap。
-
attribute-level(MMD/TJ-AIDJ…)需要为源域数据进行属性标注,实际操作较难
Clustering-based adaptation:(例如k平均) -
很难确定正确的k值
-
忽视了标签错误的样本
2.2 Learning with Noisy Labels
Training deep model on noisy dataset:
- Transition matrix 获取噪声标签和真实标签之间的转换关系,不适用于大范围的数据集
- robust loss function 在应用上具有一定的限制
- CleanNet 为训练集中的样本分配不同权重,给噪声样本较低的权重从而消除它们的负面影响。缺点:初始化时需要干净的样本
3 The Proposed Method
3.1 Overview
三个阶段:(1)source model training(2)clustering-based adaptation(3)asymmetric co-teaching for adaptation
3.2 Source Model Training
利用源域数据集 S S S,通过交叉熵损失和三元组损失训练一个源模型 M s r c M_{src} Msrc,该模型在迁移时具有基本的判别性。
3.3 Clustering-based Adaptation
用
M
s
r
c
M_{src}
Msrc对目标域上的样本提取池化层第五层的特征,并根据DBSCAN的聚类结果将
T
T
T分成inliers
T
i
T_i
Ti和outliers
T
o
T_o
To。
Distance metric for clustering
k-reciprocal和Jaccard距离用于聚类的距离度量。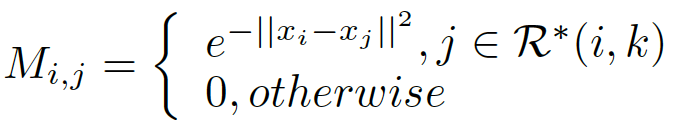
M
i
,
j
M_{i,j}
Mi,j表示样本i和j的特征相似度,
R
∗
(
i
,
k
)
R^*(i,k)
R∗(i,k)表示样本i的k-reciprocal set1。得到相似度矩阵后,计算Jaccard距离: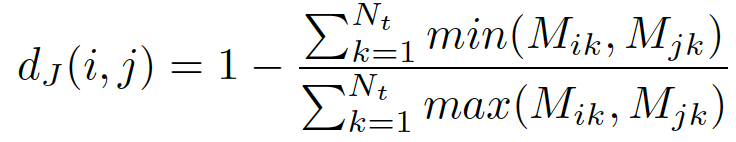
N
t
N_t
Nt表示目标训练数据集中全部图像数。
同时使每个目标特征都与部分源特征靠近:2

N
s
(
x
i
)
N_s(x_i)
Ns(xi)是源域中离目标域中图像i最近的集合。
最终的聚类距离度量由下式计算: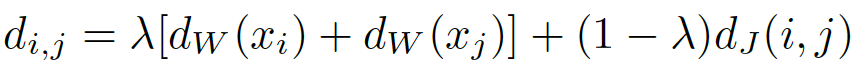
Loss function
通过计算出的距离矩阵M,采用DBSCAN将 g无标签的目标数据集分成
T
i
T_i
Ti和
T
o
T_o
To,用打上标签的
T
i
T_i
Ti fine-tune
M
s
r
c
M_{src}
Msrc。fine-tune时仅使用triplet loss,特征采用pooling-5和fc-2048。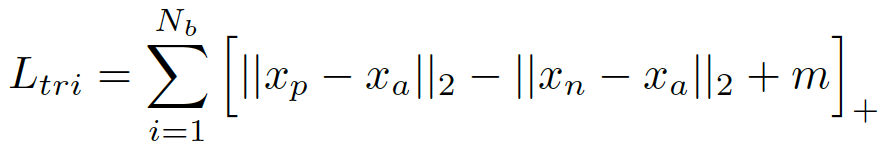
fine-tune和clustering交替迭代,最终得到模型
M
a
d
a
M_{ada}
Mada。
3.4 Asymmetric Co-Teaching for Adaptation
原始的co-teaching方法弊端:
- 被挑选出的损失小的样本都是更容易学习的样本,对提升re-id准确率效果不大
- 损失大的样本在训练过程中很难被考虑,从而降低了训练样本的多样性
因此容易陷入局部优化。
asymmetric co-teaching流程:先用 M a d a M_{ada} Mada初始化main model M m a i n M_{main} Mmain和collaborator model M c o M_{co} Mco, M c o M_{co} Mco用于从outliers中挑出损失小的样本给 M m a i n M_{main} Mmain训练,使 M m a i n M_{main} Mmain的再训练具有多样性。 M m a i n M_{main} Mmain用于从inliers中挑出损失小的样本给 M c o M_{co} Mco训练,使 M c o M_{co} Mco的再训练具有判别性(即具备从outliers中挑出pure samples的能力)。
Step 1: Inliers/Outliers Generation
用
M
a
d
a
M_{ada}
Mada初始化main model
M
m
a
i
n
M_{main}
Mmain和collaborator model
M
c
o
M_{co}
Mco,对所有无标签的目标图像提取pooling-5特征。采用DBSCAN聚类方法,为密度大的区域打上标签,密度小的区域作为
T
o
T_o
To。
Step2: Asymmetric Co-Teaching
(a)
M
m
a
i
n
M_{main}
Mmain的训练:从
T
o
T_o
To中挑选出
B
s
B_s
Bs个样本出来构造相应的三元组,用
M
c
o
M_{co}
Mco计算这些样本的三元组损失,选择具有较小损失的前K%个anchors作为clean samples,将这些挑选出的anchors和另外从
T
i
T_i
Ti中选出的
B
s
B_s
Bs个样本作为一个训练的mini-batch来对
M
m
a
i
n
M_{main}
Mmain进行fine-tune,使
M
m
a
i
n
M_{main}
Mmain尽可能的接收具有多样性的样本。
(b)
M
c
o
M_{co}
Mco的训练:从
T
i
T_i
Ti中选出的
B
s
B_s
Bs个样本,然后用(a)中得到的模型
M
m
a
i
n
M_{main}
Mmain来从样本中挑选出损失较小的用于优化
M
c
o
M_{co}
Mco。此部分
M
m
a
i
n
M_{main}
Mmain主要是为了保证用于训练
M
c
o
M_{co}
Mco的样本尽可能的pure,从而对
M
c
o
M_{co}
Mco用于挑选pure samples时具有基本的判别性。
训练过程中两个step交替进行,以训练好的
M
m
a
i
n
M_{main}
Mmain作为最终模型。

4 Experiment
与现有方法比较

小损失样本的可视化

从图中能看出大多数outliers具有high variance,从中挑选出损失较小的 样本具有一定的可靠度,能增添训练
M
m
a
i
n
M_{main}
Mmain时的多样性。
Ablation Study
考察三个方面:
(1) the necessity of taking
T
o
T_o
To into training process
实验中直接将
T
o
T_o
To用于训练,比起baseline有提升,但由于噪声标签提升很微弱
(2) the necessity of clean noisy labels
采用co-teaching和改良的co-teaching消除噪声影响,仍旧具有较小的提升
(3) the effectiveness of asymmetric structure
本文方法具有更好的效果
下图表示了(2)中提到的co-teaching和改良的co-teaching的差异:
Variant Evaluation
How much difference between the main model and the collaborator model?
main model和collaborator model之间差距多大?
main model的准确率总是高于collaborator model,这是由于collaborator model仅仅只训练easy samples,不具有样本多样性。
Whether the clustering accuracy increase along with the training iteration?
聚类准确度是否随着训练迭代次数的增加而增加?
用f-score来评估聚类的准确度,下面左图表示迭代次数增大时f-score的值也随着增大,右图表示迭代次数增大时
T
o
T_o
To中图像数量减少,这体现了asymmetric co-teaching对cross-domain re-id的积极作用。

Is the proposed pipeline compatible with other clustering methods?
所提方法流程是否与其它聚类方法兼容?

将DBSCAN换成k-means聚类,由于k-means无法直接生成outliers,实验中选取距离聚类中心最远的20%/30%作为outliers。
上表表明用k-means与ACT结合也能比单纯k-means准确率高,体现来ACT与其他聚类方法的兼容性。















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









