









 本文详细介绍了如何使用Flume将目录中的文件内容采集并上传到HDFS。配置包括Spooling Directory Source监控目录,File Channel确保数据不丢失,以及HDFSSink指定存储路径。在配置过程中,遇到了ClassNotFoundException和No FileSystem for scheme: hdfs的问题,通过将节点设置为Hadoop客户端节点并更新环境变量解决。最后,验证了Flume成功将文件内容写入HDFS,并讨论了文件命名和状态管理。
本文详细介绍了如何使用Flume将目录中的文件内容采集并上传到HDFS。配置包括Spooling Directory Source监控目录,File Channel确保数据不丢失,以及HDFSSink指定存储路径。在配置过程中,遇到了ClassNotFoundException和No FileSystem for scheme: hdfs的问题,通过将节点设置为Hadoop客户端节点并更新环境变量解决。最后,验证了Flume成功将文件内容写入HDFS,并讨论了文件命名和状态管理。
案例:采集文件内容上传至HDFS
接下来我们来看一个工作中的典型案例:
采集文件内容上传至HDFS
需求:采集目录中已有的文件内容,存储到HDFS
分析:source是要基于目录的,channel建议使用file,可以保证不丢数据,sink使用hdfs
下面要做的就是配置Agent了,可以把example.conf拿过来修改一下,新的文件名为file-to-hdfs.conf
首先是基于目录的source,咱们前面说过,Spooling Directory Source可以实现目录监控
来看一下这个Spooling Directory Source
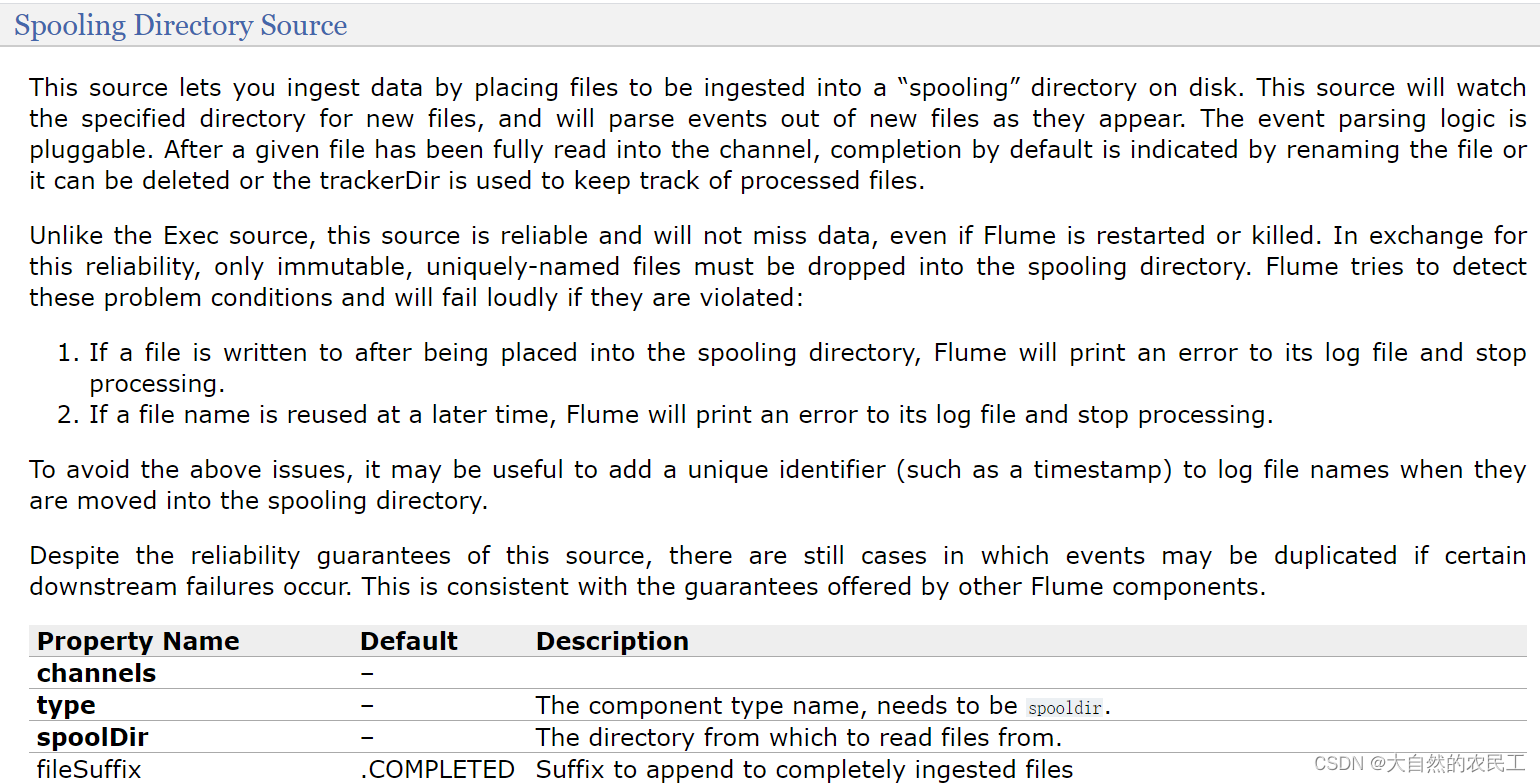
channels和type肯定是必填的,还有一个是spoolDir,就是指定一个监控的目录
看他下面的案例,里面还多指定了一个fileHeader,这个我们暂时也用不到,后面等我们讲了Event之后大家就知道这个fileHeader可以干什么了,先记着有这个事把。
那来配置一下source
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1876
1876






 到【灌水乐园】发言
到【灌水乐园】发言









