







一、列族高级设置
1、生存时间(TTL)
应用系统经常需要从数据库里删除老数据,配置此项,可使数据增加生命周期,超过该配置时间的数据,将会在大合并时“被删除”。(单位:秒)
create 't3', {NAME => 'cf1', TTL => '18000'}
desc 't3'


2、版本数
在0.96的版本之前默认每个列族是3个version, 0.96之后每个列族是1个version,在大合并时,会遗弃过期的版本。
create 't4', {NAME => 'cf1', VERSIONS => 3}
desc 't4'

3、压缩
HFile可以被压缩并存放在HDFS上。这有助于节省硬盘IO,但是读写数据时压缩和解压缩会抬高CPU利用率。
压缩是表定义的一部分,可以在建表或修改表结构时设定。建议打开表的压缩,除非你确定不会从压缩中受益。
只有在数据不能被压缩或者因为某种原因服务器的CPU利用率有限制要求的情况下,有可能会关闭压缩特性。
HBase可以使用多种压缩编码,包括LZO、SNAPPY和GZIP
create 't5',{NAME => 'cf1', COMPRESSION => 'SNAPPY'}
desc 't5'

4、数据块(BLOCKSIZE)大小的配置
随机查询:数据块越小,索引越大,查找性能更好
顺序查询:更好的顺序扫描,需要更大的数据块
所以在使用的时候根据业务需求来判断是随机查询需求多还是顺序查询需求多,根据具体的场景而定。
create 't6',{NAME => 'cf1', BLOCKSIZE => '65537'}
desc 't6'

5、数据块缓存
如果一张表或表里的某个列族只被顺序化扫描访问或者很少被访问,这个时候就算Get或Scan花费时间是否有点儿长,你也不会很在意。
在这种情况下,你可以选择关闭那些列族的缓存。
如果你只是执行很多顺序化扫描,你会多次倒腾缓存,并且可能会滥用缓存把应该放进缓存获得性能提升的数据给排挤出去。
如果关闭缓存,不仅可以避免上述情况发生,而且还可以让出更多缓存给其他表和同一个表的其他列族使用。
create 't7',{NAME => 'cf1', BLOCKCACHE => 'false'}
desc 't7'

6、布隆过滤器(Bloom filters)
HBase中存储额外的索引层次会占用额外的空间。布隆过滤器随着它们的索引对象的数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。
当空间不是问题的时候,它们可以帮助你榨干系统的性能潜力。
BLOOMFILTER参数的默认值是ROW,表示是行级布隆过滤器。
使用行级布隆过滤器需要设置为ROW,使用列标识符级布隆过滤器需要设置为ROWCOL。
行级布隆过滤器在数据块里检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。
ROWCOL布隆过滤器的开销要高于ROW布隆过滤器。
create 't8',{NAME => 'cf1', BLOOMFILTER => 'ROWCOL'}
desc 't8'

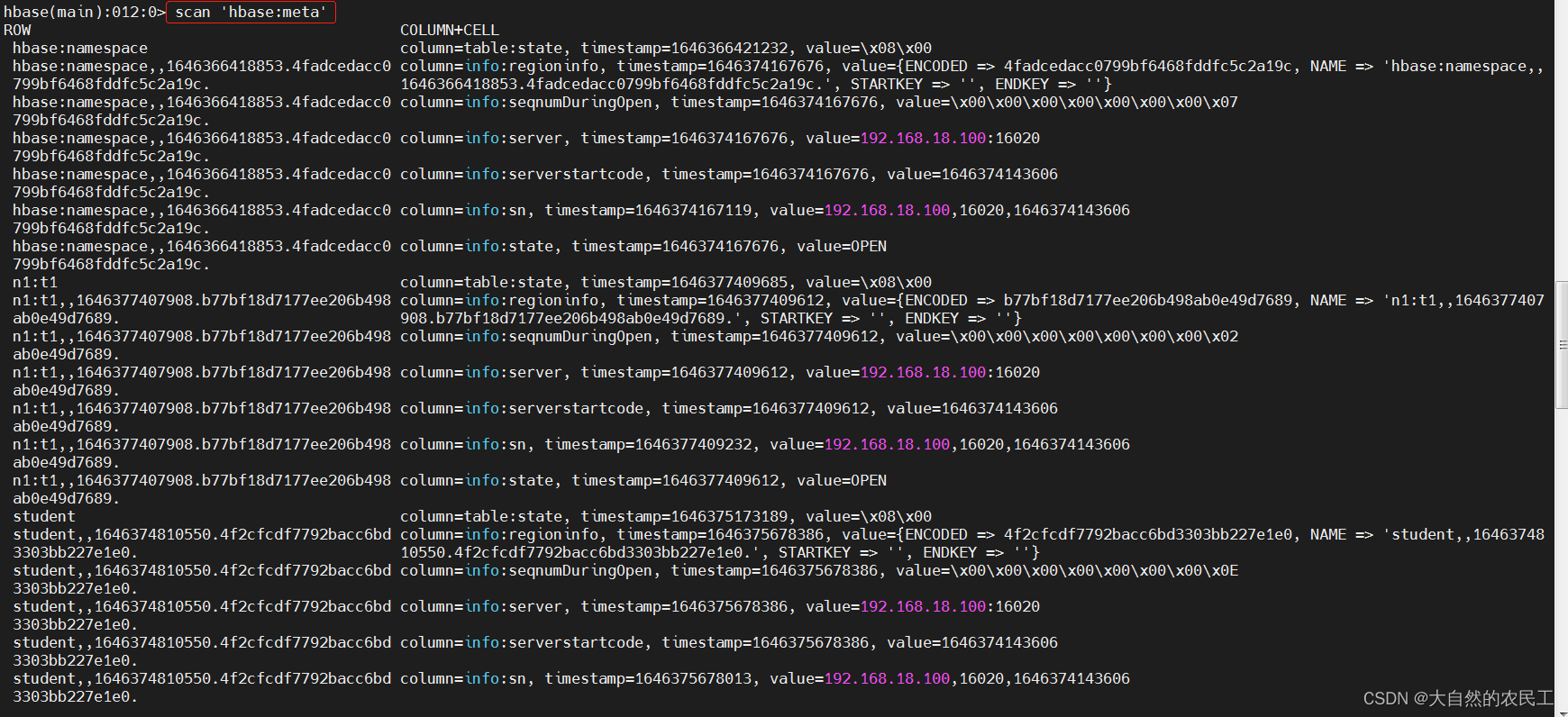
7、Scan (全表扫描)
HBase中的Scan操作,类似于SQL中的select * from …
例子:
scan 'hbase:meta'
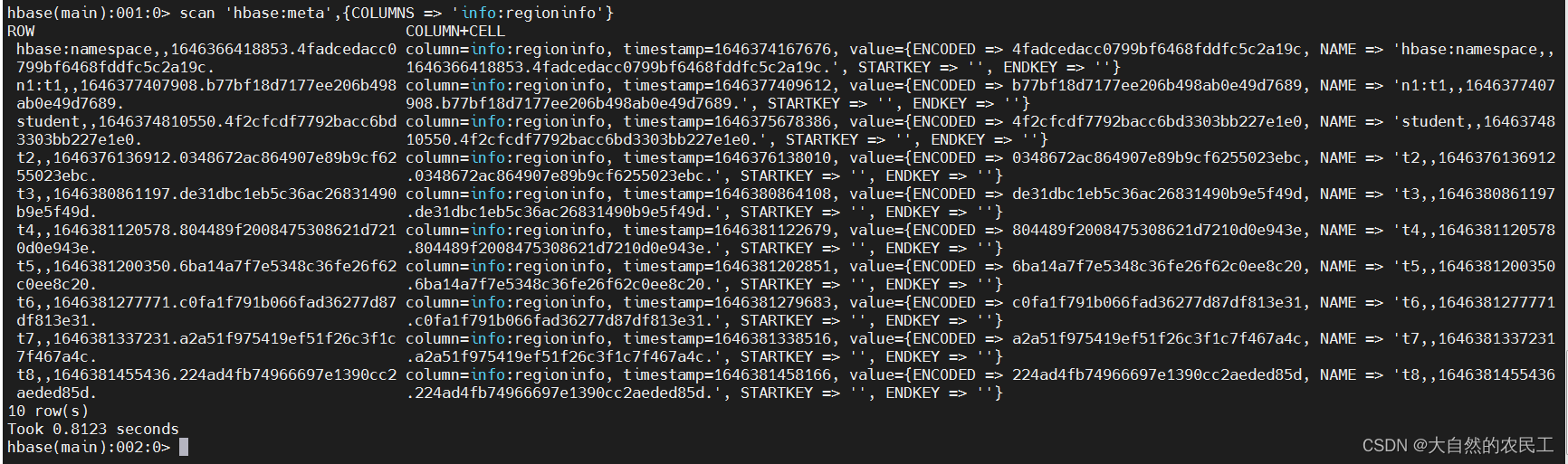
scan 'hbase:meta',{COLUMNS => 'info:regioninfo'}
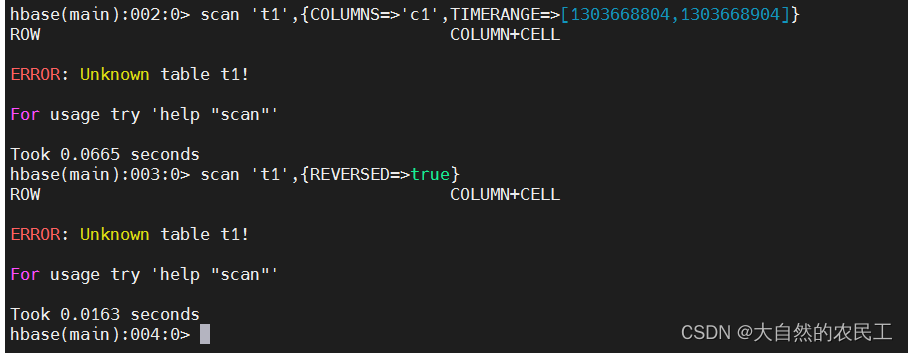
scan 't1',{COLUMNS=>'c1',TIMERANGE=>[1303668804,1303668904]}
scan 't1',{REVERSED=>true}
二、Scan的Java API用法
1、Scan 在Java API中支持以下用法:
scan.addFamily(); //指定列族
scan.addColumn(); //指定列,如果没有调用任何addFamily或Column,会返回所有的columns;
scan.readAllVersions(); //读取所有版本数据。
scan.readVersions(3); //读取最新3个版本的数据
scan.setTimeRange(); //指定最大的时间戳和最小的时间戳,只有在此范围内的cell才能被获取.
scan.setTimeStamp(); //指定时间戳
scan.setFilter(); //指定Filter来过滤掉不需要的信息
scan.withStartRow(); //指定开始的行。如果不指定,则从表头开始
scan.withStopRow(); //指定结束的行(不含此行)
scan.setBatch(); //指定最多返回的Cell数目。用于防止一行中有过多的数据,导致OutofMemory错误。
scan.setCaching(); //指定scan底层每次连接返回的数据条数,默认值为1,适当调大可以提高查询性能,设置太大会比较耗内存
2、常见的Filter
在进行Scan的时候,可以添加Filter实现数据过滤
(1)RowFilter:对Rowkey进行过滤。
//小于等于 x
Filter filter = new RowFilter(CompareOperator.LESS_OR_EQUAL,new BinaryComparator(Bytes.toBytes(“x”)));
//正则 以x结尾
Filter filter = new RowFilter(CompareOperator.EQUAL,new RegexStringComparator(".*x"));
//包含 x
Filter filter = new RowFilter(CompareOperator.EQUAL, new SubstringComparator(“x”));
//开头 x
Filter filter = new RowFilter(CompareOperator.EQUAL, new BinaryPrefixComparator(Bytes.toBytes(“x”)));
CompareOperator.其他比较参数
LESS 小于
LESS_OR_EQUAL 小于等于
EQUAL 等于
NOT_EQUAL 不等于
GREATER_OR_EQUAL 大于等于
GREATER 大于
NO_OP 排除所有
(2)PrefixFilter
筛选出具有特定前缀的行键的数据。
Filter pf = new PrefixFilter(Bytes.toBytes(“前缀”));
(3)ValueFilter
按照具体的值来筛选列中的数据,这会把一行中值不能满足的列过滤掉
Filter vf = new ValueFilter(CompareOperator.EQUAL, new SubstringComparator(“ROW2_QUAL1”));















 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











