







一、什么是Spark
Spark是一个用于大规模数据处理的统一计算引擎。
注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,等等,所以说它是一个统一的计算引擎。
既然说到了Spark,那就不得不提一下Spark里面最重要的一个特性:内存计算。
Spark中一个最重要的特性就是基于内存进行计算,从而让它的计算速度可以达到MapReduce的几十倍甚至上百倍。
所以说在这大家要知道,Spark是一个基于内存的计算引擎。
二、Spark的特点
接下来看一下Spark的一些特点
1、Speed:速度快
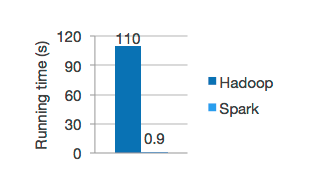
由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍。
Spark使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了高性能的批处理和流处理。
注意:批处理其实就是离线计算,流处理就是实时计算,只是说法不一样罢了,意思是一样的。
2、Easy of Use:易用性

Spark的易用性主要体现在两个方面:

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 8223
8223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











