







在编程语言的世界中,编译器(如 GCC、TypeScript)和转译器(如 Babel)扮演着至关重要的角色,它们负责将人类可读的代码转换为机器或其他语言可执行的指令。这一过程通常分为四个关键阶段:
1. 词法分析:将源代码拆解成基本单元(Token);
2. 语法分析:根据语法规则构建抽象语法树(AST);
3. 代码转换:对 AST 进行优化或转换(如ES6 =>ES5);
4. 代码生成:将 AST 还原为目标代码(如JavaScript、机器码);
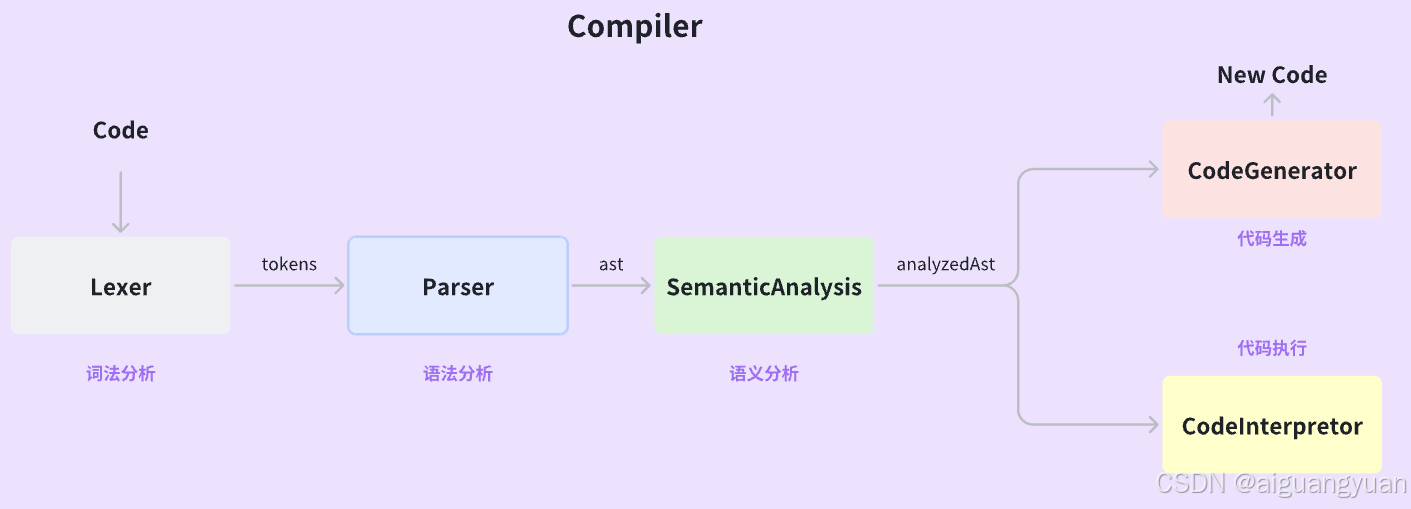
无论是传统编译器(如 C 语言编译器),还是现代前端工具链(如 Babel、Webpack),都遵循这一核心流程。理解这些步骤,不仅能帮助开发者更高效地调试代码,还能为自定义语言或工具开发奠定基础。
接下来,我们将详细解析每个阶段的技术原理和实现方法。
1. 编译过程
1.1. 词法分析
将源代码转换成单词流,称为"词法单元",每个词法单元包含一个标识符和一个属性值,比如变量名、数字、操作符等等。词法分析生成Token的方式主要有两种:
1.1.1. 正则
很多同学可能遇到字符串匹配的操作,自然就想到正则匹配。在普通场景下,正则用来做字符串匹配没什么问题,但如果是在编译器场景下,就很不合适,因为正则模式首先需要写大量的正则表达式,正则之间还有冲突需要处理,另外正则不容易维护,并且性能不高。
正则只适合一些简单的模板语法,真正复杂的语言并不合适。并且有的语言并不一定自带正则引擎。
1.1.2. 状态机
自动机可以很好的生成 token。
有穷状态自动机(finite state machine):在有限个输入的情况下,在这些状态中转移并期望最终达到终止状态。
有穷状态自动机根据确定性可以分为:
1. 确定有穷状态自动机(DFA - Deterministic finite automaton)
在输入一个状态时,只得到一个固定的状态,DFA 可以认为是一种特殊的 NFA。
2. 非确定有穷自动机(NFA - Non-deterministic finite automaton)
当输入一个字符或者条件得到一个状态机的集合,JavaScript 正则采用的是 NFA 引擎。
1.2. 语法分析
将词法单元流转换成抽象语法树(Abstract Syntax Tree,简称AST),也就是标记所构成的数据结构,表示源代码的结构和规则。
我们日常所说的编译原理就是将一种语言转换为另一种语言。编译原理被称为形式语言,它是一类无需知道太多语言背景、无歧义的语言。而自然语言通常难以处理,主要是因为难以识别语言中哪些是名词哪些是动词哪些是形容词。例如:“进口汽车”这句话,“进口”到底是动词还是形容词?所以我们要解析一门语言,前提是这门语言有严格的语法规定。
1956年,乔姆斯基将文法按照规范的严格性分为0型、1型、2型和3型共4种文法,从0到3文法规则是逐渐增加严的。一般的计算机语言是2型,因为0和1型文法定义宽松,将大大增加解析难度、降低解析效率,而3型文法限制又多,不利于语言设计灵活性。2型文法也叫做上下文无关文法(CFG)。
语法分析的目的就是通过词法分析器 拿到的 token 流 + 结合文法规则,通过一定算法得到一颗抽象语法树(AST)。抽象语法树是非常重要的概念,尤其在前端领域应用很广。典型应用如babel插件,它的原理就是:es6代码 → Babylon.parse → AST → babel-traverse → 新的AST → es5代码。
从生成AST效率和实现难度上,前人总结主要有2种解析算法:
1. 自顶向下的分析方法和自底向上的分析方法。自底向上算法分析文法范围广,但实现难度大;
2. 自顶向下算法实现相对简单,并且能够解析文法的范围也不错,所以一般的 compiler 都是采用深度优先索引的方式;
1.3. 代码转换
在AST上执行类型检查、作用域检查等操作,以确保代码的正确性和安全性。
在得到AST后,我们一般会先将AST转为另一种AST,目的是生成更符合预期的AST,这一步称为代码转换。
代码转换的优势主要是产生工程上的意义:
1. 易移植:与机器无关,所以它作为中间语言可以为生成多种不同型号的目标机器码服务;
2. 机器无关优化:对中间码进行机器无关优化,利于提高代码质量;
3. 层次清晰:将AST映射成中间代码表示,再映射成目标代码的工作分层进行,使编译算法更加清晰;
对于一个Compiler而言,在转换阶段通常有两种形式:
1. 同语言的AST转换;
2. AST 转换为新语言的 AST;
这里有一种通用的做法是,对我们之前的AST从上至下的解析,然后会有个映射表,把对应的类型做相应的转换。
1.4. 代码生成
基于AST生成目标代码,包括优化代码结构、生成代码文本、进行代码压缩等等。
在实际的代码处理过程中,可能会递归的分析我们最终生成的AST,然后对于每种 type 都有个对应的函数处理,实现思路用到的设计模式就是策略模式。
2. 完整链路
input => tokenizer => tokens; // 词法分析
tokens => parser => ast; // 语法分析,生成AST
ast => transformer => newAst; // 中间层代码转换
newAst => generator => output; // 生成目标代码3. 公式编译器实战
通过开发公式编译器与公式执行器,来进一步学习编译器的内容。
假设我们的语法诸如:
ADD(1, MINUS(3, 2))
Subtract(Add(3, Multiply(4, 2)), Divide(6, 2), 1)
3.1. 定义Token及分词器
定义Token如下:
const FN_NAME_TOKEN = /[a-zA-Z]/;
const NUMBER_TOKEN = /\d/;
const PAREN_TOKEN = /\(/;
const ATI_PAREN_TOKEN = /\)/;
const COMMA_TOKEN = /\,/;实现分词器 Tokenizer:
function tokenizer(expression) {
const tokens = [];
let current = 0;
while (current < expression.length) {
let char = expression[current];
// 先匹配数字
if (NUMBER_TOKEN.test(char)) {
let number = "";
// 一直往后找,直到不是数字为止
while (NUMBER_TOKEN.test(char)) {
number += char;
char = expression[++current];
}
// 将匹配到的 token 加入到 tokens 中
tokens.push({
type: "number",
value: parseInt(number),
});
continue;
}
// 匹配函数名
if (FN_NAME_TOKEN.test(char)) {
let fnName = "";
while (FN_NAME_TOKEN.test(char)) {
fnName += char;
char = expression[++current];
}
tokens.push({
type: "function",
value: fnName,
});
continue;
}
// 匹配括号和逗号
if (
PAREN_TOKEN.test(char) ||
ATI_PAREN_TOKEN.test(char) ||
COMMA_TOKEN.test(char)
) {
tokens.push({
type: char,
value: char,
});
current++;
continue;
}
// 处理空格
if (char === " ") {
current++;
continue;
}
throw new TypeError("I dont know what this character is: " + char);
}
return tokens;
}3.2. 实现Parser解析器
parser 根据生成的 token 流进行转换,转化为我们预先预定好的 ast,生成的 ast 可供后续代码转换生成或者公式内容执行用。
function parser(tokens) {
let current = 0;
// 递归解析
function walk() {
let token = tokens[current];
// 处理数字
if (token.type === "number") {
current++;
return {
type: "NumberLiteral",
value: token.value,
};
}
// 处理函数
if (token.type === "function") {
current++;
let node = {
type: "CallExpression",
name: token.value,
params: [],
};
token = tokens[++current];
// 一直循环往复的收集参数,知道遇到右括号位置
while (token.type !== ")") {
node.params.push(walk());
token = tokens[current];
// 注意一点,如果遇到了参数中间的逗号,也需要跳过
if (token.type === ",") {
current++;
}
}
current++; // 跳过右括号
return node;
}
throw new TypeError(token.type);
}
let ast = {
type: "Program",
body: [],
};
while (current < tokens.length) {
ast.body.push(walk());
}
return ast;
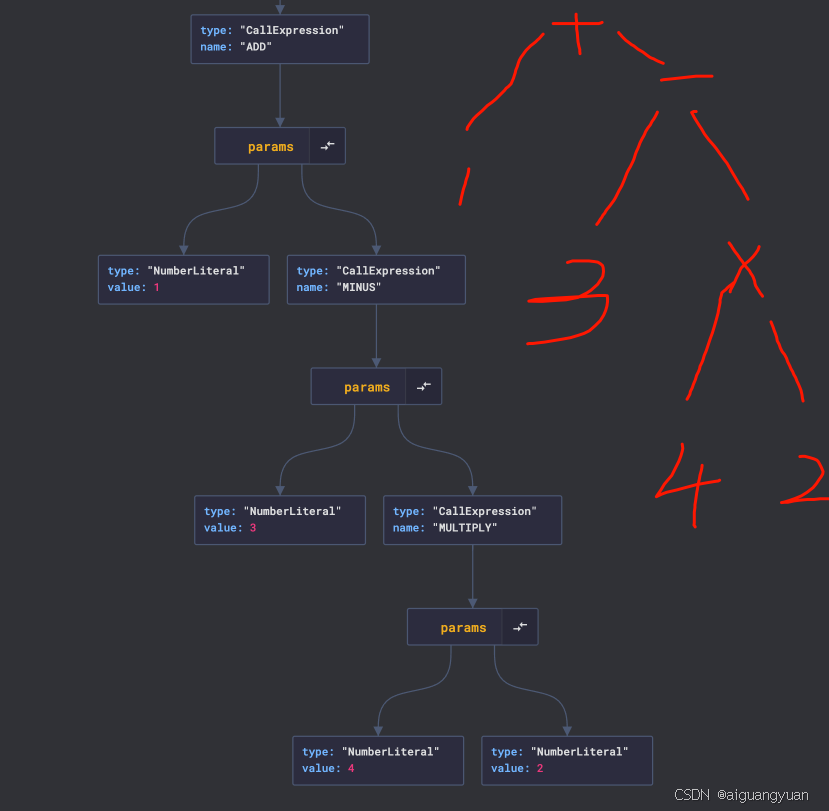
}用以上解析器解析如下公式:
ADD(1, MINUS(3, MULTIPLY(4, 2)))执行结果示意如下:
3.3. 定义执行器
根据ast,编写遍历节点需要执行的运算。
function interpret(ast) {
const operators = {
Add: (a, b) => a + b,
Subtract: (a, b, c) => a - b - c,
Multiply: (a, b) => a * b,
Divide: (a, b) => a / b,
};
function traverseNode(node) {
switch (node.type) {
case "NumberLiteral":
return node.value;
case "CallExpression":
const args = node.params.map(traverseNode);
const operator = operators[node.name];
if (!operator) {
throw new TypeError("Unknown function: " + node.name);
}
return operator(...args);
default:
throw new TypeError(node.type);
}
}
return traverseNode(ast.body[0]);
}3.4. 解析输入的公式
const expression = "Subtract(Add(3, Multiply(4, 2)), Divide(6, 2), 1)";
const tokens = tokenize(expression);
const ast = parse(tokens);
const result = interpret(ast);
console.log(result);其实可以优化的点有很多,主要包括:
1. 将运算功能设计为插件,通过插件注册方式拓展运算功能;
2. 支持预设变量,在公式进行计算时,把预设变量对应值一起进行计算;
3.5. 最终完整代码
// 定义 token 类型
const FN_NAME_TOKEN = /[a-zA-Z]/;
const NUMBER_TOKEN = /\d/;
const PAREN_TOKEN = /\(/;
const ATI_PAREN_TOKEN = /\)/;
const COMMA_TOKEN = /\,/;
// 定义 tokenizer 函数,将表达式转换为 token 数组
function tokenizer(expression) {
const tokens = [];
let current = 0;
while (current < expression.length) {
let char = expression[current];
// 先匹配数字
if (NUMBER_TOKEN.test(char)) {
let number = "";
// 一直往后找,直到不是数字为止
while (NUMBER_TOKEN.test(char)) {
number += char;
char = expression[++current];
}
// 将匹配到的 token 加入到 tokens 中
tokens.push({
type: "number",
value: parseInt(number),
});
continue;
}
// 匹配函数名
if (FN_NAME_TOKEN.test(char)) {
let fnName = "";
while (FN_NAME_TOKEN.test(char)) {
fnName += char;
char = expression[++current];
}
tokens.push({
type: "function",
value: fnName,
});
continue;
}
// 匹配括号和逗号
if (
PAREN_TOKEN.test(char) ||
ATI_PAREN_TOKEN.test(char) ||
COMMA_TOKEN.test(char)
) {
tokens.push({
type: char,
value: char,
});
current++;
continue;
}
// 处理空格
if (char === " ") {
current++;
continue;
}
throw new TypeError("I dont know what this character is: " + char);
}
return tokens;
}
// 定义 parser 函数,将 token 数组转换为 AST
function parser(tokens) {
let current = 0;
// 递归解析
function walk() {
let token = tokens[current];
// 处理数字
if (token.type === "number") {
current++;
return {
type: "NumberLiteral",
value: token.value,
};
}
// 处理函数
if (token.type === "function") {
current++;
let node = {
type: "CallExpression",
name: token.value,
params: [],
};
token = tokens[++current];
// 一直循环往复的收集参数,知道遇到右括号位置
while (token.type !== ")") {
node.params.push(walk());
token = tokens[current];
// 注意一点,如果遇到了参数中间的逗号,也需要跳过
if (token.type === ",") {
current++;
}
}
current++; // 跳过右括号
return node;
}
throw new TypeError(token.type);
}
let ast = {
type: "Program",
body: [],
};
while (current < tokens.length) {
ast.body.push(walk());
}
return ast;
}
// 定义 transformer 函数,将 AST 转换为新的 AST
function interpret(ast) {
const operators = {
Add: (a, b) => a + b,
Subtract: (a, b, c) => a - b - c,
Multiply: (a, b) => a * b,
Divide: (a, b) => a / b,
};
function traverseNode(node) {
switch (node.type) {
case "NumberLiteral":
return node.value;
case "CallExpression":
const args = node.params.map(traverseNode);
const operator = operators[node.name];
if (!operator) {
throw new TypeError("Unknown function: " + node.name);
}
return operator(...args);
default:
throw new TypeError(node.type);
}
}
return traverseNode(ast.body[0]);
}
// 解析运算表达式
const expression = "Subtract(Add(3, Multiply(4, 2)), Divide(6, 2), 1)";
const tokens = tokenize(expression);
const ast = parse(tokens);
const result = interpret(ast);
console.log(result);
4. 补充资料
ast 查看器:AST explorer
强大的 parser 生成器:ANTLR
官方 babel ast 结构:babel/packages/babel-parser/ast/spec.md at main · babel/babel · GitHub
v8 优化编译器:https://v8.dev/blog/maglev
Chromium V8:https://chromium.googlesource.com/v8/v8.git
the-super-tiny-compiler:GitHub - jamiebuilds/the-super-tiny-compiler: :snowman: Possibly the smallest compiler ever
Babel 可选链语法插件:babel/packages/babel-plugin-transform-optional-chaining at main · babel/babel · GitHub opt?.name



















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











