







参考《收获,不止SQL优化》作者: 梁敬彬 / 梁敬弘
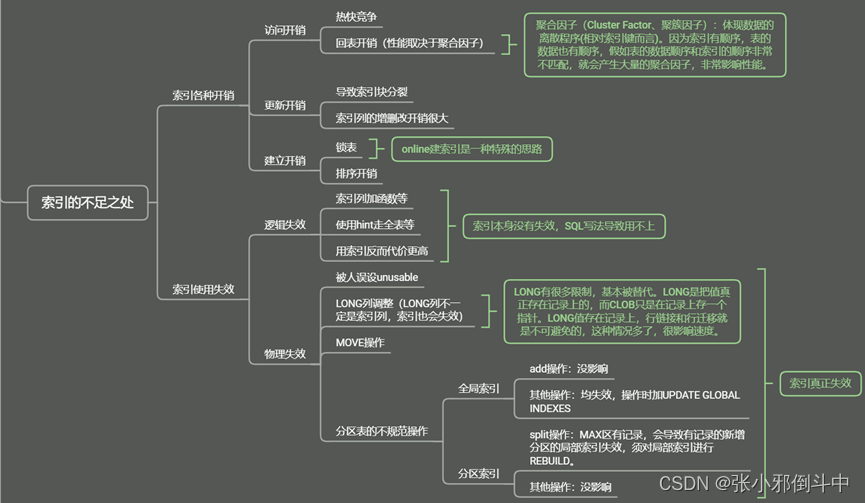
一、 索引的不足之处
二、 索引的取舍

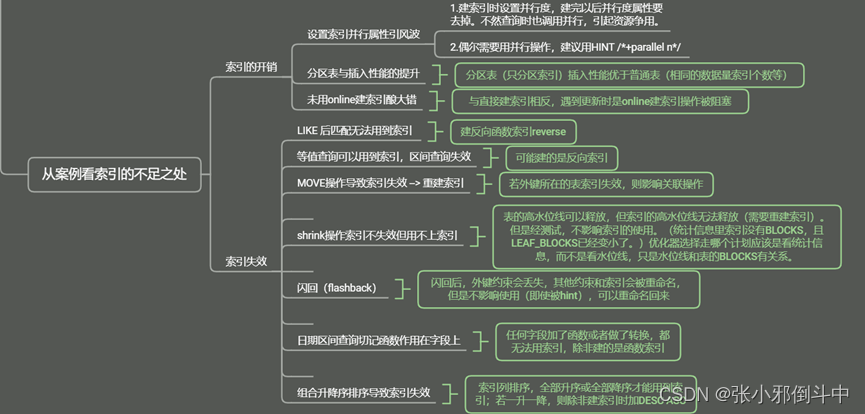
三、 结合案例
四、 习题

习题1:
(1) SQL写法导致:列上加函数、列隐式类型转换、HINT固定全表扫描
(2) SQL写法没问题,但是优化器考虑到回表认为走索引代价更大,不如直接全表扫描
习题2:
索引失效:
(1)分区表:除了ADD,其他分区操作会导致全局索引失效;MAX分区有值用了SPLIT会导致分区索引失效
(2)MOVE操作后没有重建索引
(3)表中有LONG字段类型,后对该字段类型做了修改,会导致该表的索引失效
(4)人工误设UNUSABLE
索引丢失:
闪回操作(其实也没有丢失,只是被系统重命名了)
习题3:
数据插入时,除了往数据表里插入数据,每个索引树也都会插入数据(只要索引序列不为空)。而往索引树插入数据时必须有序,就会产生排序、块分裂等其他的一些开销。从而影响插入性能。
习题4:
(1)、检查失效的索引
(2)、检查(A,B)(A)这种索引,合并
(3)、检查索引列过多的索引(>4)
(4)、检查一段时间不用的索引














 45
45











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









